腾讯发布腾讯HY-Motion 1.0:基于扩散Transformer(DiT)架构和流匹配的10亿参数文生成动模型
腾讯浑元3D数字人团队发布了HY-Motion 1.0,这是一个开放权重文本到3D人类动作生成系列,将基于流匹配的Diffusion Transformer扩展到动作领域的10亿参数。这些模型将自然语言提示和期望时长转换为统一SMPL-H骨骼的3D人类动作片段,可在GitHub和Hugging Face上 以代码、检查点和Gradio界面本地使用。
https://arxiv.org/pdf/2512.23464
HY-Motion 1.0为开发者提供了什么?
HY-Motion 1.0是一系列基于扩散Transformer、DiT,用流匹配目标训练的文本到3D人类动作生成模型。该模型系列展示了两款变体,参数为10亿的HY-Motion-1.0作为标准模型和参数为4.6亿的HY-Motion-1.0-Lite作为轻量级选项。
这两种模型都能从简单的文本提示中生成基于骨骼的3D角色动画。输出是SMPL-H骨骼上的动作序列,可集成到3D动画或游戏管线中,例如用于数字化人、电影和交互式角色。发布内容包括推理脚本、面向批处理的CLI和Gradio网络应用,支持macOS、Windows和Linux。
数据引擎和分类法
训练数据来自3个来源,野外人类动作视频、动作捕捉数据和游戏生产的3D动画资产。研究团队从浑元视频的1200万高质量视频剪辑开始,使用场景边界检测将场景分割,并使用人体检测器保持包含人的剪辑,然后应用GVHMR算法重建SMPL X动作轨迹。动作捕捉会议和3D动画库贡献了约500小时的额外动作序列。
所有数据都通过网格拟合和重新定位工具重新定位到统一的SMPL-H骨骼上。一个多阶段过滤器删除了重复剪辑、异常姿态、关节速度异常、异常位移、长静态段和脚滑动等伪影。然后,动作被规范化,在30fps下重新采样,并且以固定世界坐标、Y轴向上、角色面向Z轴正方向的方式分为小于12秒的片段。最终语料库包含超过3000小时的动作,其中400小时是经过验证的高质量3D动作。
在此之上,研究团队定义了一个3级分类法。在顶层有6个分类,动作、体育和田径、健身和户外活动、日常活动、社交互动和休闲与游戏角色动作。这些扩展到叶子中超过200个细粒度动作类别,覆盖了简单的原子动作和并发或顺序的动作组合。
动作表示和HY-Motion DiT
HY-Motion 1.0使用22个身体关节(无手)的SMPL-H骨骼。每帧是一个201维向量,它连接了3D空间中的全局根平移、在连续6D旋转表示中的全局身体方向、21个6D形式中的局部关节旋转和22个3D坐标中的局部关节位置。由于速度和脚接触标签减慢了训练且对最终质量没有帮助,因此已将其删除。该表示与动画工作流程兼容,并与DART模型表示相近。
核心网络是混合HY Motion DiT。它首先应用双流块来分别处理动作潜在变量和文本标记。在这些块中,每个模态有自己的QKV投影和MLP,并联合注意力模块允许动作标记查询来自文本标记的语义特性,同时保持模态特定的结构。然后,网络切换到单流块,将动作和文本标记连接成一个序列,并使用并行空间和通道注意力模块并行处理以执行更深入的多模态融合。
对于文本条件化,系统使用双编码器方案。Qwen3 8B提供标记级嵌入,而CLIP-L模型提供全局文本特征。双向Token Refiner纠正了LLM因果注意偏差,以实现非自回归生成。这些信号通过自适应层归一化条件传递给DiT。注意力是非对称的,动作标记可以注意所有文本标记,但文本标记不回顾动作,这可以防止嘈杂的动作状态污染语言表示。动作分支内的时序注意力使用121帧的窄滑动窗口,这侧重于局部动力学,同时保持了长片段成本的可管理性。在连接文本和动作标记后,应用了全旋转位置嵌入来编码整个序列中的相对位置。
流匹配、提示重写和训练
