NVIDIA发布Nemotron 3超级模型:一款具有120亿参数的开源混合Mamba-Attention MoE模型,为代理AI提供5倍更高的吞吐量。
热衷于专有前沿模型和高度透明开源模型之间的差距正在前所未有地快速缩小。NVIDIA正式揭开了Nemotron 3 Super的面纱,这是一个工程设计用于复杂多代理应用的120亿参数推理模型。
今天发布,Nemotron 3 Super完美地介于轻量级的30亿参数Nemotron 3 Nano和备受期待的500亿参数Nemotron 3 Ultra之间,该Ultra将于2026年后推出。这款模型提供的吞吐量比上一代产品提高了高达7倍,准确率翻倍,对于拒绝在智能和推理效率之间妥协的开发者来说,这是一个巨大的飞跃。
Nemotron 3 Super的“五个奇迹”
Nemotron 3 Super无与伦比的性能得益于五大技术创新:
- 混合MoE架构:该模型智能地结合了内存高效的Mamba层和高精度的Transformer层。通过只激活一小部分参数来生成每个标记,它实现了KV和SSM缓存使用效率的4倍增加。
- 多标记预测(MTP):该模型可以同时预测多个未来的标记,在复杂的推理任务上实现了3倍的推理速度。
- 一百万个上下文窗口:与前一代相比,上下文长度增加7倍,开发人员可以直接将大量技术报告或整个代码库直接放入模型的内存中,消除在多步骤工作流程中重新推理的需要。
- 潜在MoE:这使得模型能够压缩信息并激活四个专家,使得计算成本与e上一样,否则该模型需要大35倍才能达到相同的准确度。
- NeMo RL Gym集成:通过交互式强化学习管道,模型从动态反馈循环中学习,而不仅仅是静态文本,这有效地将其智能指数翻倍。
所有这些突破,都使输出令牌每GPU的效率达到了不可思议的水平
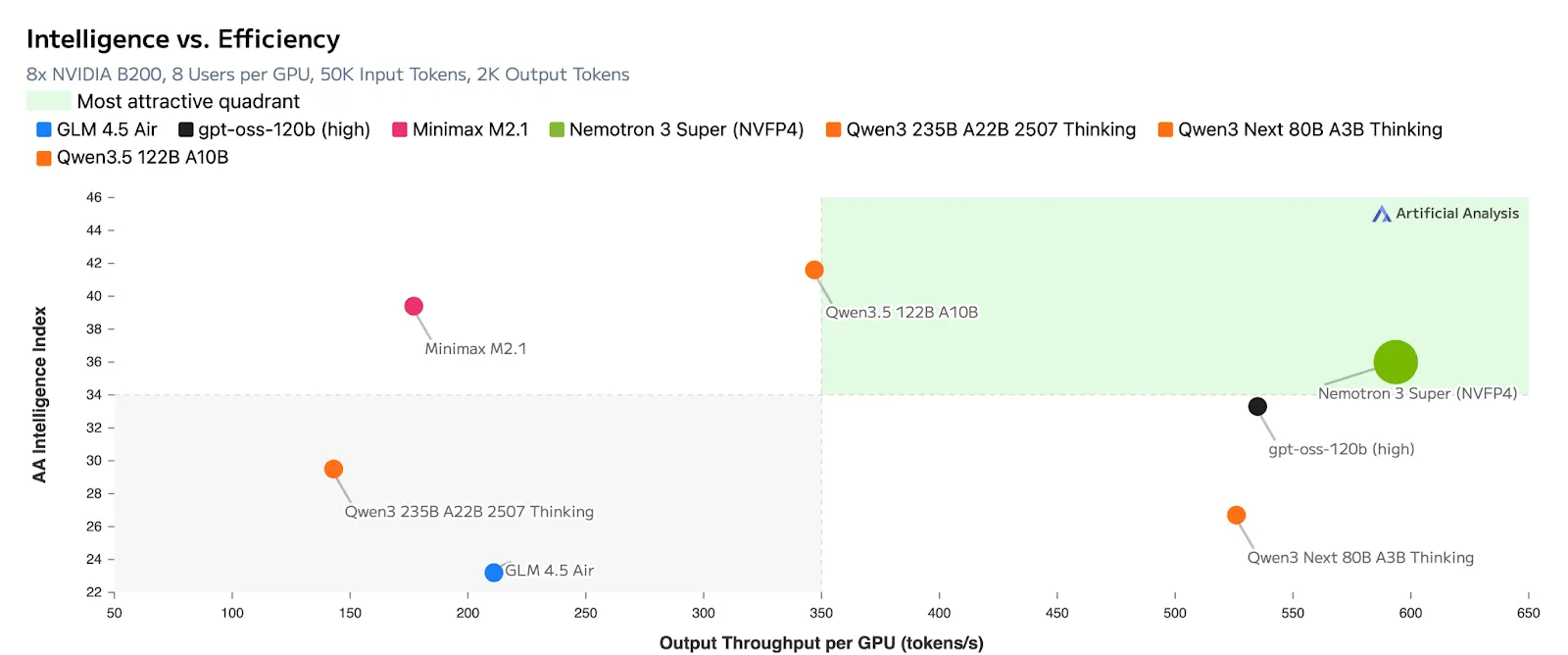
为什么Nemotron 3 Super是多代理AI的终极引擎?
