让 AI 图像处理变得简单而强大Gemini Image App,现代化的全栈 AI 图像处理平台
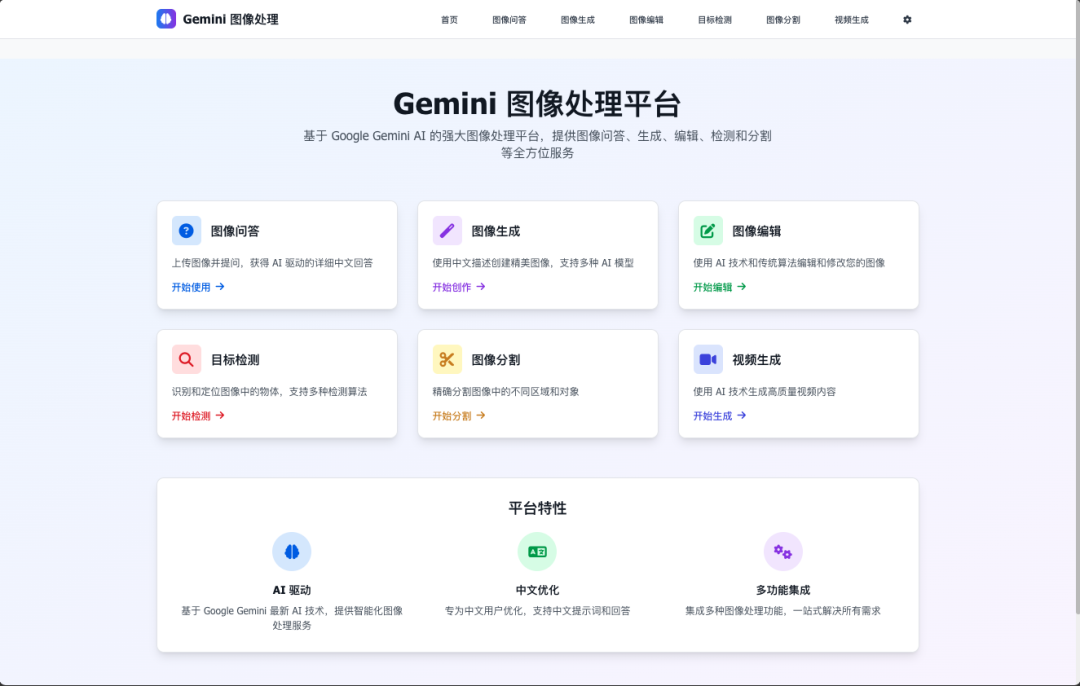
基于 Google Gemini AI 的全功能图像处理应用
一个现代化的全栈 AI 图像处理平台,集成了 Google Gemini、OpenCV 和 YOLO 等先进技术,提供图像问答、生成、编辑、目标检测、图像分割和视频生成等功能。
✨ 核心功能
🤖 智能图像问答
- 多语言支持:中文提问,智能回答
- 深度理解:基于 Gemini 2.0 Flash 视觉模型
- 上下文分析:理解图像内容、场景和细节
- 模型选择:支持多种 Gemini 模型切换
🎨 AI 图像生成
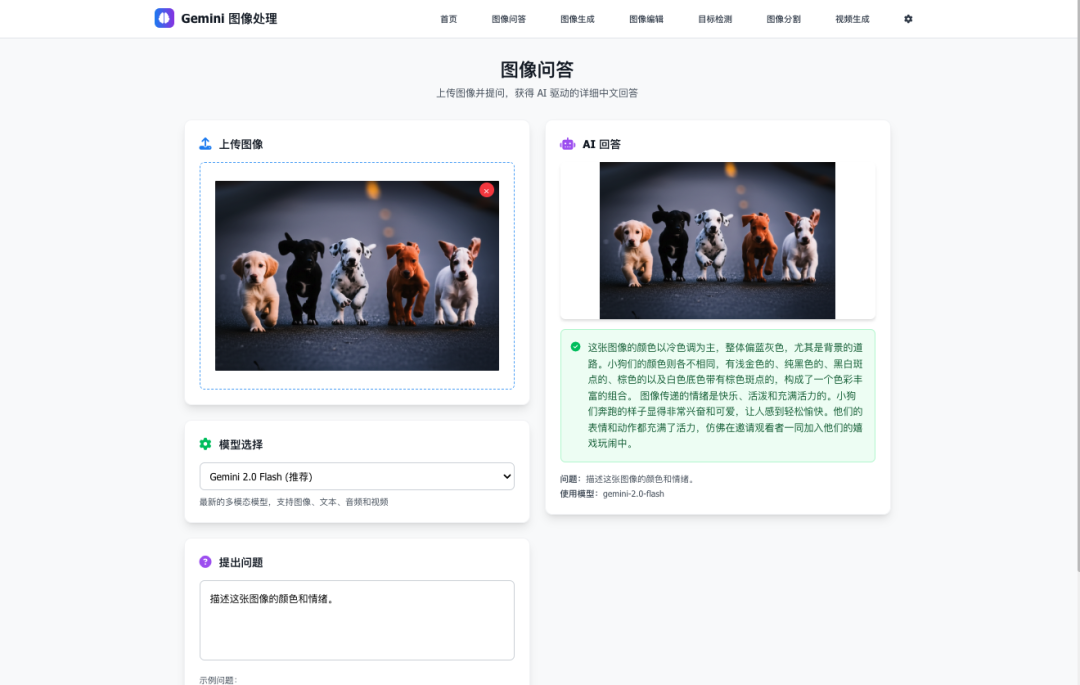
- 双引擎支持:
- Imagen 3 – 照片级高质量图像生成
- Gemini 2.0 Flash – 快速创意图像生成
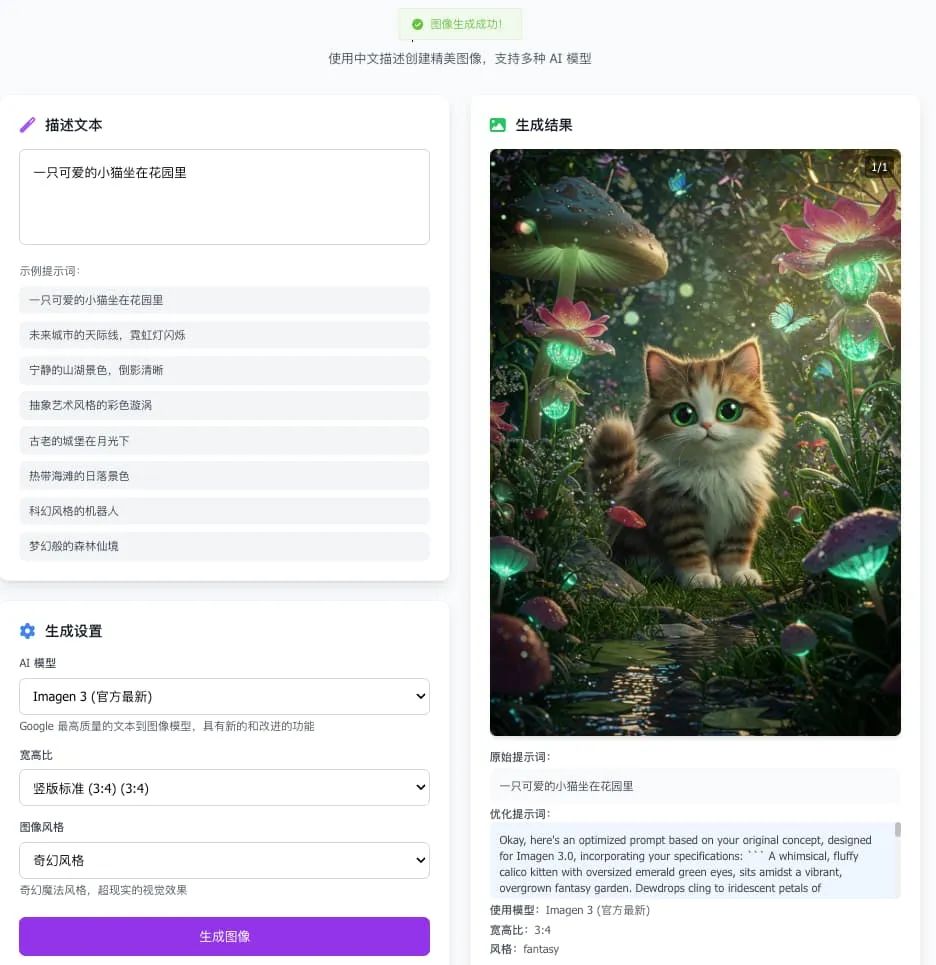
- 智能翻译:中文提示词自动翻译优化
- 动态模型:实时获取最新可用模型
- 批量生成:支持多张图像同时生成
✏️ 智能图像编辑
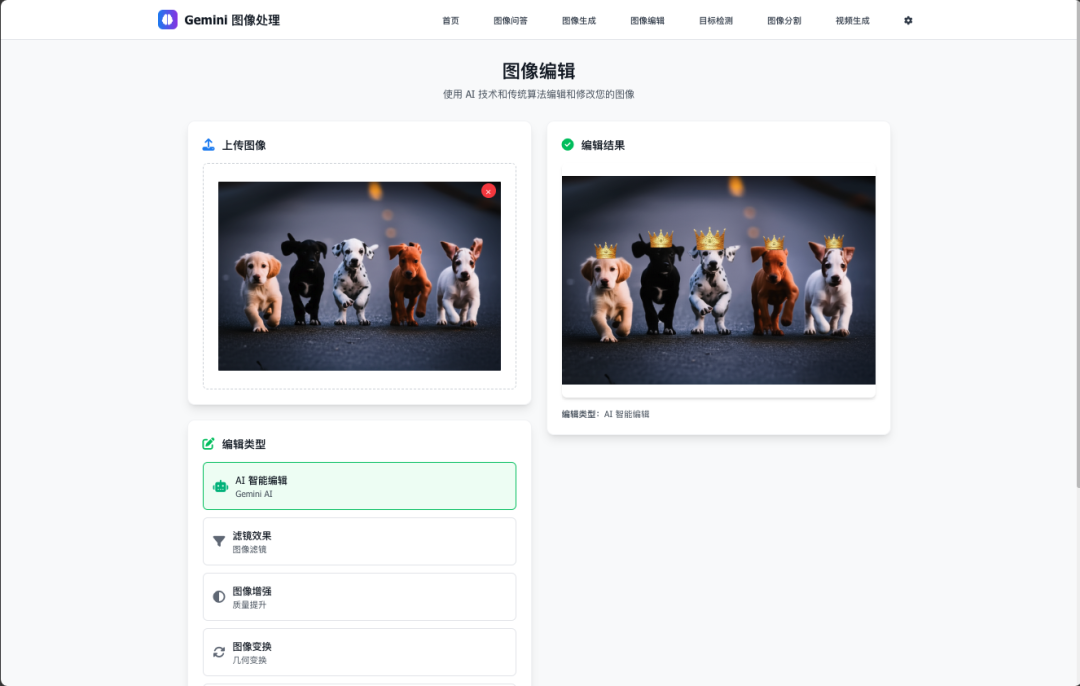
- AI 驱动编辑:自然语言描述编辑需求
- 多种编辑模式:修复、增强、风格转换
- 实时预览:编辑结果即时显示
- 历史记录:编辑步骤可回溯
🎯 多算法目标检测
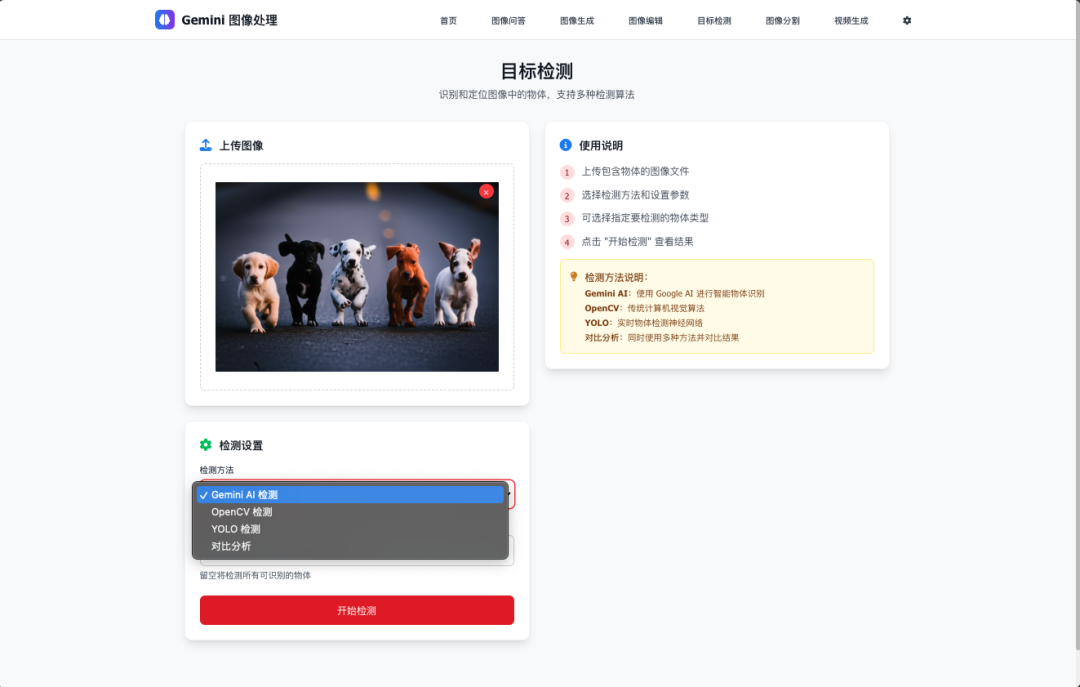
- 三重检测引擎:
- Gemini AI – 智能语义检测
- OpenCV – 传统计算机视觉
- YOLO v11 – 实时神经网络检测
- 对比分析:三种算法结果并排比较
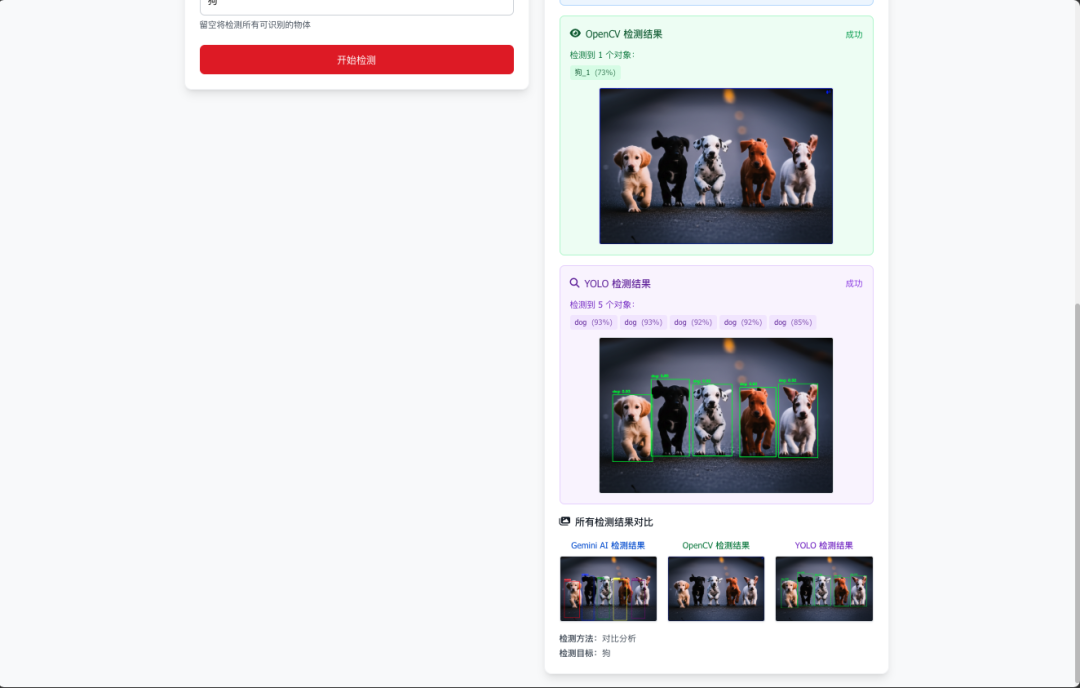
- 内容验证:智能匹配用户查询与图像内容
