腾讯混元发布混元OCR:一个1B参数的端到端OCR专家VLM
腾讯浑元发布了浑元OCR,这是一个专用于OCR和文档理解的1B参数视觉语言模型。该模型建立在浑元的原生多模态架构之上,通过单一端到端流程实现定位、解析、信息提取、视觉问答和文本图像翻译。
浑元OCR是通用VLM(如Gemini 2.5和Qwen3 VL)的轻量级替代方案,在专注OCR的任务上仍然能够匹配或超越它们。它针对如文档解析、卡片和收据提取、视频字幕提取和多层语言文档翻译等生产用途。
https://github.com/Tencent-Hunyuan/HunyuanOCR/blob/main/HunyuanOCR_Technical_Report.pdf
架构、原生分辨率ViT加轻量级LLM
浑元OCR使用3个主要模块:原生分辨率视觉编码器——浑元ViT、自适应MLP连接器和轻量级语言模型。编码器基于SigLIP-v2-400M,并扩展至支持任意输入分辨率,通过自适应补丁保留原始宽高比。将图像根据其原生比例分割成片段,并使用全局注意力处理,这有助于提高长文本行、长文档和低质量扫描的识别率。
自适应MLP连接器在空间维度上执行可学习的池化操作。它将密集的视觉标记压缩为更短的序列,同时保留来自文本密集区域的详细信息。这降低了传递给语言模型的序列长度和计算量,同时保留与OCR相关的细节。
语言模型基于密集架构的浑元0.5B模型,并使用XD RoPE。XD RoPE将旋转位置嵌入分割为4个子空间,用于文本、高度、宽度和时间。这为模型提供了与二维布局和三维时空结构对齐的本地方式。因此,相同的堆叠可以处理多栏页面、跨页面流和视频帧的序列。
训练和推理遵循完全端到端范式。循环中没有外部布局分析或后处理模型。所有任务都表示为自然语言提示,并在单个前向传递中处理。这种设计消除了跨管道阶段的错误传播并简化了部署。

数据和预训练方案
