微调Qwen2.5-coder,只用GRPO!打造能“懂你时间表”的AI工具人!
2025年,随着DeepSeek热潮平场应该说是被GRPO热到爆,每个AI实战环节上的工程师都在试图用GRPO训练自己的推理模型:
“不用表标、不用表达式,只用“提示 + 奖励”也能教会模型学习。”
相比于传统的SFT (直接依靠补全给模型打样),GRPO (奖励引导提示优化)更近于一种“工程师思维”:按红线奖励模型,运行一组prompt解题,按解出结果算分,给出一个指定的reward,重新进行prompt优化。

网上最多的案例,都是用GRPO训练GSM8K类的数学算法题,或者“Countdown Game”通关玩法,我想玩点新鲜的。
我的初始热情来自一个简单的创意:
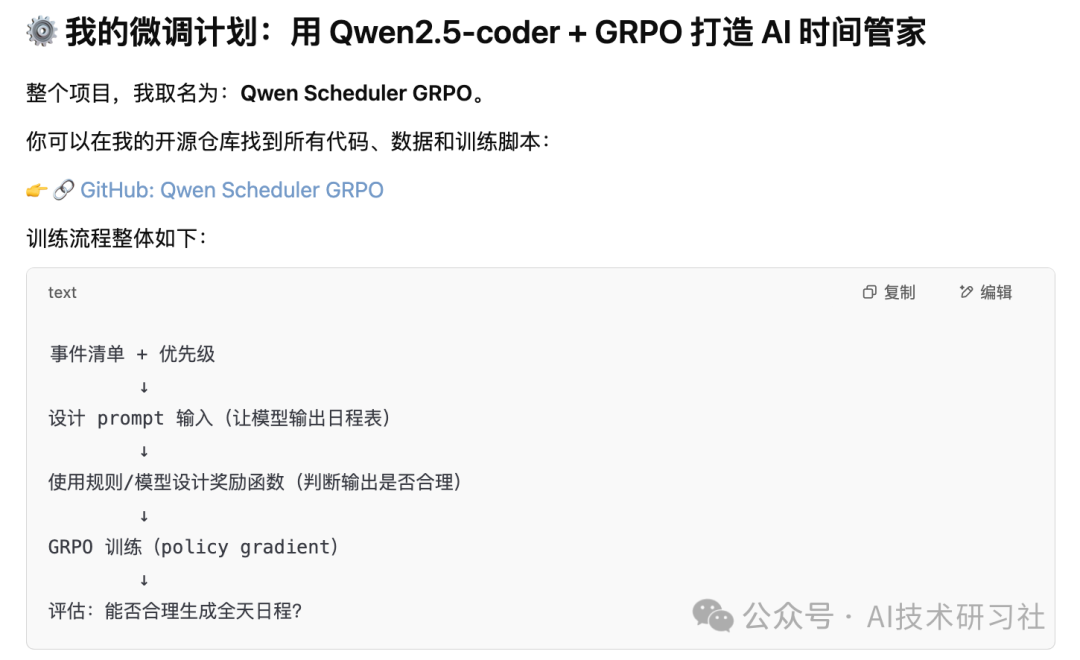
能不能让大模型,根据一些“事件列表+优先级”,自动生成一个日程表?
