commands.py中的函数解析3:fix_app_site_missing等
本文使用Dify v1.4.0版本,主要解析了commands.py中的fix_app_site_missing和migrate_data_for_plugin等函数的执行逻辑。源码位置:dify\api\commands.py
一.fix_app_site_missing()函数
在 api/commands.py 文件中,fix-app-site-missing 命令的完整执行示例如下:
python -m flask fix-app-site-missing
如果使用的是 Flask CLI,可以这样:
flask fix-app-site-missing
该函数用于批量修复缺失site的app,通过事件触发 site 重新创建,异常时记录失败并继续,直到全部处理完毕。
`@click.command("fix-app-site-missing", help="Fix app related site missing issue.")
deffix_app_site_missing():
"""
Fix app related site missing issue.
"""
click.echo(click.style("Starting fix for missing app-related sites.", fg="green"))
failed_app_ids = []
whileTrue:
sql = """select apps.id as id from apps left join sites on sites.app_id=apps.id
where sites.id is null limit 1000"""
with db.engine.begin() as conn:
rs = conn.execute(db.text(sql))
processed_count = 0
for i in rs:
processed_count += 1
app_id = str(i.id)
if app_id in failed_app_ids:
continue
try:
app = db.session.query(App).filter(App.id == app_id).first()
ifnot app:
print(f"App {app_id} not found")
continue
tenant = app.tenant
if tenant:
accounts = tenant.get_accounts()
ifnot accounts:
print("Fix failed for app {}".format(app.id))
continue
account = accounts[0]
print("Fixing missing site for app {}".format(app.id))
app_was_created.send(app, account=account)
except Exception:
failed_app_ids.append(app_id)
click.echo(click.style("Failed to fix missing site for app {}".format(app_id), fg="red"))
logging.exception(f"Failed to fix app related site missing issue, app_id: {app_id}")
continue
ifnot processed_count:
break
click.echo(click.style("Fix for missing app-related sites completed successfully!", fg="green"))
`
1.命令注册与函数定义
@click.command("fix-app-site-missing", help="Fix app related site missing issue.") deffix_app_site_missing():
通过 click 注册命令行命令 fix-app-site-missing,定义修复函数。
2.开始提示
click.echo(click.style("Starting fix for missing app-related sites.", fg="green"))