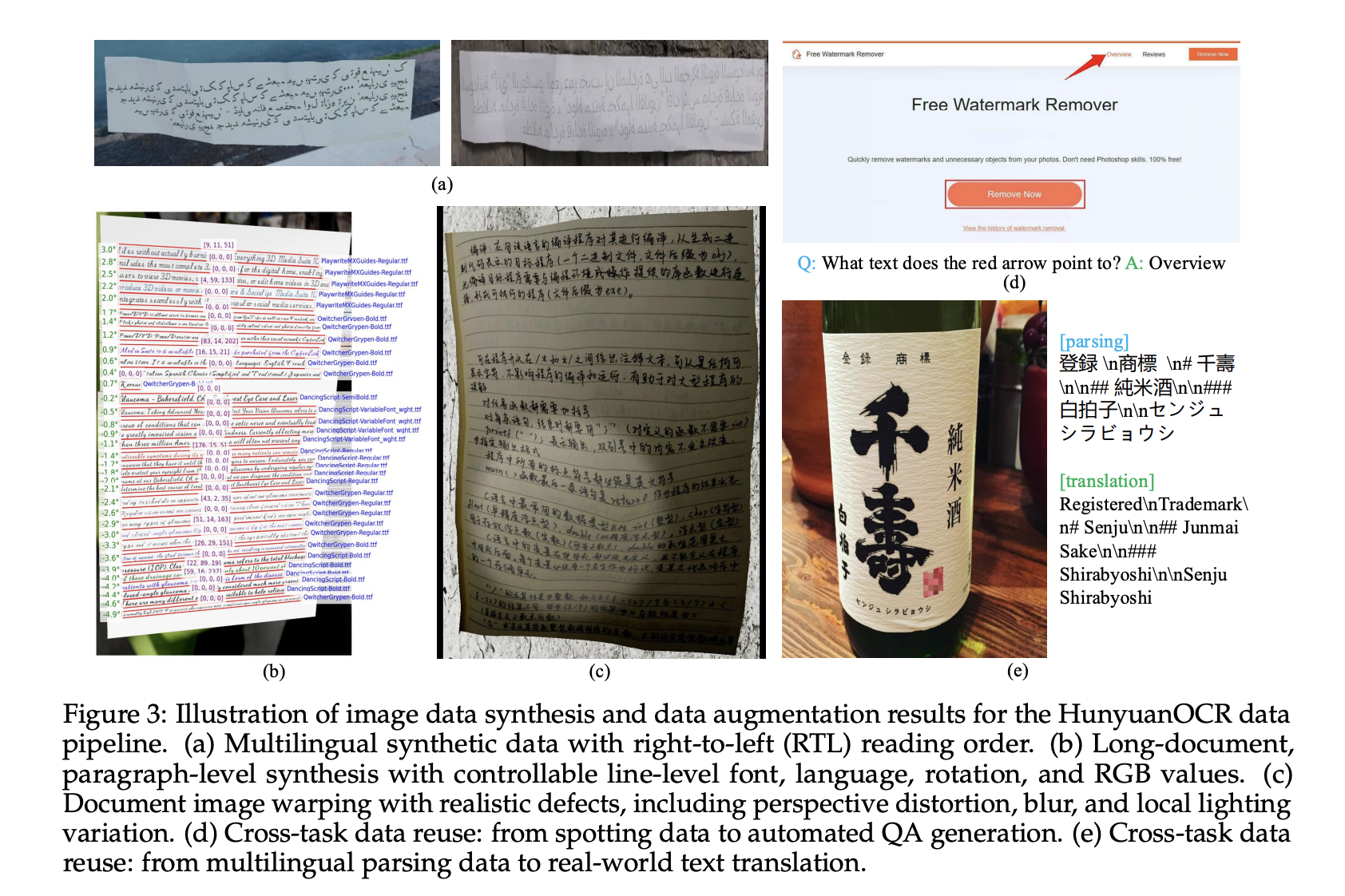
数据管道构建了超过2亿张图像文本对,涵盖了9个现实世界场景,包括街景、文档、广告、手写文本、截图、卡片和证书以及发票、游戏界面、视频帧和艺术字体。该语料库覆盖超过130种语言。
合成数据来自一个支持从右到左脚本和段落级别渲染的多语言生成器。该管道控制字体、语言、旋转和RGB值,并应用扭曲、模糊和局部光照变化以模拟手持获取和其他困难条件。
https://github.com/Tencent-Hunyuan/HunyuanOCR/blob/main/HunyuanOCR_Technical_Report.pdf
预训练分为4个阶段。第一阶段使用纯文本、合成解析和识别数据以及通用字幕数据进行视觉语言对齐,使用50B个标记和8k上下文。第二阶段在300B个标记上运行多模态预训练,混合纯文本与合成定位、解析、翻译和VQA样本。第三阶段将上下文长度扩展到32k,使用80B个标记专注于长文档和长文本。第四阶段是针对24B个标记的人注释和难负面数据的应用导向式监督微调,保持32k上下文和统一指令模板。
带有可验证奖励的强化学习
在监督训练之后,浑元OCR通过强化学习进进一步增强。研究团队使用相对策略优化GRPO和强化学习与可验证奖励设置来处理结构化任务。对于文本定位,奖励基于与并集匹配的框以及文本上的归一化编辑距离。对于文档解析,奖励使用生成的结构与参考结构之间的归一化编辑距离。
对于VQA和翻译,系统使用一个LLM作为评委。VQA使用二元奖励,检查语义匹配。翻译使用COMET风格得分的LLM,分数在[0, 5]之间,归一化到[0, 1]。训练框架强制执行长度限制和严格格式,并在输出超出或破坏方案时分配零奖励,这稳定了优化并鼓励有效的JSON或结构化输出。
基准测试结果,1B模型与更大VLM竞争
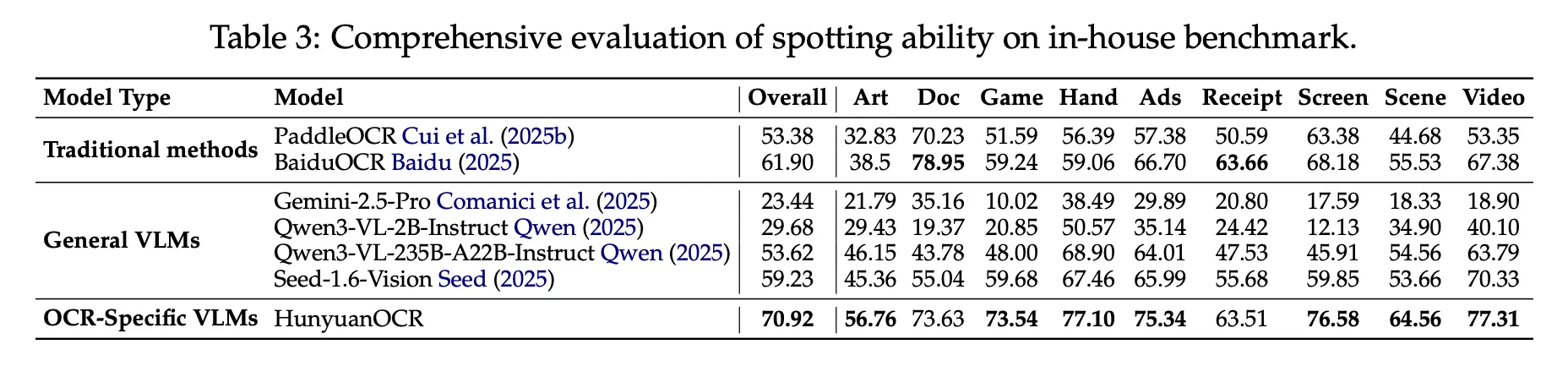
