RAG-Anything:PDF、表格、公式全能读!港大开源神器让AI真正理解复杂文档?

RAG-Anything是一个由香港大学数据智能实验室开发的开源多模态RAG系统,支持处理包含文本、图像、表格和公式的复杂文档,提供从文档摄取到智能查询的端到端解决方案。系统基于多模态知识图谱、灵活的解析架构和混合检索机制,显著提升复杂文档处理能力,支持多种文档格式,如PDF、Office文档、图像和文本文件等。

一、技术原理
(一)图增强文本索引
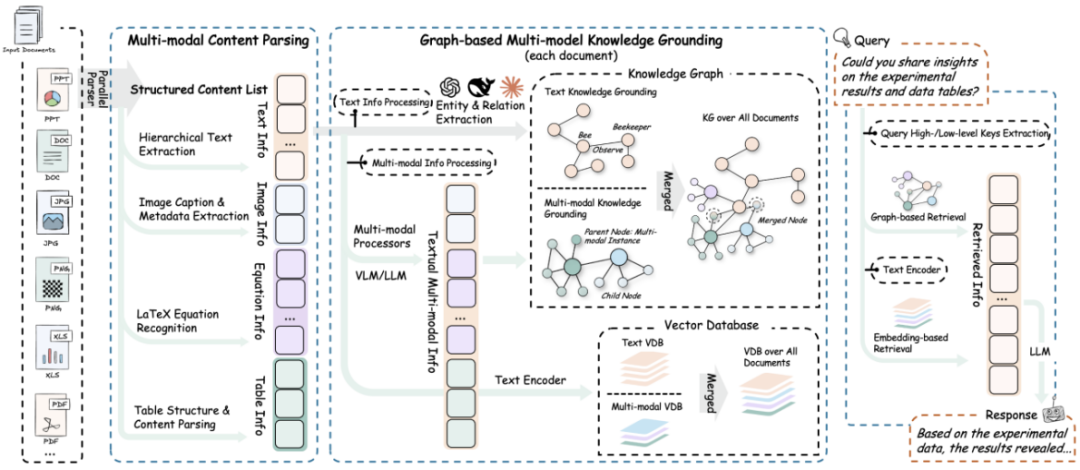
RAG-Anything基于LLM从文本中提取实体(节点)及其关系(边),将信息用于构建知识图谱。为每个实体节点和关系边生成文本键值对,键是用于高效检索的单词或短语,值是总结相关外部数据片段的文本段落。识别、合并来自不同文本片段的相同实体和关系,减少图操作的开销,提高数据处理效率。
(二)双重检索范式
- 低层次检索:专注于检索特定实体及其属性或关系,适用需要精确信息的详细查询。
- 高层次检索:处理更广泛的主题和主题,基于聚合多个相关实体和关系的信息,提供对高级概念和总结的见解。
- 图和向量集成:结合图结构和向量表示,检索算法用局部和全局关键词,提高检索效率和结果相关性。
(三)检索增强型答案生成
用检索到的信息,基于LLM生成基于收集数据的答案,包括实体和关系的名称、描述及原始文本片段。将查询与多源文本统一,LLM生成与用户需求一致的答案,确保与查询意图对齐。
(四)复杂性分析
图基索引阶段用LLM从每个文本块中提取实体和关系,无需额外开销,高效管理新文本更新。图基检索阶段用LLM生成相关关键词,依靠向量搜索进行检索,显著减少检索开销。
二、主要功能
(一)端到端多模态流水线
从文档解析到多模态智能查询,提供一体化工作流程。系统能够自动识别文档中的不同模态内容,并将其路由到相应的处理通道,实现高效的内容解析和理解。
(二)多格式文档支持
兼容PDF、Office文档(DOC/DOCX、PPT/PPTX、XLS/XLSX)、图像(JPG、PNG等)和文本文件(TXT、MD)。无论用户手中的文档是何种格式,RAG-Anything都能轻松应对,满足不同场景下的文档处理需求。
(三)多模态内容分析引擎
针对图像、表格、公式和通用文本内容部署专门的处理器,确保各类内容的精准解析。例如,视觉内容分析器能够生成基于视觉语义的上下文感知描述性标题,并提取视觉元素之间的空间关系和层次结构;结构化数据解释器则对表格和结构化数据格式进行系统解释,识别数据趋势和语义关系。
(四)知识图谱索引
自动提取实体和跨模态关系,构建语义连接网络。通过构建多模态知识图谱,系统能够更好地理解文档内容之间的关联,为智能问答提供丰富的语义信息支持。
(五)灵活的处理架构
支持MinerU智能解析模式和直接多模态内容插入模式,适配多样化场景。用户可以根据自己的需求选择合适的处理模式,无论是对复杂文档的深度解析,还是对特定模态内容的快速处理,RAG-Anything都能提供灵活的解决方案。
(六)跨模态检索机制
实现跨文本和多模态内容的智能检索,提供精准的信息定位和匹配能力。用户可以通过输入文本查询,系统能够理解查询意图,并在多模态文档中检索出与之相关的信息,无论是文本描述、图像内容还是表格数据,都能精准匹配。
三、应用场景
(一)学术研究
快速解析和理解大量学术文献,提取关键信息和研究结果,支持文献综述和实验数据分析,助力跨学科研究。研究人员可以利用RAG-Anything高效地处理学术论文,快速获取所需信息,加速研究进程。
(二)企业知识管理
整合企业内部文档,如会议记录、项目报告等,提供智能查询和知识共享,提升内部信息流通效率。企业员工可以通过RAG-Anything快速查找所需资料,促进知识共享和团队协作。
(三)金融分析
处理财务报表和市场研究报告,提取关键财务指标和市场趋势,辅助风险评估和投资决策。金融分析师可以借助RAG-Anything深入分析金融文档,挖掘有价值的信息,为投资决策提供有力支持。
(四)医疗健康
解析病历中的文本、图像和表格,支持医疗诊断和治疗方案制定,处理医学研究文献和实验数据。医疗专业人员可以利用RAG-Anything高效地处理医疗文档,提高诊断准确性和治疗效果。
(五)智能客服
快速回答客户问题,提高客服效率,整合企业知识库,提供智能查询和知识推荐,优化客户体验。客服人员可以借助RAG-Anything快速准确地回答客户咨询,提升客户满意度。
四、快速使用
(一)安装
1、从PyPI安装(推荐)
# 基本安装 pip install raganything # 安装所有可选依赖 pip install 'raganything[all]'
2、从源码安装
git clone https://github.com/HKUDS/RAG-Anything.git cd RAG-Anything pip install -e .
(二)使用示例
1、端到端文档处理
import asyncio from raganything import RAGAnything, RAGAnythingConfig from lightrag.llm.openai import openai_complete_if_cache, openai_embed from lightrag.utils import EmbeddingFunc async def main(): # 设置API配置 api_key = "your-api-key" base_url = "your-base-url" # 可选 # 创建RAGAnything配置 config = RAGAnythingConfig( working_dir="./rag_storage", mineru_parse_method="auto", enable_image_processing=True, enable_table_processing=True, enable_equation_processing=True, ) # 