- 可视化结果:边界框、置信度、汇总图像
🔍 精确图像分割
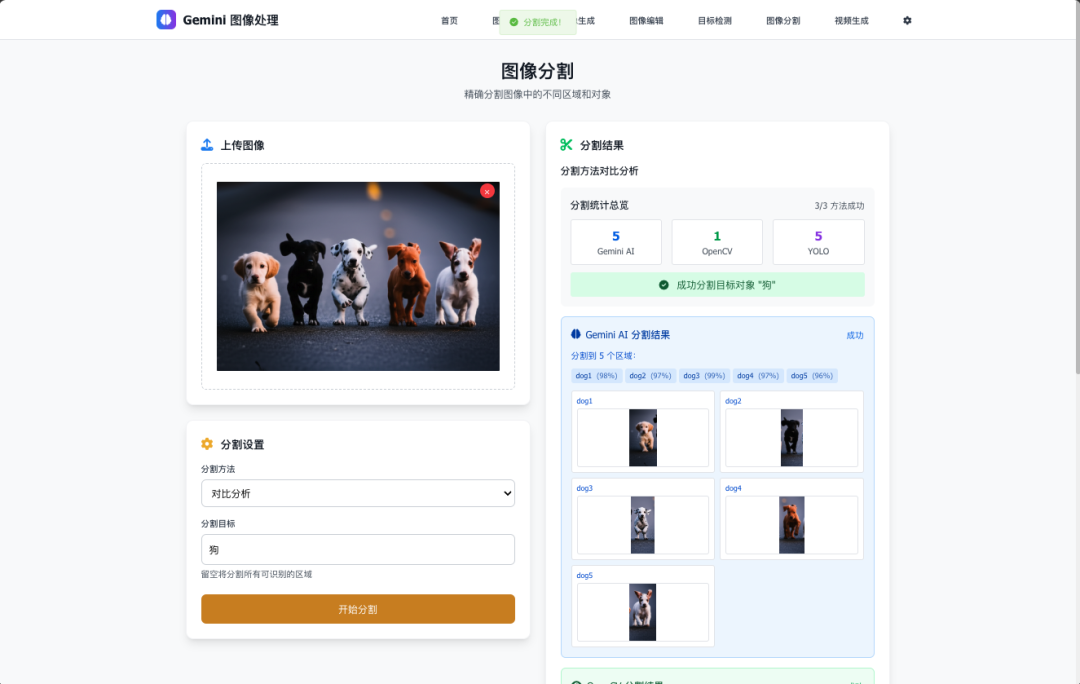
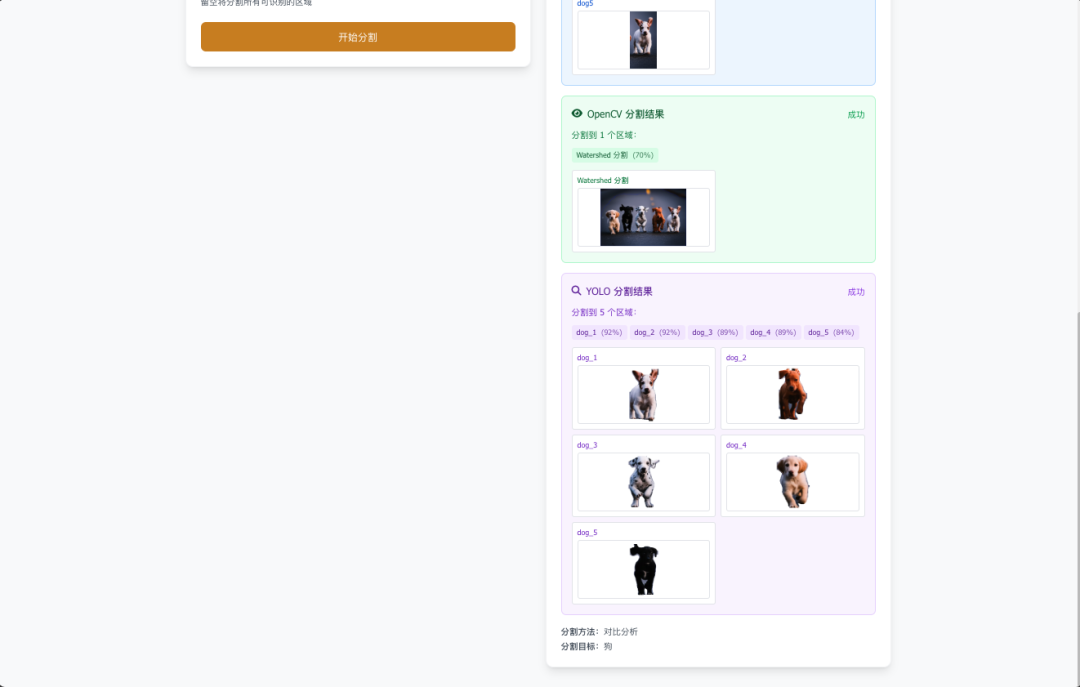
- 像素级精度:精确的对象轮廓分割
- 多算法支持:Gemini、OpenCV、YOLO 分割
- 实例分割:区分同类对象的不同实例
- 完整对象显示:分割结果保持对象完整性
- 对比分析:多种分割方法效果对比
🎬 AI 视频生成
- 文本到视频:根据描述生成视频内容
- 提示词优化:自动优化生成效果
- Veo 2.0 引擎:使用最新的视频生成模型
- 进度跟踪:实时显示生成进度
🛠️ 技术架构
🔧 后端技术栈
- Flask 3.0+ – 现代化 Web 框架
- google-genai 1.16.1 – 最新 Gemini AI SDK
- OpenCV 4.x – 计算机视觉库
- Ultralytics YOLO v11 – 最新目标检测模型
- Pillow (PIL) – 图像处理库
- Python 3.8+ – 运行环境
🎨 前端技术栈
- Vue.js 3 – 渐进式 JavaScript 框架
- Vite – 快速构建工具
- TailwindCSS – 原子化 CSS 框架
- Element Plus – Vue 3 组件库
- Font Awesome – 图标库
- 响应式设计 – 移动端适配
🤖 AI 模型集成
- Gemini 2.0 Flash – 多模态理解和生成
- Imagen 3 – 高质量图像生成
- Veo 2.0 – 视频生成模型
- YOLO v11 – 实时目标检测和分割
- OpenCV – 传统计算机视觉算法
🏗️ 架构特点
- 模块化设计 – 清晰的代码组织结构
- 服务分离 – 业务逻辑与API分离
- 多算法支持 – 同一功能多种实现方案
- 配置驱动 – 灵活的环境配置管理
- 错误处理 – 完善的异常处理机制
🚀 快速开始
