谷歌开源高效文本提取 Python 库LangExtract
项目简介
LangExtract 是一个 Python 库,利用大型语言模型(LLMs)从非结构化文本中提取结构化信息,基于用户定义的指令。它可以处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。
为什么选择 LangExtract?
- 精确的源文本定位:将每次提取映射到源文本中的确切位置,支持可视化高亮,便于追溯和验证。
- 可靠的结构化输出:基于少量示例强制执行一致的输出模式,利用支持的模型(如 Gemini)的受控生成功能,确保结果稳健且结构化。
- 针对长文档优化:通过优化的文本分块、并行处理和多轮提取策略,解决大文档提取中的“大海捞针”问题,提高召回率。
- 交互式可视化:即时生成独立的交互式 HTML 文件,用于在原始上下文中查看和审查数千个提取实体。
- 灵活的 LLM 支持:支持从云端 LLM(如 Google Gemini 系列)到本地开源模型(通过内置的 Ollama 接口)的多种模型。
- 适应任何领域:仅需少量示例即可定义任何领域的提取任务,无需微调模型。
- 利用 LLM 世界知识:通过精确的提示词和少量示例,引导模型在提取任务中利用其知识。推断信息的准确性及其对任务规范的遵循程度取决于所选 LLM、任务的复杂性、提示指令的清晰度以及示例的性质。
快速开始
注意:使用云端托管模型(如 Gemini)需要 API 密钥。请参阅 API 密钥设置[1] 部分了解如何获取和配置密钥。
仅需几行代码即可提取结构化信息。
1. 定义提取任务
首先,创建一个清晰描述提取内容的提示,然后提供高质量的示例以引导模型。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line import langextract as lx import textwrap # 1. 定义提示和提取规则 prompt = textwrap.dedent("""\ 按出现顺序提取角色、情感和关系。 使用精确文本进行提取,不要改写或重叠实体。 为每个实体提供有意义的属性以添加上下文。""") # 2. 提供高质量示例以引导模型 examples = [ lx.data.ExampleData( text="罗密欧:轻声!那边窗子里亮起来的是什么光?那就是东方,朱丽叶就是太阳。", extractions=[ lx.data.Extraction( extraction_class="角色", extraction_text="罗密欧", attributes={"情感状态": "惊叹"} ), lx.data.Extraction( extraction_class="情感", extraction_text="轻声!", attributes={"感受": "温柔的敬畏"} ), lx.data.Extraction( extraction_class="关系", extraction_text="朱丽叶就是太阳", attributes={"类型": "隐喻"} ), ] ) ]
2. 运行提取