输出开始修复的提示信息。
3.初始化失败 app 列表
failed_app_ids = []
4.循环处理所有缺失 site 的 app
`whileTrue:
sql = """select apps.id as id from apps left join sites on sites.app_id=apps.id
where sites.id is null limit 1000"""
with db.engine.begin() as conn:
rs = conn.execute(db.text(sql))
processed_count = 0
for i in rs:
processed_count += 1
app_id = str(i.id)
if app_id in failed_app_ids:
continue
try:
app = db.session.query(App).filter(App.id == app_id).first()
ifnot app:
print(f"App {app_id} not found")
continue
tenant = app.tenant
if tenant:
accounts = tenant.get_accounts()
ifnot accounts:
print("Fix failed for app {}".format(app.id))
continue
account = accounts[0]
print("Fixing missing site for app {}".format(app.id))
app_was_created.send(app, account=account)
except Exception:
failed_app_ids.append(app_id)
click.echo(click.style("Failed to fix missing site for app {}".format(app_id), fg="red"))
logging.exception(f"Failed to fix app related site missing issue, app_id: {app_id}")
continue
ifnot processed_count:
break
`
- 通过 SQL 查询找出没有 site 记录的 app(每次最多 1000 条)。
- 遍历每个 app id,跳过已失败的。
- 查询 app 实体,若不存在则跳过。
- 获取 app 的 tenant,若 tenant 存在,获取其 accounts,若无账号则跳过。
- 取第一个账号,调用
app_was_created.send(app, account=account)触发 site 创建事件。 - 若过程中有异常,记录失败 app id 并输出错误日志。
- 若本轮没有处理任何 app,则跳出循环。
5.结束提示
click.echo(click.style("Fix for missing app-related sites completed successfully!", fg="green"))
输出修复完成提示。
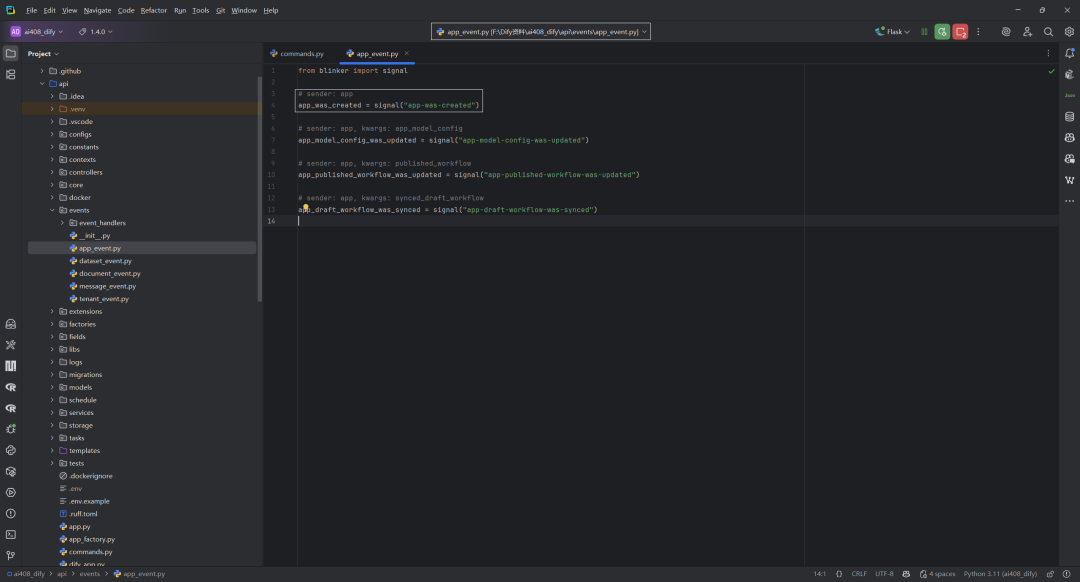
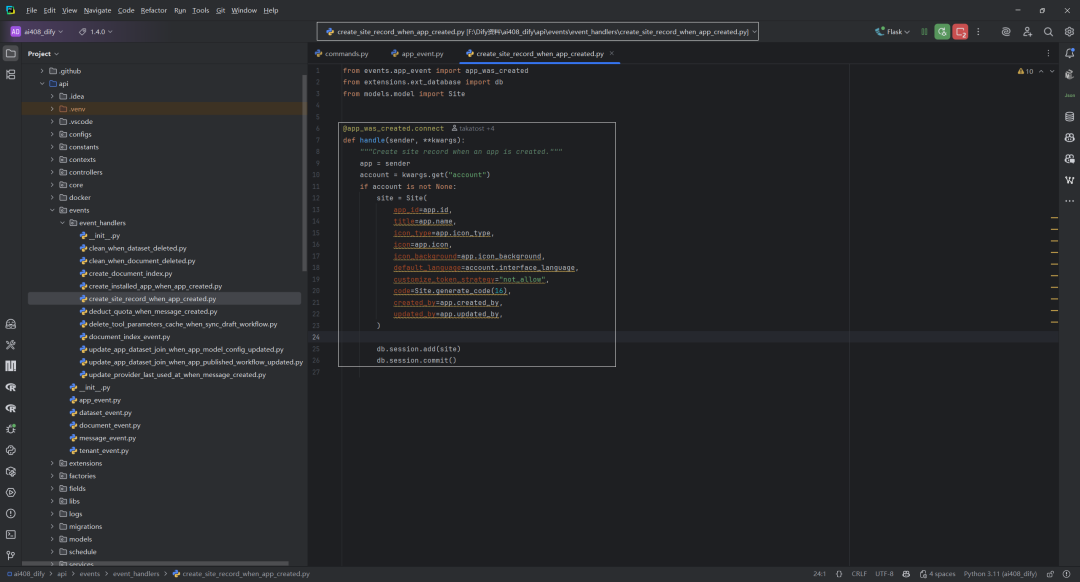
注解:site创建事件,如下所示:
该代码监听 app 创建事件,在 app 被创建时自动生成对应的 site 记录,并将其保存到数据库中。具体流程为:当 app 创建事件触发时,获取 sender(即 app 实例)和 account 信息,若 account 存在,则根据 app 和 account 的属性创建 Site 实例,并提交到数据库。
二.migrate_data_for_plugin()函数
完整的执行命令示例,如下所示:
flask migrate-data-for-plugin
migrate_data_for_plugin 是一个 Click 命令行命令,用于迁移插件相关的数据。
`@click.command("migrate-data-for-plugin", help="Migrate data for plugin.")
defmigrate_data_for_plugin():
"""
Migrate data for plugin.