📋 环境要求
- Python 3.8+
- Node.js 16+ (用于前端开发)
- Git (版本控制)
- Google AI API Key (必需)
1️⃣ 克隆项目
ounter(lineounter(line git clone https://github.com/yourusername/gemini-image-app.git cd gemini-image-app
2️⃣ 后端设置
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 进入后端目录 cd backend # 创建虚拟环境 (推荐) python -m venv .venv source .venv/bin/activate # Linux/Mac # 或 .venv\Scripts\activate # Windows # 安装依赖 pip install -r requirements.txt
3️⃣ 前端设置
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 进入前端目录 cd frontend # 安装依赖 npm install # 启动开发服务器 npm run dev
4️⃣ 环境配置
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 复制环境变量模板 cp .env.example .env # 编辑 .env 文件,添加您的 API 密钥 GOOGLE_API_KEY=your_google_ai_api_key_here GEMINI_API_KEY=your_google_ai_api_key_here SECRET_KEY=your_random_secret_key_here
🔑 获取 API 密钥: 访问 Google AI Studio 获取免费的 API 密钥
5️⃣ 启动应用
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 启动后端服务 (端口 5000) cd backend python run.py # 启动前端服务 (端口 3000) cd frontend npm run dev
6️⃣ 访问应用
- 前端界面: http://localhost:3000
- 后端API: http://localhost:5000
🎉 恭喜! 您的 Gemini Image App 已经运行起来了!
📁 项目结构
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line gemini-image-app/ ├── 📁 backend/ # 🔧 Flask 后端 │ ├── 📁 app/ # 应用核心 │ │ ├── 📄 __init__.py # 应用工厂 │ │ ├── 📄 config.py # 配置管理 │ │ ├── 📁 api/ # API 路由层 │ │ │ ├── 📄 image_qa.py │ │ │ ├── 📄 image_generation.py │ │ │ ├── 📄 image_editing.py │ │ │ ├── 📄 object_detection.py │ │ │ ├── 📄 image_segmentation.py │ │ │ └── 📄 video_generation.py │ │ ├── 📁 services/ # 业务逻辑层 │ │ │ ├── 📄 image_qa_service.py │ │ │ ├── 📄 image_generation_service.py │ │ │ ├── 📄 image_editing_service.py │ │ │ ├── 📄 object_detection_service.py │ │ │ ├── 📄 image_segmentation_service.py │ │ │ ├── 📄 video_generation_service.py │ │ │ ├── 📄 opencv_service.py │ │ │ ├── 📄 yolo_detection_service.py │ │ │ └── 📄 yolo_segmentation_service.py │ │ ├── 📁 main/ # 主路由 │ │ └── 📁 utils/ # 工具函数 │ ├── 📄 requirements.txt # Python 依赖 │ └── 📄 run.py # 启动文件 ├── 📁 frontend/ # 🎨 Vue.js 前端 │ ├── 📁 src/ # 源代码 │ │ ├── 📁 pages/ # 页面组件 │ │ │ ├── 📄 Home.vue │ │ │ ├── 📄 ImageQA.vue │ │ │ ├── 📄 ImageGeneration.vue │ │ │ ├── 📄 ImageEditing.vue │ │ │ ├── 📄 ObjectDetection.vue │ │ │ ├── 📄 ImageSegmentation.vue │ │ │ ├── 📄 VideoGeneration.vue │ │ │ └── 📄 Settings.vue │ │ ├── 📁 services/ # API 服务 │ │ ├── 📁 router/ # 路由配置 │ │ ├── 📁 assets/ # 静态资源 │ │ ├── 📄 App.vue # 根组件 │ │ └── 📄 main.js # 入口文件 │ ├── 📄 package.json # 前端依赖 │ └── 📄 vite.config.js # 构建配置 ├── 📁 storage/ # 📦 文件存储 │ ├── 📁 uploads/ # 用户上传 │ ├── 📁 generated/ # AI 生成 │ └── 📁 models/ # AI 模型 (自动下载) │ ├── 📄 README.md # 模型说明 │ └── 📄 *.pt # YOLO 