在初步试验中,ChatGPT类的大模型基本能接近解决问题,但是下14B的小型模型基本一脱装就不行了,这也让我更有励气应用GRPO通过prompt奖励应用小型模型学会“算日程”这件事。
但是,我没有想到的是:一个简单的创意题目,会拉出一整套工程化思维过程:自行设计prompt输入格式,生成训练数据,选择基础模型,设计奖励函数,进行多轮微调训练。
所有代码和实践我都放在了以下项目,可以看到如何训练领域特定模型,使用 GRPO 微调了 qwen2.5-coder-7B, 实现了一个生成日程表的大模型。并且不光有教程,还有代码,模型。感兴趣的同学可以参考这个学习。
教程地址:huggingface.co/blog/anakin87/qwen-scheduler-grpo
代码地址:github.com/anakin87/qwen-scheduler-grpo
模型地址:huggingface.co/anakin87/qwen-scheduler-7b-grpo

下面我将从以下几个方面,完整解析我如何用GRPO微调Qwen2.5-coder,打造一个能识别优先级和时间空间的日程定制AI。




from unsloth import FastLanguageModel max_seq_length = 2048 lora_rank = 32 model, tokenizer = FastLanguageModel.from_pretrained( model_name = "Qwen/Qwen2.5-Coder-7B-Instruct", max_seq_length = max_seq_length, load_in_4bit = True, fast_inference = True, max_lora_rank = lora_rank, gpu_memory_utilization = 0.85, # Reduce if out of memory ) model = FastLanguageModel.get_peft_model( model, r = lora_rank, target_modules = [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], # Remove QKVO if out of memory lora_alpha = lora_rank, use_gradient_checkpointing = "unsloth", # Enable long context finetuning random_state = 3407,)
如果你的 VRAM 小于 48GB,你可以调整几个参数: gpu_memory_utilization 、 lora_rank 和 target_modules ;后两个参数会影响你的模型能学习多少。
对数据集进行预处理,添加一般任务描述和说明,以系统消息和用户消息的形式。
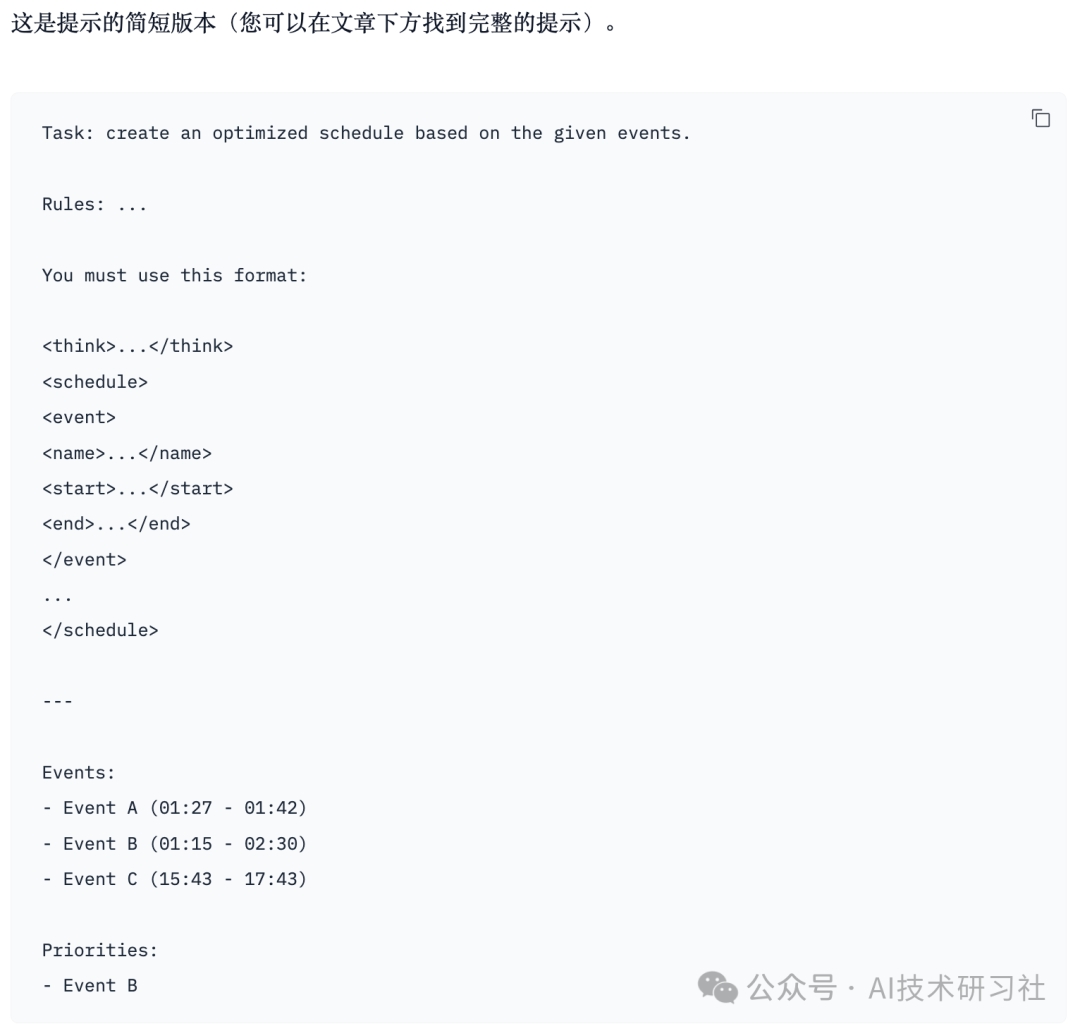
import datasets SYSTEM_PROMPT = """You are a precise event scheduler. 1. First, reason through the problem inside <think> and </think> tags. Here you can create drafts, compare alternatives, and check for mistakes. 2. When confident, output the final schedule inside <schedule> and </schedule> tags. Your schedule must strictly follow the rules provided by the user.""" USER_PROMPT ="""Task: create an optimized schedule based on the given events. Rules: - The schedule MUST be in strict chronological order. Do NOT place priority events earlier unless their actual start time is earlier. - Event start and end times are ABSOLUTE. NEVER change, shorten, adjust, or split them. - Priority events (weight = 2) carry more weight than normal events (weight = 1), but they MUST still respect chronological order. - Maximize the sum of weighted event durations. - No overlaps allowed. In conflicts, include the event with the higher weighted time. - Some events may be excluded if needed to meet these rules. You must use this format: <think>...