"""
click.echo(click.style("Starting migrate data for plugin.", fg="white"))
PluginDataMigration.migrate()
click.echo(click.style("Migrate data for plugin completed.", fg="green"))
`
主要流程,如下所示:
- 输出”开始迁移插件数据”的提示信息(白色字体)。
- 调用
PluginDataMigration.migrate()方法,执行实际的数据迁移逻辑。 - 输出”插件数据迁移完成”的提示信息(绿色字体)。
该命令用于在命令行中触发插件数据的迁移操作,便于维护和升级插件相关的数据结构。
三.data_migration.py – migrate
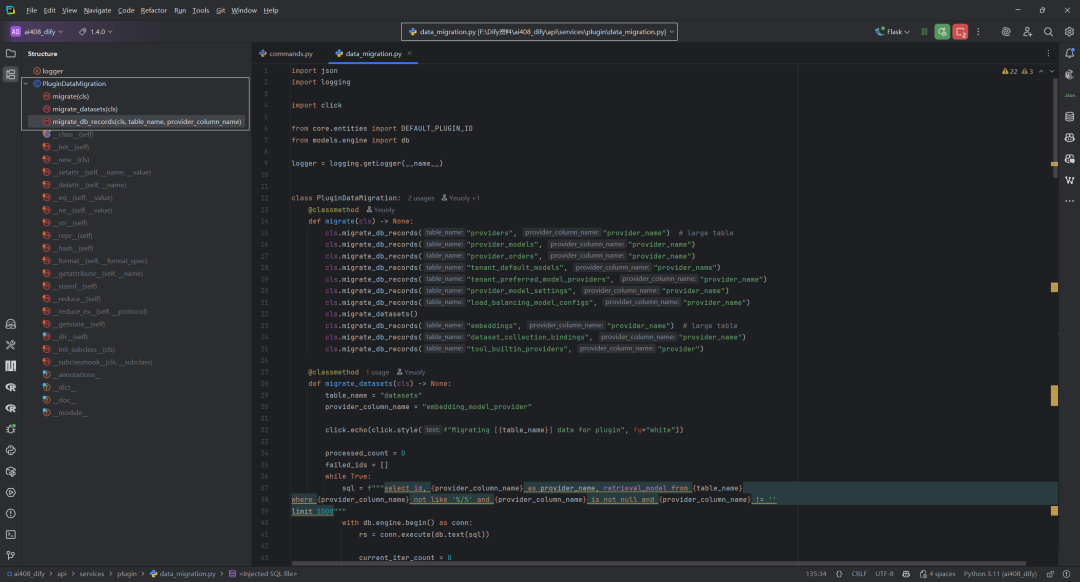
migrate 类方法是 PluginDataMigration 的主入口,用于批量迁移数据库中与 provider 相关的字段。包括的数据表:providers、provider_models、provider_orders、tenant_default_models、tenant_preferred_model_providers、provider_model_settings、load_balancing_model_configs、datasets、embeddings、dataset_collection_bindings、tool_builtin_providers。
@classmethod def migrate(cls) -> None: cls.migrate_db_records("providers", "provider_name") # large table cls.migrate_db_records("provider_models", "provider_name") cls.migrate_db_records("provider_orders", "provider_name") cls.migrate_db_records("tenant_default_models", "provider_name") cls.migrate_db_records("tenant_preferred_model_providers", "provider_name") cls.migrate_db_records("provider_model_settings", "provider_name") cls.migrate_db_records("load_balancing_model_configs", "provider_name") cls.migrate_datasets() cls.migrate_db_records("embeddings", "provider_name") # large table cls.migrate_db_records("dataset_collection_bindings", "provider_name") cls.migrate_db_records("tool_builtin_providers", "provider")
其执行流程,如下所示:
- 依次调用
migrate_db_records方法,对多个表(如providers、provider_models、provider_orders等)中provider字段进行批量迁移。迁移逻辑是将provider字段值更新为DEFAULT_PLUGIN_ID/provider_name/provider_name格式。 - 对于
datasets表,调用migrate_datasets方法,除provider字段外,还会处理retrieval_model字段中的嵌套provider字段(如reranking_provider_name),并做相应格式化。 - 继续迁移
embeddings、dataset_collection_bindings、tool_builtin_providers等表的provider字段。
整体流程是:遍历所有需要迁移的表,批量查找未迁移的记录,更新 provider 字段为新格式,并输出迁移进度。特殊表(如 datasets)还会处理嵌套 JSON 字段。每步都包含异常处理和日志输出,确保迁移过程可追踪。
四.data_migration.py – migrate_datasets
该方法 migrate_datasets 主要用于迁移 datasets 表中的数据,将 embedding_model_provider 字段的值更新为带有插件前缀的格式,并对 retrieval_model 字段中的 reranking_provider_name 进行相应处理。
`@classmethod
defmigrate_datasets(cls) -> None:
table_name = "datasets"
provider_column_name = "embedding_model_provider"
click.echo(click.style(f"Migrating [{table_name}] data for plugin", fg="white"))
processed_count = 0
failed_ids = []
whileTrue:
sql = f"""select id, {provider_column_name} as provider_name, retrieval_model from {table_name}
where {provider_column_name} not like '%/%' and {provider_column_name} is not null and {provider_column_name} != ''
limit 1000"""
with db.engine.begin() as conn:
rs = conn.execute(db.text(sql))
current_iter_count = 0
for i in rs:
record_id = str(i.id)
provider_name = str(i.provider_name)
retrieval_model = i.retrieval_model
print(type(retrieval_model))
if record_id in failed_ids:
continue
retrieval_model_changed = False
if retrieval_model:
if (
"reranking_model"in retrieval_model
and"reranking_provider_name"in retrieval_model["reranking_model"]
and retrieval_model["reranking_model"]["reranking_provider_name"]
and"/"notin retrieval_model["reranking_model"]["reranking_provider_name"]
