一手实测超强开源OCR文档识别,效果超闭源模型。
这个OCR有点牛的。
开源没几天就有2.5k星星了。
看我实测的就知道有多猛,我用这个项目的论文测试了下,别家这里都是图片,它这里直接就识别成表格了,甚至符号都长得一样。
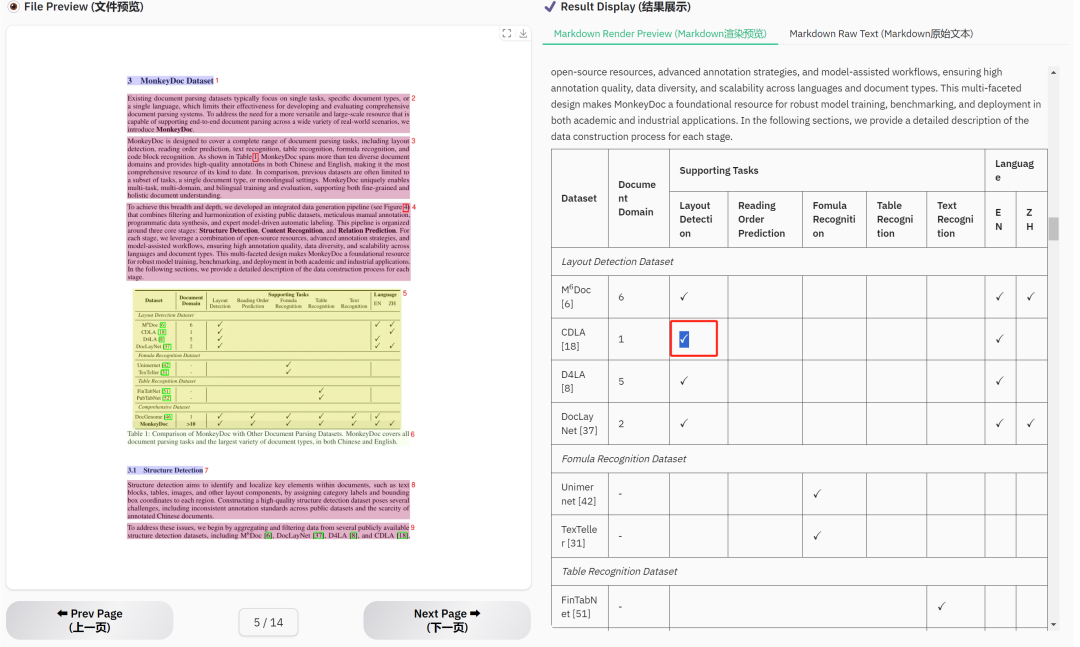
开源的OCR已经进化到比很多闭源的效果更好了。
所以PDF、文档翻译这些根本没必要再去花大价钱用了。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
MonkeyOCR 是一个用于文档解析OCR的项目,采用结构 – 识别 – 关系三元组范式。它支持英文和中文文档解析。能处理 PDF 和图像文件,输出多种格式结果。还可通过特定方式更新配置文件以使用不同模型。
DEMO
支持中英文

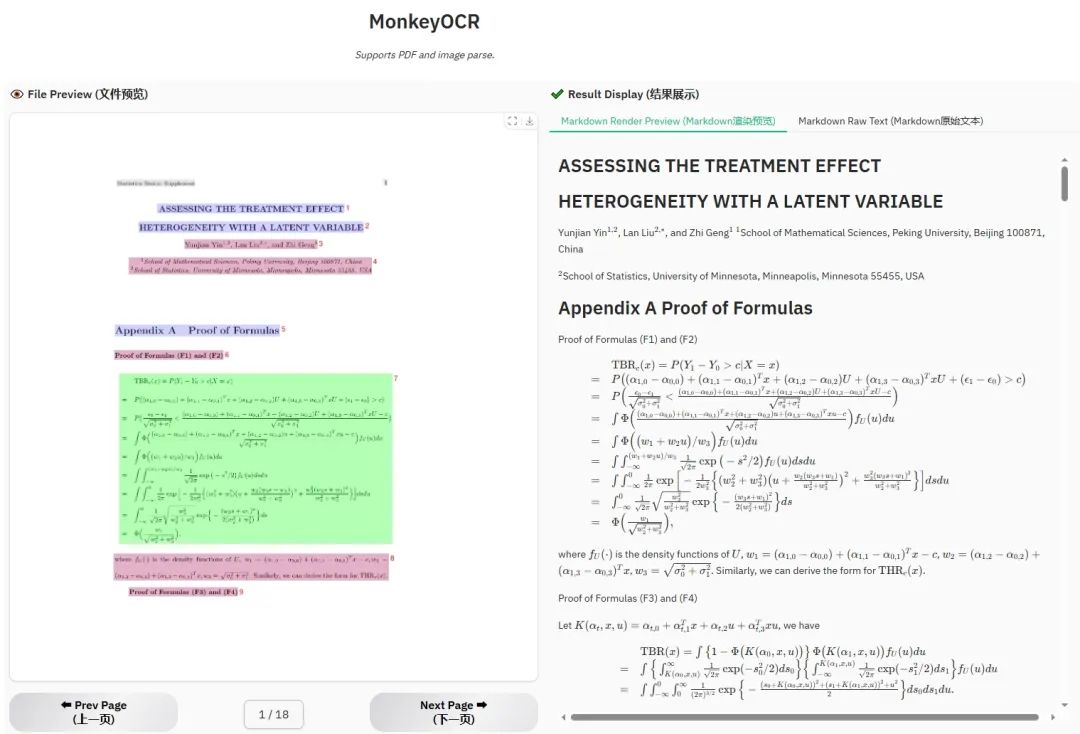