将输入文本和提示材料提供给 lx.extract 函数。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 待处理的输入文本 input_text = "朱丽叶夫人凝视着星空,心中对罗密欧充满渴望" # 运行提取 result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, model_id="gemini-2.5-flash", )
模型选择:推荐默认使用
gemini-2.5-flash,它在速度、成本和质量之间提供了最佳平衡。对于需要深度推理的复杂任务,gemini-2.5-pro可能表现更优。对于大规模或生产环境,建议使用 Tier 2 Gemini 配额以提高吞吐量并避免速率限制。详情请参阅 速率限制文档[2]。模型生命周期:请注意,Gemini 模型有生命周期和定义的退役日期。用户应查阅 官方模型版本文档[3] 以了解最新稳定版和旧版信息。
3. 可视化结果
提取结果可以保存为 .jsonl 文件(一种常用的语言模型数据格式),然后生成交互式 HTML 可视化文件以在上下文中审查实体。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 将结果保存到 JSONL 文件 lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".") # 从文件生成可视化 html_content = lx.visualize("extraction_results.jsonl") with open("visualization.html", "w") as f: f.write(html_content)
这将生成一个动态交互式 HTML 文件:
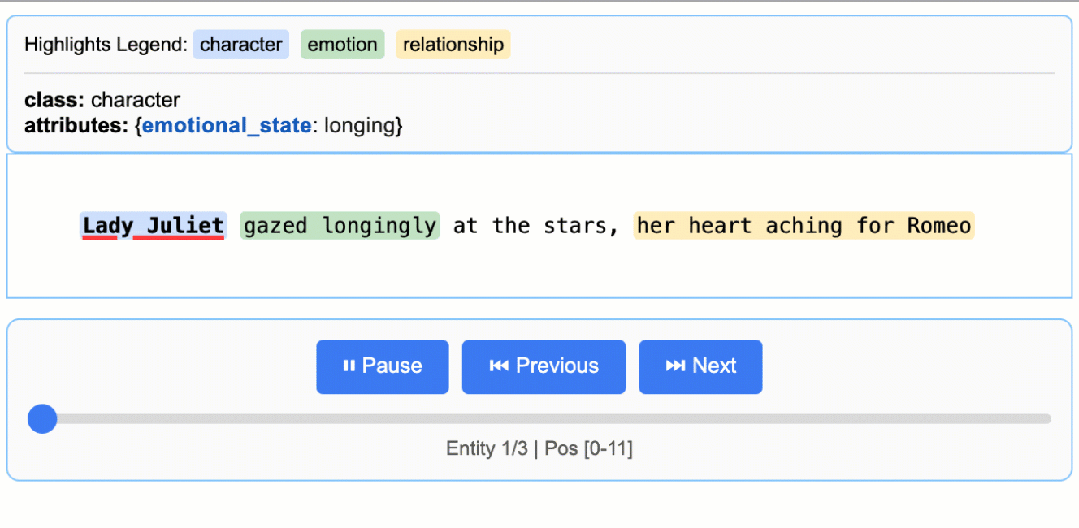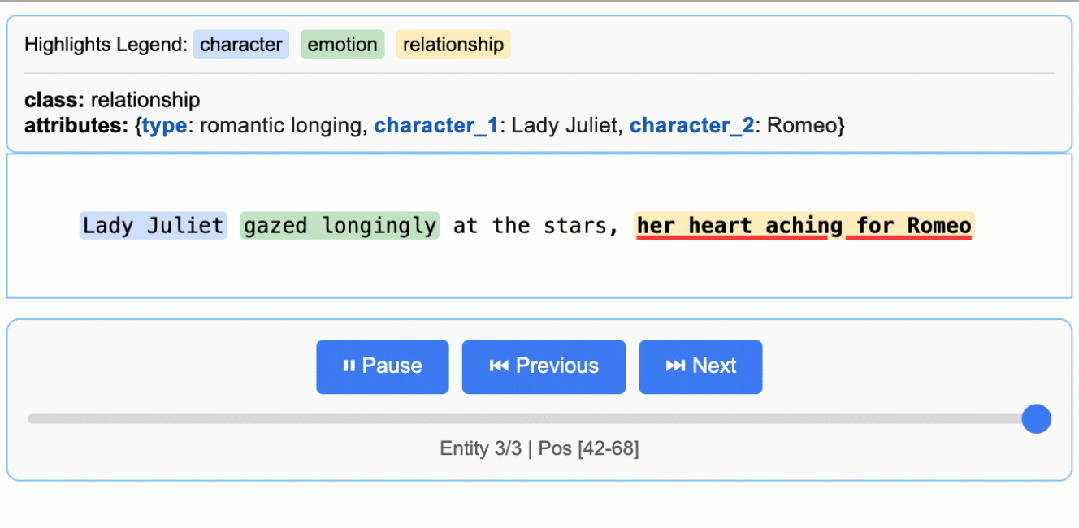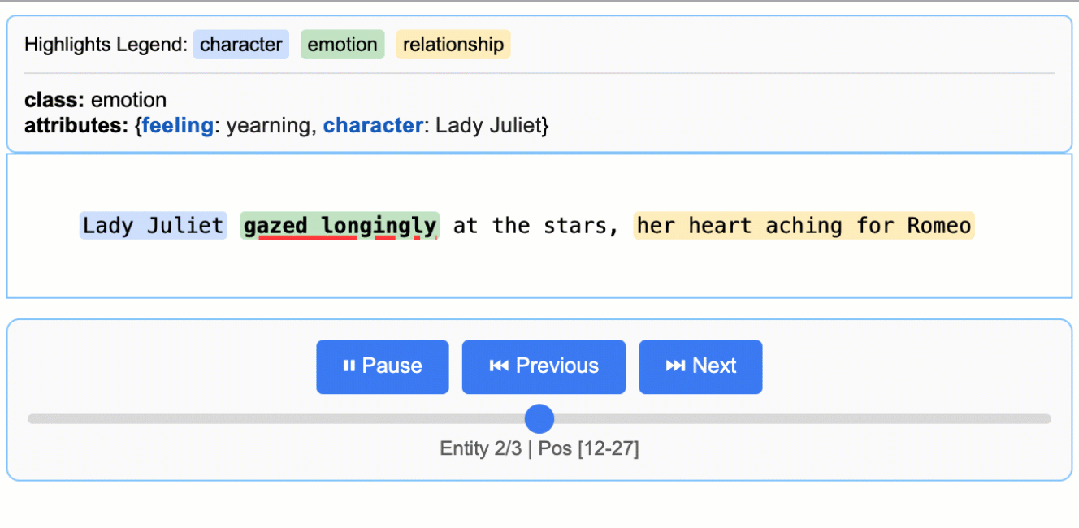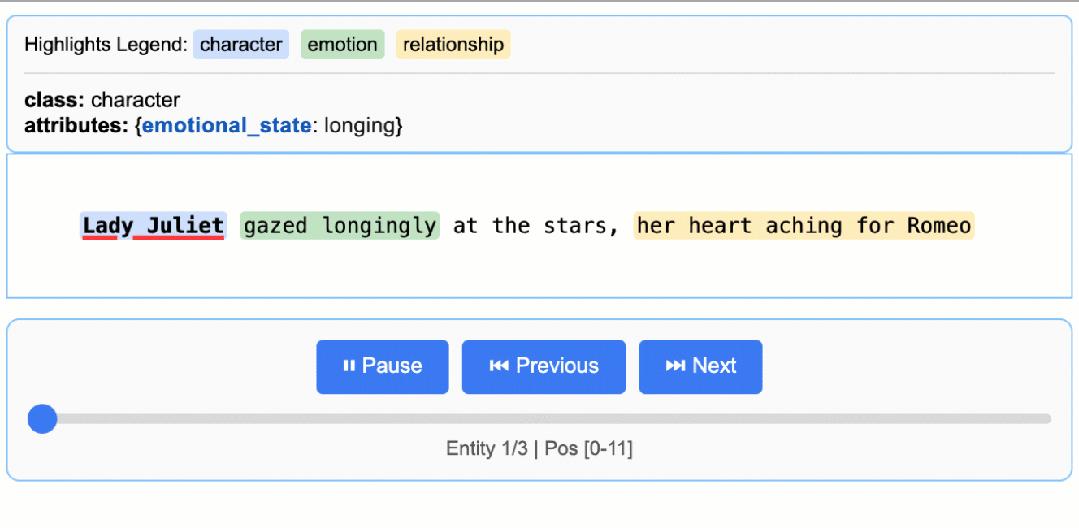
罗密欧与朱丽叶基础可视化
关于 LLM 知识利用的说明:此示例展示了基于文本证据的提取——提取朱丽叶夫人的情感状态“渴望”并从“凝视着星空”中识别“向往”。任务可以修改为生成更多依赖 LLM 世界知识的属性(例如添加
"身份": "卡普莱特家族的女儿"或"文学背景": "悲剧女主角")。文本证据与知识推断之间的平衡由提示指令和示例属性控制。
扩展到长文档
对于更长的文本,可以直接从 URL 并行处理整个文档,并提高敏感度:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 直接从古登堡计划处理《罗密欧与朱丽叶》 result = lx.extract( text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt", prompt_description=prompt, examples=examples, model_id="gemini-2.5-flash", extraction_passes=3, # 通过多轮提取提高召回率 max_workers=20, # 并行处理以提高速度 max_char_buffer=1000 # 较小的上下文以提高准确性 )
此方法可以从完整小说中提取数百个实体,同时保持高准确性。交互式可视化无缝处理大量结果集,便于从输出 JSONL 文件中探索数百个实体。查看完整的《罗密欧与朱丽叶》提取示例 →[4] 了解详细结果和性能分析。