</think> <schedule> <event> <name>...</name> <start>...</start> <end>...</end> </event> ... </schedule> --- """ ds = datasets.load_dataset("anakin87/events-scheduling", split="train") ds = ds.map( lambda x: { "prompt": [ {"role": "system", "content": SYSTEM_PROMPT}, {"role": "user", "content": USER_PROMPT + x["prompt"]}, ] } )
GRPO 是一种强化学习算法,对于每个提示,模型会生成多个样本(在我们的案例中是 8 个)。在训练过程中,模型的参数会更新以生成高奖励的响应。
import re overall_pattern = (r"<think>.+</think>.*<schedule>.*(<event>.*<name>.+</name>.*<start>\d{2}:\d{2}</start>.*" r"<end>\d{2}:\d{2}</end>.*</event>)+.*</schedule>") overall_regex = re.compile(overall_pattern, re.DOTALL) def format_reward(prompts, completions, **kwargs): responses = [completion[0]['content'] for completion in completions] return [0.0 if not overall_regex.match(response) else 10.0 for response in responses]
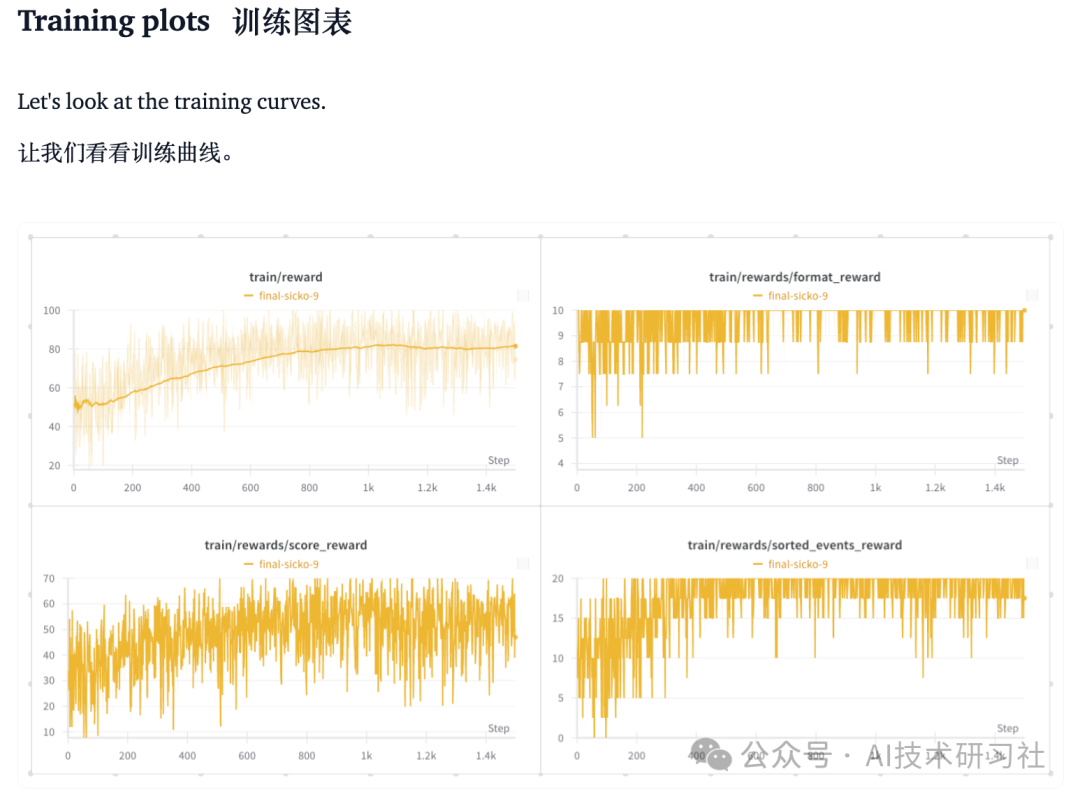
最终使用了一个奖励函数来鼓励产生按时间顺序排列的日程安排,另一个奖励函数用来最大化分数。如你所见,我试图在这两个奖励函数中包含并优先考虑其他要求。
def sorted_events_reward(completions, **kwargs): scores = [] responses = [completion[0]['content'] for completion in completions] for response in responses: scheduled_events = get_events(response) # not a valid schedule: should be discarded if len(scheduled_events) < 2: scores.append(0.0) continue scheduled_events_minutes = [(ev[0], time_to_minutes(ev[1]), time_to_minutes(ev[2])) for ev in scheduled_events] if all(scheduled_events_minutes[i][1] < scheduled_events_minutes[i+1][1] for i in range(len(scheduled_events_minutes)-1)): scores.append(20.0) else: scores.append(0) return scores def score_reward(prompts, completions, events, priority_events, optimal_score, **kwargs): scores = [] responses = [completion[0]['content'] for completion in completions] for content, valid_events, priorities, opt_score in zip(responses, events, priority_events, optimal_score): scheduled_events = get_events(content) # Get valid scheduled events existing_events = {ev for ev in scheduled_events if [ev[0], ev[1], ev[2]] in valid_events} # penalize choosing nonexistent events or less than 2 events (not a valid schedule) if len(existing_events)<len(scheduled_events) or len(existing_events) < 2: scores.append(0.0) continue # Convert to minutes