公式
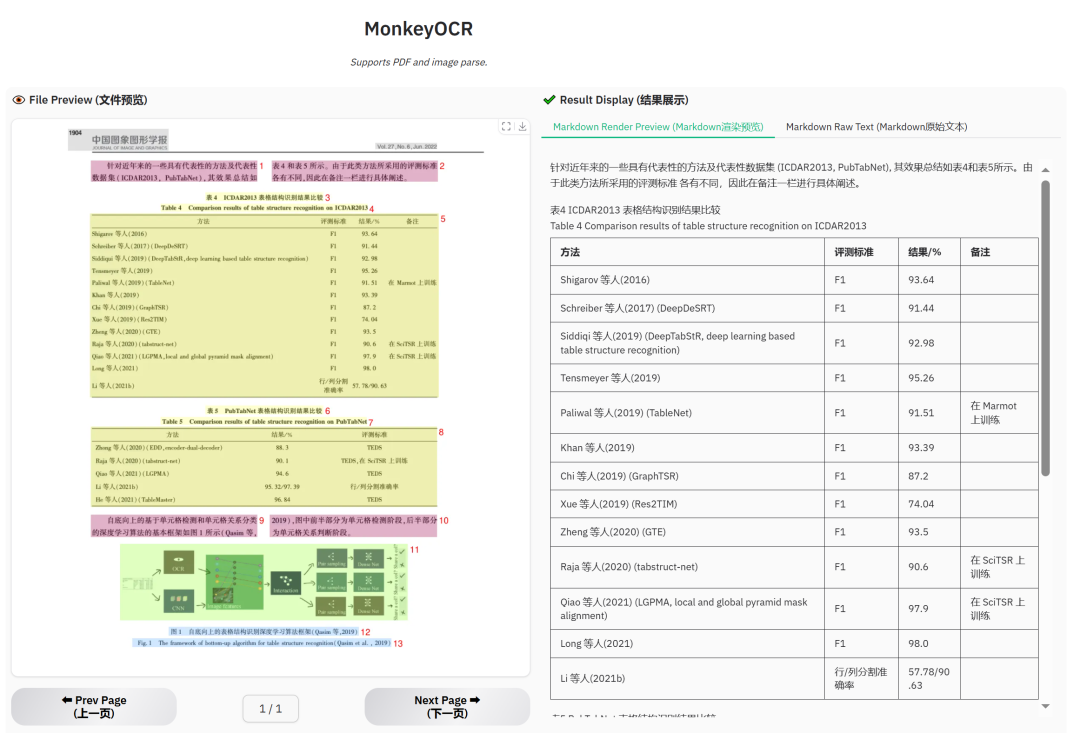
表格
报纸

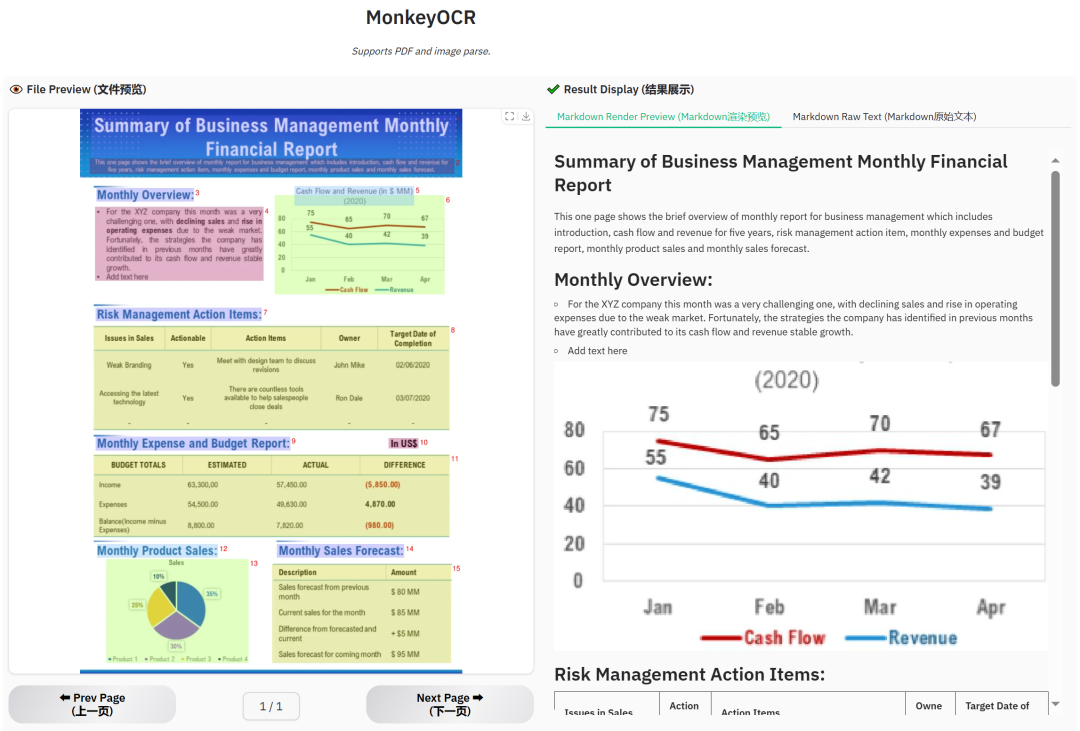
财务报告
技术特点
创新的 SRR 三元组范式:将文档解析抽象为 “在哪里”(结构)、“是什么”(识别)和 “如何组织”(关系)三个基本问题,对应布局分析、内容识别和逻辑排序,平衡了准确性和速度,实现高效、可扩展的处理而不牺牲精度。
三阶段处理流程:
- 结构检测:使用基于 YOLO 的文档布局检测器,准确分割文本块、表格、公式、图像等语义区域。
- 块级内容识别:对每个检测到的区域并行进行内容识别,利用统一的大型多模态模型(LMM),避免传统管道的错误传播。
- 关系预测:通过专用的块级阅读顺序模型,推断检测元素之间的逻辑阅读顺序,重建其逻辑和语义连接。
大规模多样化数据集:开发了 MonkeyDoc 数据集,包含 390 万个块级实例,覆盖 5 个核心文档解析任务和 10 多种文档类型,全面支持中英文。
性能表现:
- 与 MinerU 相比,在中英文文档上平均提升 5.1%,公式识别提升 15.0%,表格识别提升 8.6%。
- 3B 参数模型在英文文档解析任务上超越更大的模型,如 Qwen2.5-VL(72B)和 Gemini 2.5 Pro。
- 多页文档处理速度达 0.84 页 / 秒,优于 MinerU(0.65)和 Qwen2.5-VL-7B(0.12)。
项目链接
https://github.com/Yuliang-Liu/MonkeyOCR
关注「开源AI项目落地」公众号
(文:开源AI项目落地)
扫描二维码,在手机上阅读
相关文章








订阅更新
输入邮箱,第一时间接收本站新文章推送。
🤞 分享