安装
通过 PyPI 安装
ounter(line pip install langextract
推荐大多数用户使用。对于隔离环境,建议使用虚拟环境:
ounter(lineounter(lineounter(line python -m venv langextract_env source langextract_env/bin/activate # Windows: langextract_env\Scripts\activate pip install langextract
从源码安装
LangExtract 使用现代 Python 打包工具 pyproject.toml 管理依赖:
使用 -e 参数安装为开发模式,允许修改代码而无需重新安装。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line git clone https://github.com/google/langextract.git cd langextract # 基本安装: pip install -e . # 开发安装(包含代码检查工具): pip install -e ".[dev]" # 测试安装(包含 pytest): pip install -e ".[test]"
Docker
ounter(lineounter(line docker build -t langextract . docker run --rm -e LANGEXTRACT_API_KEY="your-api-key" langextract python your_script.py
云模型 API 密钥设置
使用云端托管模型(如 Gemini 或 OpenAI)时,需要设置 API 密钥。本地 LLM 不需要 API 密钥。对于使用本地 LLM 的开发者,LangExtract 内置了对 Ollama 的支持,并可通过更新推理端点扩展到其他第三方 API。
API 密钥来源
从以下平台获取 API 密钥:
- AI Studio[5] 用于 Gemini 模型
- Vertex AI[6] 用于企业用途
- OpenAI Platform[7] 用于 OpenAI 模型
在环境中设置 API 密钥
选项 1:环境变量
ounter(line export LANGEXTRACT_API_KEY="your-api-key-here"
选项 2:.env 文件(推荐)
将 API 密钥添加到 .env 文件:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line # 将 API 密钥添加到 .env 文件 cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOF # 保护 API 密钥安全 echo '.env' >> .gitignore
在 Python 代码中:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line import langextract as lx result = lx.extract( text_or_documents=input_text, prompt_description="提取信息...", examples=[...], model_id="gemini-2.5-flash" )