):
click.echo(
click.style(
f"[{processed_count}] Migrating {table_name}{record_id} "
f"(reranking_provider_name: "
f"{retrieval_model['reranking_model']['reranking_provider_name']})",
fg="white",
)
)
retrieval_model["reranking_model"]["reranking_provider_name"] = (
f"{DEFAULT_PLUGIN_ID}/{retrieval_model['reranking_model']['reranking_provider_name']}/{retrieval_model['reranking_model']['reranking_provider_name']}"
)
retrieval_model_changed = True
click.echo(
click.style(
f"[{processed_count}] Migrating [{table_name}] {record_id} ({provider_name})",
fg="white",
)
)
try:
update provider name append with "langgenius/{provider_name}/{provider_name}"
params = {"record_id": record_id}
update_retrieval_model_sql = ""
if retrieval_model and retrieval_model_changed:
update_retrieval_model_sql = ", retrieval_model = :retrieval_model"
params["retrieval_model"] = json.dumps(retrieval_model)
sql = f"""update {table_name}
set {provider_column_name} =
concat('{DEFAULT_PLUGIN_ID}/', {provider_column_name}, '/', {provider_column_name})
{update_retrieval_model_sql}
where id = :record_id"""
conn.execute(db.text(sql), params)
click.echo(
click.style(
f"[{processed_count}] Migrated [{table_name}] {record_id} ({provider_name})",
fg="green",
)
)
except Exception:
failed_ids.append(record_id)
click.echo(
click.style(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})",
fg="red",
)
)
logger.exception(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})"
)
continue
current_iter_count += 1
processed_count += 1
ifnot current_iter_count:
break
click.echo(
click.style(f"Migrate [{table_name}] data for plugin completed, total: {processed_count}", fg="green")
)
`
1.初始化与准备
- 设置表名、字段名。
- 输出迁移开始信息。
- 初始化计数器和失败列表。
`table_name = "datasets"
provider_column_name = "embedding_model_provider"
click.echo(click.style(f"Migrating [{table_name}] data for plugin", fg="white"))
processed_count = 0
failed_ids = []
`
2.主循环:批量处理未迁移的数据
- 构造 SQL 查询,查找 provider 字段未带
/且不为空的记录,每次最多处理 1000 条。 - 使用数据库连接执行查询。
whileTrue: sql = f"""select id, {provider_column_name} as provider_name, retrieval_model from {table_name} where {provider_column_name} not like '%/%' and {provider_column_name} is not null and {provider_column_name} != '' limit 1000""" with db.engine.begin() as conn: rs = conn.execute(db.text(sql))
3.遍历结果集,处理每条记录
- 取出 id、provider_name、retrieval_model。
- 跳过已失败的 id。
- 检查并处理 retrieval_model 字段中的 reranking_provider_name,如果需要则加前缀。
- 输出迁移中信息。
`current_iter_count = 0
for i in rs:
record_id = str(i.id)
provider_name = str(i.provider_name)
retrieval_model = i.retrieval_model
print(type(retrieval_model))
if record_id in failed_ids:
continue
retrieval_model_changed = False
if retrieval_model:
if (
"reranking_model"in retrieval_model
and"reranking_provider_name"in retrieval_model["reranking_model"]
and retrieval_model["reranking_model"]["reranking_provider_name"]
and"/"notin retrieval_model["reranking_model"]["reranking_provider_name"]
):
click.echo(
click.style(
f"[{processed_count}] Migrating {table_name}{record_id} "
f"(reranking_provider_name: "
f"{retrieval_model['reranking_model']['reranking_provider_name']})",