模型 (首次使用时下载) ├── 📄 .env.example # 环境变量模板 ├── 📄 .gitignore # Git 忽略规则 ├── 📄 README.md # 项目说明 ├── 📄 doc.md # 功能文档 └── 📄 GIT_SETUP.md # Git 使用指南
🔌 API 接口
🏠 主要路由
| 方法 | 路径 | 功能 | 描述 |
|---|---|---|---|
| GET | / | 主页 | 应用主界面 |
| GET | /api/features | 功能列表 | 获取所有可用功能 |
🤖 图像问答
| 方法 | 路径 | 功能 |
|---|---|---|
| POST | /api/image-qa | 图像问答 |
| GET | /api/image-qa/models | 获取可用模型 |
🎨 图像生成
| 方法 | 路径 | 功能 |
|---|---|---|
| POST | /api/image-generation | 生成图像 |
| GET | /api/image-generation/models | 获取生成模型 |
✏️ 图像编辑
| 方法 | 路径 | 功能 |
|---|---|---|
| POST | /api/image-editing | 编辑图像 |
🎯 目标检测
| 方法 | 路径 | 功能 |
|---|---|---|
| POST | /api/object-detection | Gemini 检测 |
| POST | /api/object-detection/opencv | OpenCV 检测 |
| POST | /api/object-detection/yolo | YOLO 检测 |
| POST | /api/object-detection/compare | 对比分析 |
🔍 图像分割
| 方法 | 路径 | 功能 |
|---|---|---|