选项 3:直接提供 API 密钥(不推荐用于生产)
也可以在代码中直接提供 API 密钥,但不推荐用于生产环境:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line result = lx.extract( text_or_documents=input_text, prompt_description="提取信息...", examples=[...], model_id="gemini-2.5-flash", api_key="your-api-key-here" # 仅用于测试/开发 )
使用 OpenAI 模型
LangExtract 也支持 OpenAI 模型。OpenAI 配置示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line from langextract.inference import OpenAILanguageModel result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, language_model_type=OpenAILanguageModel, model_id="gpt-4o", api_key=os.environ.get('OPENAI_API_KEY'), fence_output=True, use_schema_constraints=False )
注意:OpenAI 模型需要设置 fence_output=True 和 use_schema_constraints=False,因为 LangExtract 尚未为 OpenAI 实现模式约束。
项目地址
https://github.com/google/langextract/blob/main/README.md
参考资料
[1]
API 密钥设置: #云模型-api-密钥设置
[2]
速率限制文档: https://ai.google.dev/gemini-api/docs/rate-limits#tier-2
[3]
官方模型版本文档: https://cloud.google.com/vertex-ai/generative-ai/docs/learn/model-versions
[4]
查看完整的《罗密欧与朱丽叶》提取示例 →: https://github.com/google/langextract/blob/main/docs/examples/longer\_text\_example.md
[5]
AI Studio: https://aistudio.google.com/app/apikey
[6]
Vertex AI: https://cloud.google.com/vertex-ai/generative-ai/docs/sdks/overview
[7]
OpenAI Platform: https://platform.openai.com/api-keys
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)
相关文章