在内文中,跨9个类别的900张图像上,浑元OCR的整体得分为70.92。它优于PaddleOCR和BaiduOCR这样的传统流水线方法,并且也优于Gemini 2.5 Pro、Qwen3 VL 2B、Qwen3 VL 235B和Seed 1.6 Vision等通用VLM,尽管使用了远 fewer parameters。
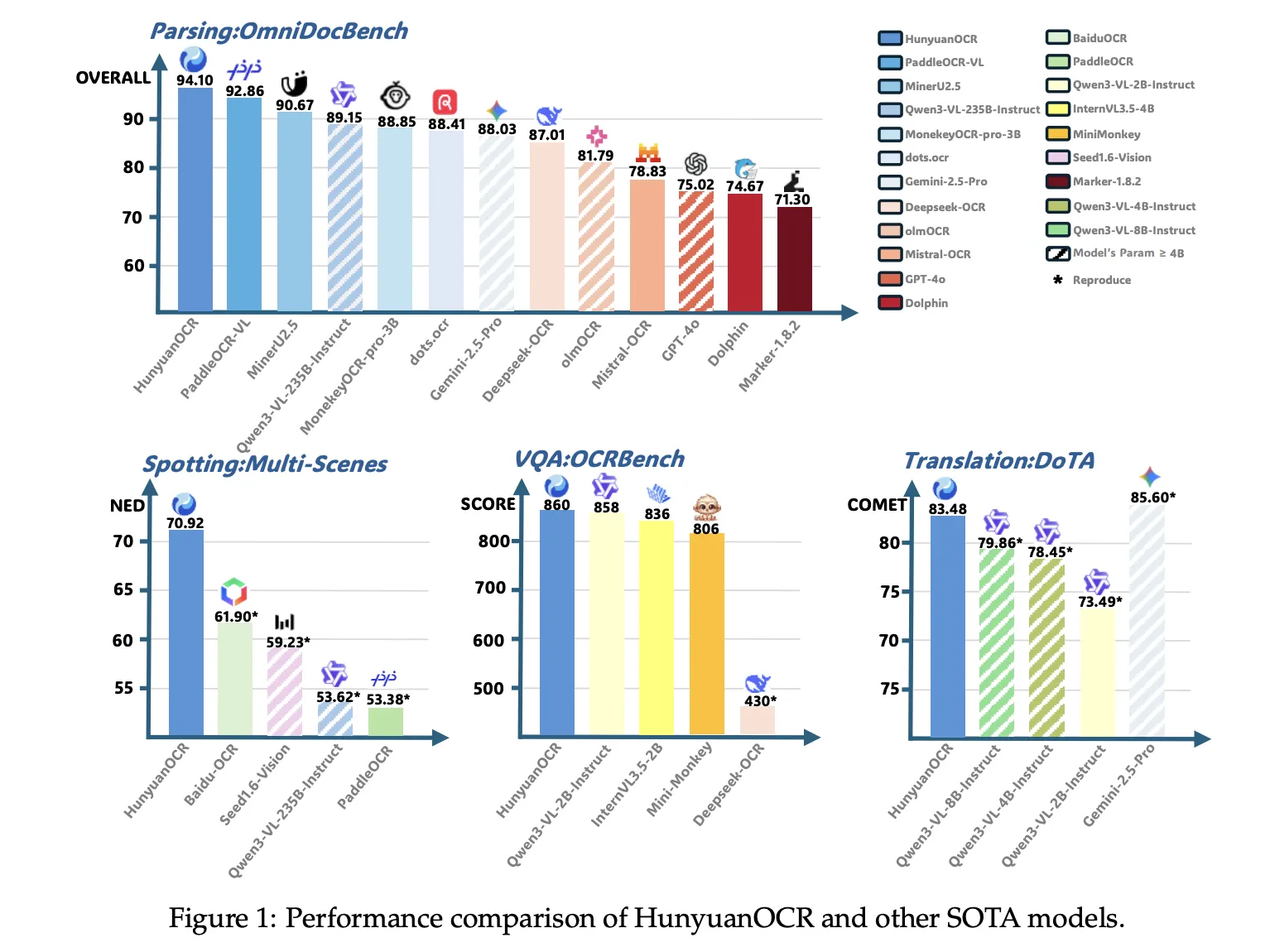
在OmniDocBench上,浑元OCR的整体得分为94.10,公式得分为94.73,表格得分为91.81。在打印和重新捕获不同折叠和光照条件下的文档的Wild OmniDocBench变体中,整体得分为85.21。在多语言解析基准测试DocML中,跨14种非中文和非英语语言,达到91.03,论文报告了所有14种语言的最新技术水平。
对于信息提取和VQA,浑元OCR在卡片上达到92.29的准确率,在收据上达到92.53,在视频字幕上达到92.87。在OCRBench上,它得到860分,高于类似规模的DeepSeek OCR,并且接近更大的通用VLM,如在核心OCR基准上表现更好的Qwen3 VL 2B Instruct和Gemini 2.5 Pro。
在文本图像翻译中,浑元OCR使用DoTA基准测试和一个基于DocML的内部集合。它在与英语到中文文档翻译相关的DoTA上取得了强烈的COMET分数,该模型在2025年ICDAR DIMT比赛的Track 2.2 OCR免费小型模型中赢得第一。
https://github.com/Tencent-Hunyuan/HunyuanOCR/blob/main/HunyuanOCR_Technical_Report.pdf
关键结论