| POST | /api/image-segmentation | Gemini 分割 |
| POST | /api/image-segmentation/opencv | OpenCV 分割 |
| POST | /api/image-segmentation/yolo | YOLO 分割 |
| POST | /api/image-segmentation/compare | 对比分析 |
🎬 视频生成
| 方法 | 路径 | 功能 |
|---|---|---|
| POST | /api/video-generation | 生成视频 |
🤖 支持的 AI 模型
🔍 视觉理解模型
- gemini-2.0-flash – 快速多模态模型
- gemini-2.0-flash-exp – 实验性增强版本
🎨 图像生成模型
- imagen-3.0-generate-002 – 高质量照片级图像
- gemini-2.0-flash-exp-image-generation – 创意图像生成
🎬 视频生成模型
- veo-2.0-generate-001 – 最新视频生成模型
🎯 检测分割模型
- YOLO v11 系列 – 实时目标检测
yolo11n– Nano (最快)yolo11s– Small (平衡)yolo11m– Medium (推荐)yolo11l– Large (高精度)yolo11x– Extra Large (最高精度)
💡 使用示例
🤖 图像问答示例
ounter(lineounter(lineounter(lineounter(line # 上传图像并提问 curl -X POST http://localhost:5000/api/image-qa \ -F "image=@your_image.jpg" \ -F "question=这张图片里有什么动物?"
示例问题:
- “这张图片的主要内容是什么?”
- “图片中有多少个人?”
- “描述一下图片的颜色和氛围”
- “这是在什么地方拍摄的?”