定义LLM模型函数 def llm_model_func(prompt, system_prompt=None, history_messages=[], **kwargs): return openai_complete_if_cache( "gpt-4o-mini", prompt, system_prompt=system_prompt, history_messages=history_messages, api_key=api_key, base_url=base_url, **kwargs, ) # 定义视觉模型函数用于图像处理 def vision_model_func( prompt, system_prompt=None, history_messages=[], image_data=None, **kwargs ): if image_data: return openai_complete_if_cache( "gpt-4o", "", system_prompt=None, history_messages=[], messages=[ {"role": "system", "content": system_prompt} if system_prompt else None, { "role": "user", "content": [ {"type": "text", "text": prompt}, { "type": "image_url", "image_url": { "url": f"data:image/jpeg;base64,{image_data}" }, }, ], } if image_data else {"role": "user", "content": prompt}, ], api_key=api_key, base_url=base_url, **kwargs, ) else: return llm_model_func(prompt, system_prompt, history_messages, **kwargs) # 定义嵌入函数 embedding_func = EmbeddingFunc( embedding_dim=3072, max_token_size=8192, func=lambda texts: openai_embed( texts, model="text-embedding-3-large", api_key=api_key, base_url=base_url, ), ) # 初始化RAGAnything rag = RAGAnything( config=config, llm_model_func=llm_model_func, vision_model_func=vision_model_func, embedding_func=embedding_func, ) # 处理文档 await rag.process_document_complete( file_path="path/to/your/document.pdf", output_dir="./output", parse_method="auto" ) # 查询处理后的内容 # 纯文本查询 - 用于基本知识库搜索 text_result = await rag.aquery( "What are the main findings shown in the figures and tables?", mode="hybrid" ) print("Text query result:", text_result) # 多模态查询,包含特定多模态内容 multimodal_result = await rag.aquery_with_multimodal( "Explain this formula and its relevance to the document content", multimodal_content=[{ "type": "equation", "latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}", "equation_caption": "Document relevance probability" }], mode="hybrid" ) print("Multimodal query result:", multimodal_result) if __name__ == "__main__": asyncio.run(main())
2、直接多模态内容处理
import asyncio from lightrag import LightRAG from lightrag.llm.openai import openai_complete_if_cache, openai_embed from lightrag.utils import EmbeddingFunc from raganything.modalprocessors import ImageModalProcessor, TableModalProcessor async def process_multimodal_content(): # 设置API配置 api_key = "your-api-key" base_url = "your-base-url" # 可选 # 初始化LightRAG rag = LightRAG( working_dir="./rag_storage", llm_model_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache( "gpt-4o-mini", prompt, system_prompt=system_prompt, history_messages=history_messages, api_key=api_key, base_url=base_url, **kwargs, ), embedding_func=EmbeddingFunc( embedding_dim=3072, max_token_size=8192, func=lambda texts: openai_embed( texts, model="text-embedding-3-large", api_key=api_key, base_url=base_url, ), ) ) await rag.initialize_storages() # 处理图像 image_processor = ImageModalProcessor( lightrag=rag, modal_caption_func=lambda prompt, system_prompt=None, history_messages=[], image_data=None, **kwargs: openai_complete_if_cache( "gpt-4o", "", system_prompt=None, history_messages=[], messages=[ {"role": "system", "content": system_prompt} if system_prompt else None, {"role": "user", "content": [ {"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}} ]} if image_data else {"role": "user", "content": prompt} ], api_key=api_key, base_url=base_url, **kwargs, ) if image_data else openai_complete_if_cache( "gpt-4o-mini", prompt, system_prompt=system_prompt, history_messages=history_messages, api_key=api_key, base_url=base_url, **kwargs, ) ) image_content = { "img_path": "path/to/image.jpg", "img_caption": ["Figure 1: Experimental results"], "img_footnote": ["Data collected in 2024"] } description, entity_info = await image_processor.process_multimodal_content( modal_content=image_content, content_type="image", file_path="research_paper.pdf", entity_name="Experimental Results Figure" ) # 处理表格 table_processor = TableModalProcessor( lightrag=rag, modal_caption_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache( "gpt-4o-mini", prompt, system_prompt=system_prompt, history_messages=history_messages, api_key=api_key, base_url=base_url, **kwargs, ) ) table_content = { "table_body": """ | Method | Accuracy | F1-Score | |--------|----------|----------| | RAGAnything | 95.2% | 0.94 | | Baseline | 87.3% | 0.85 | """, "table_caption": ["Performance Comparison"], "table_footnote": ["Results on test dataset"] } description, entity_info = await table_processor.process_multimodal_content( modal_content=table_content, content_type="table", file_path="research_paper.pdf", entity_name="Performance Results Table" ) if __name__ == "__main__": asyncio.run(process_multimodal_content())
结语
RAG-Anything作为香港大学数据智能实验室推出的开源多模态RAG系统,凭借其创新的技术架构和强大的功能,为多模态文档处理与智能问答领域带来了新的突破。它不仅支持多种文档格式,还能精准解析图像、表格、公式等多模态内容,并通过构建知识图谱实现跨模态的智能检索与问答。
GitHub仓库:https://github.com/HKUDS/RAG-Anything
arXiv技术论文:https://arxiv.org/pdf/2410.05779
(文:小兵的AI视界)
相关文章