fg="white",
)
)
retrieval_model["reranking_model"]["reranking_provider_name"] = (
f"{DEFAULT_PLUGIN_ID}/{retrieval_model['reranking_model']['reranking_provider_name']}/{retrieval_model['reranking_model']['reranking_provider_name']}"
)
retrieval_model_changed = True
click.echo(
click.style(
f"[{processed_count}] Migrating [{table_name}] {record_id} ({provider_name})",
fg="white",
)
)
`
4.执行更新操作
- 构造更新 SQL,将 provider 字段加前缀,必要时更新 retrieval_model 字段。
- 执行更新,输出成功或失败信息,记录失败 id 并打印异常。
`try:
update provider name append with "langgenius/{provider_name}/{provider_name}"
params = {"record_id": record_id}
update_retrieval_model_sql = ""
if retrieval_model and retrieval_model_changed:
update_retrieval_model_sql = ", retrieval_model = :retrieval_model"
params["retrieval_model"] = json.dumps(retrieval_model)
sql = f"""update {table_name}
set {provider_column_name} =
concat('{DEFAULT_PLUGIN_ID}/', {provider_column_name}, '/', {provider_column_name})
{update_retrieval_model_sql}
where id = :record_id"""
conn.execute(db.text(sql), params)
click.echo(
click.style(
f"[{processed_count}] Migrated [{table_name}] {record_id} ({provider_name})",
fg="green",
)
)
except Exception:
failed_ids.append(record_id)
click.echo(
click.style(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})",
fg="red",
)
)
logger.exception(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})"
)
continue
current_iter_count += 1
processed_count += 1
`
5.判断是否还有未处理的数据
如果本轮没有处理任何数据,则跳出循环。
ifnot current_iter_count: break
6.输出迁移完成信息
click.echo( click.style(f"Migrate [{table_name}] data for plugin completed, total: {processed_count}", fg="green") )
整体流程就是:循环批量查询未迁移的数据,处理每条记录的 provider 字段和 retrieval_model 字段,更新数据库,记录失败项,直到全部迁移完成。
五.data_migration.py – migrate_db_records
该方法 migrate_db_records 主要用于批量迁移数据库表中 provider 字段的数据格式。整体流程就是分页查询、批量处理、批量更新、异常处理和进度输出,直到所有数据迁移完成。
`@classmethod
defmigrate_db_records(cls, table_name: str, provider_column_name: str) -> None:
click.echo(click.style(f"Migrating [{table_name}] data for plugin", fg="white"))
processed_count = 0
failed_ids = []
last_id = "00000000-0000-0000-0000-000000000000"
whileTrue:
sql = f"""
SELECT id, {provider_column_name} AS provider_name
FROM {table_name}
WHERE {provider_column_name} NOT LIKE '%/%'
AND {provider_column_name} IS NOT NULL
AND {provider_column_name} != ''
AND id > :last_id
ORDER BY id ASC
LIMIT 5000
"""
params = {"last_id": last_id or""}
with db.engine.begin() as conn:
rs = conn.execute(db.text(sql), params)
current_iter_count = 0
batch_updates = []
for i in rs:
current_iter_count += 1
processed_count += 1
record_id = str(i.id)
last_id = record_id
provider_name = str(i.provider_name)
if record_id in failed_ids:
continue
click.echo(
click.style(
f"[{processed_count}] Migrating [{table_name}] {record_id} ({provider_name})",
fg="white",
)
)
try:
updated_value = f"{DEFAULT_PLUGIN_ID}/{provider_name}/{provider_name}"
batch_updates.append((updated_value, record_id))
except Exception as e:
failed_ids.append(record_id)
click.echo(
click.style(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})",
fg="red",
)
)
logger.exception(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})"