🎨 图像生成示例
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 使用 Imagen 3 生成图像 curl -X POST http://localhost:5000/api/image-generation \ -H "Content-Type: application/json" \ -d '{ "prompt": "一只可爱的机器人猫在未来城市中漫步", "model": "imagen-3", "num_images": 1 }'
示例提示词:
- “夕阳下的壮丽山景,金色光芒洒在雪山上”
- “一个充满科技感的未来城市,霓虹灯闪烁”
- “古典中式庭院,春天樱花盛开”
🎯 目标检测示例
ounter(lineounter(lineounter(lineounter(line # 使用对比分析检测狗 curl -X POST http://localhost:5000/api/object-detection/compare \ -F "image=@dog_image.jpg" \ -F "object_name=狗"
🔍 图像分割示例
ounter(lineounter(lineounter(lineounter(line # 分割图像中的人物 curl -X POST http://localhost:5000/api/image-segmentation \ -F "image=@person_image.jpg" \ -F "object_name=人"
🎬 视频生成示例
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 生成视频 curl -X POST http://localhost:5000/api/video-generation \ -H "Content-Type: application/json" \ -d '{ "prompt": "一只小猫在花园里玩耍,阳光明媚" }'
⚙️ 配置说明
🔧 环境变量配置
编辑 .env 文件或设置环境变量:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 必需配置 GOOGLE_API_KEY=your_google_ai_api_key_here GEMINI_API_KEY=your_google_ai_api_key_here SECRET_KEY=your_random_secret_key # 可选模型配置 GEMINI_VISION_MODEL=gemini-2.0-flash GEMINI_IMAGE_GEN_MODEL=gemini-2.0-flash-exp-image-generation IMAGEN_MODEL=imagen-3.0-generate-002 # 服务器配置 BACKEND_PORT=5000 FRONTEND_PORT=3000
🎛️ 高级配置
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 文件上传限制 (16MB) MAX_CONTENT_LENGTH=16777216 # 日志级别 LOG_LEVEL=INFO # CORS 设置 CORS_ORIGINS=http://localhost:3000,http://127.0.0.1:3000
✨ 功能特性
✅ 已实现功能
- 🤖 智能图像问答 – Gemini 2.0 Flash 驱动
- 🎨 AI 图像生成 – Imagen 3 + Gemini 双引擎
- ✏️ 智能图像编辑 – 自然语言编辑指令
- 🎯 多算法目标检测 – Gemini + OpenCV + YOLO v11
- 🔍 精确图像分割 – 像素级对象分割
- 🎬 AI 视频生成 – Veo 2.0 视频生成
- 🌐 中文界面 – 完整中文用户体验
- 🌙 深色/浅色模式 – 主题切换
- 📱 响应式设计 – 移动端适配
- 🔄 实时模型选择 – 动态获取可用模型
- ⚠️ 智能错误处理 – 友好的错误提示
- 📊 对比分析 – 多算法结果对比
- ✅ 内容验证 – 智能匹配查询与图像内容
🚀 技术亮点
- 模块化架构 – 清晰的代码组织
- 多算法集成 – 同一功能多种实现
- 智能缓存 – 模型加载优化
- 异步处理 – 提升用户体验
- 配置驱动 – 灵活的环境管理
- 版本控制 – 完整的 Git 工作流
📋 系统要求
🖥️ 运行环境
- Python 3.8+ (推荐 3.9+)
- Node.js 16+ (推荐 18+)
- Git (版本控制)
- 4GB+ RAM (AI 模型运行)
- 2GB+ 存储空间 (模型文件)
📦 主要依赖
- Flask 3.0+ – Web 框架
- google-genai 1.16.1 – 最新 Gemini SDK
- ultralytics – YOLO v11 模型
- opencv-python – 计算机视觉
- Vue.js 3 – 前端框架
- TailwindCSS – 样式框架
🔧 故障排除
❗ 常见问题
1. API 密钥错误
ounter(lineounter(lineounter(lineounter(lineounter(line # 检查环境变量 echo $GOOGLE_API_KEY # 验证密钥格式 # 应该以 "AI..." 开头
2. 文件上传问题
- 检查文件大小 (最大 16MB)
- 支持格式: JPG, PNG, GIF, WebP
- 确保文件未损坏
3. 模型加载失败
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 检查模型文件 ls -la storage/models/ # 重新下载模型 rm storage/models/yolo11n.pt # 重启应用会自动下载
4. 端口冲突
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 检查端口占用 lsof -i :5000 lsof -i :3000 # 修改端口配置 # 编辑 .env 文件中的 BACKEND_PORT 和 FRONTEND_PORT
🛠️ 错误处理机制
- 文件验证 – 自动检查文件格式和大小
- API 错误处理 – 智能重试和降级
- 用户友好提示 – 中文错误信息
- 操作回退 – 失败操作可恢复
🤝 贡献指南
📝 开发流程
- Fork 项目 – 创建您的分支
- 创建功能分支 –
git checkout -b feature/amazing-feature - 提交更改 –
git commit -m 'Add amazing feature' - 推送分支 –
git push origin feature/amazing-feature - 创建 Pull Request – 详细描述您的更改
🧪 测试要求
- 确保所有功能正常工作
- 添加必要的测试用例
- 验证中文界面显示
- 测试不同浏览器兼容性
📋 代码规范
- 遵循 PEP 8 (Python)
- 使用 ESLint (JavaScript)
- 添加中文注释
- 保持代码简洁清晰
🙏 项目地址
🌟 项目地址
https://github.com/0xsline/GeminiImageApp/blob/main/README.md
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)
相关文章