existing_events_minutes = [(ev[0], time_to_minutes(ev[1]), time_to_minutes(ev[2])) for ev in existing_events] # remove overlapping events and remove both events - to penalize overlaps overlapping_events = set() for j in range(len(existing_events_minutes)): for k in range(j + 1, len(existing_events_minutes)): if (existing_events_minutes[j][1] <= existing_events_minutes[k][2] and existing_events_minutes[j][2] >= existing_events_minutes[k][1]): overlapping_events.add(existing_events_minutes[j]) overlapping_events.add(existing_events_minutes[k]) existing_events_minutes = [ev for ev in existing_events_minutes if ev not in overlapping_events] # Calculate score score = sum(2 * (ev[2] - ev[1]) if ev[0] in priorities else ev[2] - ev[1] for ev in existing_events_minutes) scores.append((score/opt_score) * 70) return scores
from trl import GRPOConfig, GRPOTrainer tokenized_prompts = [tokenizer.apply_chat_template(prompt, tokenize=True, add_generation_prompt=True) for prompt in ds['prompt']] exact_max_prompt_length = max([len(tokenized_prompt) for tokenized_prompt in tokenized_prompts]) max_prompt_length = 448 # manually adjusted new_model_id="anakin87/qwen-scheduler-7b-grpo" training_args = GRPOConfig( learning_rate = 8e-6, adam_beta1 = 0.9, adam_beta2 = 0.99, weight_decay = 0.1, warmup_ratio = 0.01, lr_scheduler_type = "cosine", optim = "paged_adamw_8bit", logging_steps = 1, per_device_train_batch_size = 8, gradient_accumulation_steps = 1, num_generations = 8, # Decrease if out of memory max_prompt_length = max_prompt_length, max_completion_length = max_seq_length - max_prompt_length, max_grad_norm = 0.1, output_dir = "outputs", overwrite_output_dir = True, push_to_hub = True, hub_model_id=new_model_id, hub_strategy="every_save", save_strategy="steps", save_steps=50, save_total_limit=1, num_train_epochs=3, ) trainer = GRPOTrainer( model = model, processing_class = tokenizer, reward_funcs=[ format_reward, sorted_events_reward, score_reward, ], args = training_args, train_dataset = ds, ) trainer.train()

最后,我也会分享如何通过此类原创实践项目,教会大模型识别环境、理解系统性思维、练习数据结构设计等AI工程核心能力。
参考:https://huggingface.co/blog/anakin87/qwen-scheduler-grpo
📌 如果你对实操性强、可复现、整套代码公开的GRPO+大模型项目感兴趣,那就不要错过我的这段实战经验!
喜欢这类干货?点个“在看”吧,让更多人看到!
也欢迎留言交流你训练 AI 助理的奇思妙想👇
(文:AI技术研习社)
相关文章