Nemotron 3 Super不仅是标准的大型语言模型;它特意定位为推理引擎,旨在规划、验证和执行更广泛的系统专建模的复杂任务。以下是其架构为何使其成为多代理工作流变革者的确切原因:
- 高吞吐量支持更深层次的推理:该模型7倍更高的吞吐量物理上扩展了其搜索空间。因为它可以更快地处理和生成标记,所以它可以探索更长的轨迹,并评估更好的响应。这允许开发人员以相同的计算预算进行更深入的推理,这对于构建复杂的自主代理至关重要。
- 长工作流程中无需“重新推理”:在多代理系统中,代理不断传递上下文。一百万个标记的上下文窗口允许模型保留大量状态,例如整个代码库或长的、多步骤的代理对话历史,直接进入其内存中。这消除了在每个单独步骤中要求模型重新处理上下文的不必要延迟和成本。
- 代理特定的训练环境:该模型的管道扩展了超过15个交互式强化学习环境,而不仅仅依赖于静态文本数据集。通过在动态仿真循环中(例如为软件工程代理和工具辅助搜索提供的专用环境)进行训练,Nemotron 3 Super学习了自主任务完成的最佳轨迹。
- 高级工具调用功能:在实际的多代理应用中,模型需要采取行动,而不仅仅是文本性响应。开箱即用,Nemotron 3 Super已被证明在工具调用方面非常精通,在复杂的网络安全工作流程中成功导航大量可用的函数——例如,在动态选择超过100种不同工具时。
开源和训练规模
NVIDIA不仅发布了权重;他们甚至完全开源了该模型的所有堆栈,包括训练数据集、库和强化学习环境。
正是因为这种透明度,人工分析将Nemotron 3 Super明确地定位在“最有吸引力”的四分之一中,指出它在实现最高开放度的同时,与专有模型保持了领先的准确性。这种智能的基础完全来自于一个彻底重新设计的管道,在10万亿精选标签上进行了训练,此外还有额外90至100亿个严格针对高级编码和推理任务的标签。

开发者控制:介绍“推理预算”
虽然原始参数计数和基准分数令人印象深刻,但NVIDIA团队了解,现实世界的企业开发人员需要精确地控制延迟、用户体验和计算成本。为了解决经典智能与速度之间的困境,Nemotron 3 Super通过它的API直接引入了高度灵活的推理模式,将前所未有的细分控制掌握在开发者手中。
开发人员可以根据具体的任务动态调整模型“思考”的难易程度:
- 全推理(默认):模型被得到充分释放,以利用其最大能力,探索深层搜索空间和多个步骤的轨迹,以解决最复杂、最具代理性的问题。
- “推理预算”:这是对延迟敏感应用的突破性创新。开发者可以明确限制模型思维的时长或计算许可额。通过设置严格的推理预算,模型智能地优化其内部搜索空间,在确切的约束下提供最佳可能的答案。
- “低努力模式”:并非每个提示都需要深层、多代理分析。当用户只需要简单、简洁的答案(如标准摘要或基本问答)时,而不需要深层推理的附加开销,此开关将Nemotron 3 Super变成一个闪电般的响应者,节约大量计算和时间。
“黄金”配置
调整推理模型可能是一个令人沮丧的过程,需要进行反复试验,但NVIDIA团队已经完全消除了这一发布中的神秘感。为了在所有这些动态模式中提取最佳性能,NVIDIA建议全球配置为温度1.0和Top P 0.95。
据NVIDIA团队称,锁定这些确切的超参数设置 确保 模型在限制的低努力模式下或无限制的深层推理中,都能保持创造性的探索和逻辑精确之间的完美数学平衡。
现实世界应用和可用性
Nemotron 3 Super已在需求严格的企业应用中证明了自己的实力:
- 软件开发:它处理初级级别的拉取请求,并成功在问题定位方面超越领先的专有模型,成功地找到导致错误的确切行代码。
- 网络安全:该模型擅长使用其高级工具调用逻辑在复杂的网络安全ISV工作流程中导航。
- 主权AI:全球的印度、越南、韩国和欧洲等地区组织正在使用Nemotron架构构建针对特定地区和监管框架的专用本地模型。
Nemotron 3 Super 以BF16、FP8和NVFP4量化形式发布,在DGX Spark上运行该模型需要NVFP4。
查看[Hugging Face](https://pxllnk.co/ctqnna8)上的模型。您可以在**[研究论文**](https://pxllnk.co/ml2920c)和**[技术/开发者博客**](https://pxllnk.co/lbmkemm)上找到详细信息。
感谢NVIDIA AI团队为此文章的思考领导力和资源。NVIDIA AI团队支持并赞助了此内容/文章。
原文链接:NVIDIA 发布 Nemotron 3 Super:一款 120B 参数的开源混合 Mamba-Attention MoE 模型,为代理AI提供 5 倍更高的吞吐量,首次出现在 MarkTechPost。
相关文章