)
continue
if batch_updates:
update_sql = f"""
UPDATE {table_name}
SET {provider_column_name} = :updated_value
WHERE id = :record_id
"""
conn.execute(db.text(update_sql), [{"updated_value": u, "record_id": r} for u, r in batch_updates])
click.echo(
click.style(
f"[{processed_count}] Batch migrated [{len(batch_updates)}] records from [{table_name}]",
fg="green",
)
)
ifnot current_iter_count:
break
click.echo(
click.style(f"Migrate [{table_name}] data for plugin completed, total: {processed_count}", fg="green")
)
`
1.初始化与准备
- 输出迁移开始信息。
- 初始化计数器、失败ID列表、last_id(用于分页)。
`@click.echo(click.style(f"Migrating [{table_name}] data for plugin", fg="white"))
processed_count = 0
failed_ids = []
last_id = "00000000-0000-0000-0000-000000000000"
`
2.循环分页处理
- 构造 SQL 查询,查找 provider 字段未迁移(不含
/)的记录,按 id 升序分页(每次 5000 条)。 - 用 last_id 控制分页,避免遗漏或重复。
whileTrue: sql = f""" SELECT id, {provider_column_name} AS provider_name FROM {table_name} WHERE {provider_column_name} NOT LIKE '%/%' AND {provider_column_name} IS NOT NULL AND {provider_column_name} != '' AND id > :last_id ORDER BY id ASC LIMIT 5000 """ params = {"last_id": last_id or""}
3.处理每一批数据
`with db.engine.begin() as conn:
rs = conn.execute(db.text(sql), params)
current_iter_count = 0
batch_updates = []
for i in rs:
current_iter_count += 1
processed_count += 1
record_id = str(i.id)
last_id = record_id
provider_name = str(i.provider_name)
if record_id in failed_ids:
continue
click.echo(
click.style(
f"[{processed_count}] Migrating [{table_name}] {record_id} ({provider_name})",
fg="white",
)
)
try:
updated_value = f"{DEFAULT_PLUGIN_ID}/{provider_name}/{provider_name}"
batch_updates.append((updated_value, record_id))
except Exception as e:
failed_ids.append(record_id)
click.echo(
click.style(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})",
fg="red",
)
)
logger.exception(
f"[{processed_count}] Failed to migrate [{table_name}] {record_id} ({provider_name})"
)
continue
`
遍历查询结果过程,如下所示:
- 计数,更新 last_id。
- 跳过失败过的记录。
- 输出迁移进度。
- 构造迁移后的 provider 字段值(格式为
DEFAULT_PLUGIN_ID/provider_name/provider_name)。 - 加入批量更新列表。
- 异常时记录失败ID并输出错误日志。
4.批量更新
- 如果有需要更新的记录,批量执行 UPDATE 语句。
- 输出批量迁移成功信息。
if batch_updates: update_sql = f""" UPDATE {table_name} SET {provider_column_name} = :updated_value WHERE id = :record_id """ conn.execute(db.text(update_sql), [{"updated_value": u, "record_id": r} for u, r in batch_updates]) click.echo( click.style( f"[{processed_count}] Batch migrated [{len(batch_updates)}] records from [{table_name}]", fg="green", ) )
5.终止条件
如果本批没有数据,跳出循环。
ifnot current_iter_count: break
输出迁移完成信息。
6.结束输出
click.echo( click.style(f"Migrate [{table_name}] data for plugin completed, total: {processed_count}", fg="green") )
参考文献
[0] commands.py中的函数解析3:fix_app_site_missing等:https://z0yrmerhgi8.feishu.cn/wiki/SOMfwSDdBiEf3CkukxackjQfnQd
[1] click github:https://github.com/pallets/click
[2] click官方文档:https://click.palletsprojects.com/en/stable/
[3] click-extra github:https://github.com/kdeldycke/click-extra
[4] click-extra官方文档:https://kdeldycke.github.io/click-extra/
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)
相关文章