- 紧凑的端到端OCR VLM:浑元OCR是1B参数专注于OCR的视觉语言模型,它通过MLP适配器将0.4B原生分辨率ViT连接到0.5B浑元语言模型,并通过端到端指令驱动的管道运行定位、解析、信息提取、VQA和翻译,无需外部布局或检测模块。
- 统一支持多种OCR场景:该模型在超过2亿张图像文本对上进行训练,涵盖9种场景,包括文档、街景、广告、手写内容、截图、卡片和发票、游戏界面和视频帧,在培训和部署中支持100多种语言。
- 数据管道加强化学习:训练使用4个阶段的方案,视觉语言对齐、多模态预训练、长上下文预训练和应用导向式监督微调,后跟针对定位、解析、VQA和翻译的强化学习(GRPO)和可验证奖励。
- 针对低于3B模型的强大基准测试结果
浑元OCR在OmniDocBench的文档理解上达到94.1,在OCRBench上达到860,报道称,这是参数低于3B的视觉语言模型的最新技术水平,同时也在核心OCR基准上优于Qwen3 VL 4B等多个商业OCR API和更大的公开模型。
编者按
浑元OCR是OCR特定VLM日趋成熟成为实用基础设施的强烈信号。腾讯结合了1B参数的端到端架构、原生视觉Transformer、自适应MLP连接器以及强化学习与可验证奖励,以一个覆盖100多种语言的模型,实现了定位、解析、IE、VQA和翻译,同时在低于3B的模型中在OCRBench上达到领先的水平,并在OmniDocBench上达到94.1。总的来说,浑元OCR标志着向紧凑、指令驱动的OCR引擎的重要转变,这种引擎适合于生产部署。
查看论文、模型权重和代码库。请随意查看我们GitHub教程、代码和笔记本页面。如果您在推特上,请随意关注我们[Twitter](https://x.com/intent/follow?screen name=marktechpost),也不要忘了加入我们的10万名+机器学习SubReddit和订阅我们的新闻通讯。等等!你在电报上吗?现在你可以在电报上也加入我们。
相关文章