HY-Motion 1.0使用流匹配代替标准去噪扩散。该模型学习了一条连续路径的移动场,该路径在高斯噪声和真实动作数据之间插值。在训练期间,该路径上预测速度与地面真实速度之间的均方误差是目标。在推理期间,从噪声到干净轨迹的积分是根据该路径上学习到的普通微分方程完成的,这为长序列提供稳定的训练并适应DiT架构。
一个单独的时长预测和提示重写模块改善了指令遵循。它以Qwen3 30B A3B作为基模型,并使用从动作标题和VLM和LLM管道生成的合成的用户风格提示进行了训练,例如Gemini 2.5 Pro。该模块预测合适的动作时长并将非正式提示重写为 complied文本,这是DiT更易于遵循的。它首先用监督微调进行训练,然后用组合奖励的Flow GRPO进一步精细调整。奖励结合来自文本运动检索模型的语义分数和对伪影如脚滑动和根漂移的物理分数,在一个KL正则化项下保持接近监督模型。
训练遵循3阶段课程。第一阶段在完整的3000小时数据集上执行大规模预训练,以学习广泛的动作先验和基本的文本动作对齐。第二阶段在400小时高质量集上微调,以缩小动作细节并改进语义正确性,使用较小的学习率。第三阶段应用强化学习,首先使用9228对从约40000对生成的对中采样的 curated人类偏好对直接偏好优化,然后使用复合奖励的Flow GRPO。
基准、扩展行为和局限性
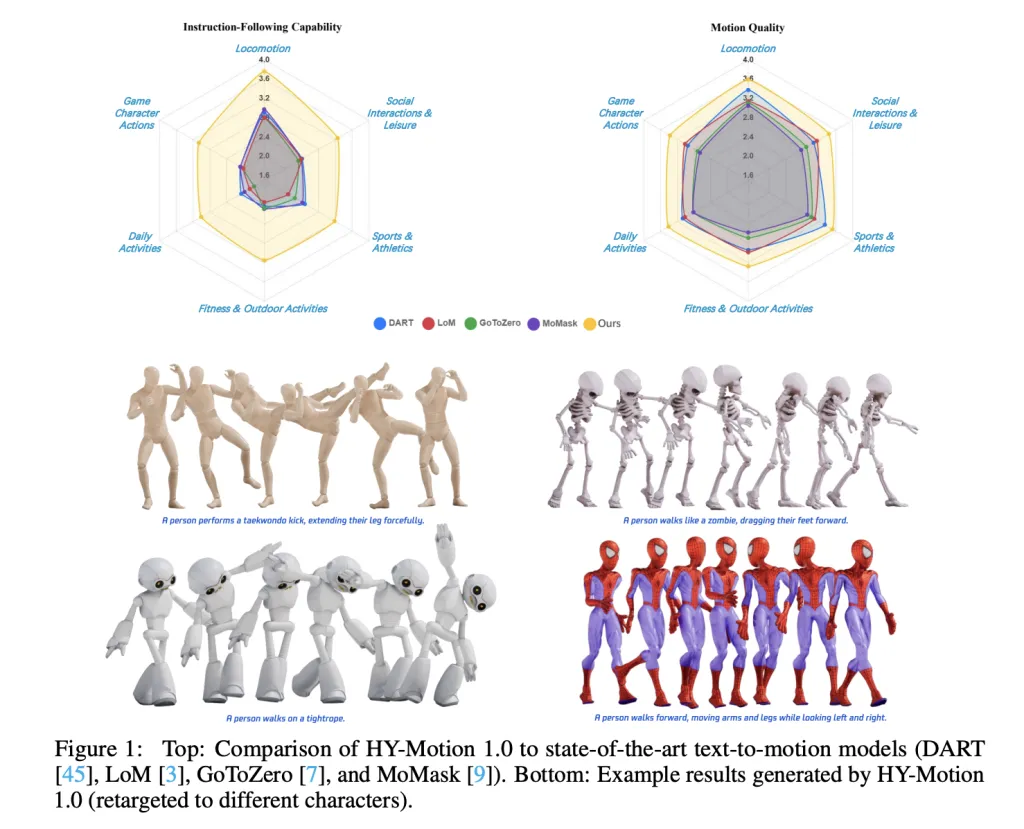
为了评估,团队构建了一个包含超过2000个提示的测试集,这些提示跨越6个分类类别,包括简单、并发和顺序的动作。人工评分者按照从1到5的等级对指令遵循和运动质量进行评分。HY-Motion 1.0的平均指令遵循分数为3.24,SSAE分数为78.6%。基线文本到动作系统如DART、LoM、GoToZero和MoMask在2.17到2.31之间,SSAE在42.7%到58.0%之间。在运动质量方面,HY-Motion 1.0的平均值为3.43,而最佳基线为3.11。
扩展实验研究了0.05B、0.46B、仅用400小时训练的0.46B个参数和1B参数的DiT模型。随着模型大小的增加,指令遵循稳步提高,1B模型的平均值为3.34。运动质量在0.46B的数量级上饱和,其中0.46B和1B模型的平均值在3.26到3.34之间相似。比较了在3000小时上训练的0.46B模型和在400小时上仅训练的0.46B模型,结果表明更大的数据量对于指令对齐至关重要,而高质量整理主要提高了现实感。
主要结论
- 动作的 billions 规模 DiT 流匹配:HY-Motion 1.0是第一个扩展到1B参数水平的基于扩散Transformer的Flow Matching模型,专门针对文本到3D人类动作,旨在在多样化的动作中获得高保真指令遵循。
- 大规模、精选的动作语料库:该模型在超过3000小时的重建、动作捕捉和动画动作数据上预训练,并在400小时高质量子集上微调,所有这些都重新定位到统一的SMPL H骨骼,并组织成超过200个动作类别。
- 混合DiT架构,具有强大的文本条件化:HY-Motion 1.0使用混合双流和单流DiT,具有不对称的注意力、窄带时序注意力和双文本编码器(Qwen3 8B和CLIP L),将标记级和全局语义融合到动作轨迹中。
- 与RL对齐的提示重写和训练流程:一个专用的基于Qwen3 30B的模块预测动作时长并重写用户提示,DiT使用语义和物理奖励通过直接偏好优化和Flow GRPO进一步与监督训练对齐,从而提高现实感和指令遵循。
查看 论文 和 完整代码在这里。 也请随时关注我们的 Twitter 和加入我们的 10k+ ML SubReddit,别忘了订阅 我们的时事通讯。等等!你在 Telegram 上吗?现在你也可以加入我们的团队。
文章 Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching 首先出现在 MarkTechPost。
相关文章







