腾讯研究人员发布腾讯HY-MT1.5:一款拥有1.8亿和7亿参数的新型翻译模型,专为无缝的设备端和云端部署设计。
腾讯混元研究团队发布了HY-MT1.5,这是一款针对移动设备和云系统的多语言机器翻译家族,采用相同的训练方案和指标。HY-MT1.5包含2个翻译模型,HY-MT1.5-1.8B和HY-MT1.5-7B,支持33种语言及5种民族和方言的相互翻译,并在GitHub和Hugging Face上提供开源权重。
模型家族和部署目标
HY-MT1.5-7B是WMT25冠军系统混元MT-7B的升级版本。它针对解释式翻译和混合语言场景进行了优化,并增加了对术语干预、上下文翻译和格式翻译的原生支持。
HY-MT1.5-1.8B是紧凑版。它的参数数量比HY-MT1.5-7B少三分之一,但在报告中提到的基准测试中提供了相当的性能。经量化后,1.8B模型可以在边缘设备上运行,并支持实时翻译。
经过量化的HY-MT1.5-1.8B在约1GB内存的设备上运行,对于大约50个token的中文输入,平均响应时间为约0.18秒,同时在质量上超过了主流的商业翻译API。HY-MT1.5-7B针对服务器和高端边缘部署,在这里,0.45秒的延迟可接受以换取更高的质量。
全面的训练框架
研究团队将HY-MT1.5定义为使用多阶段管道训练的特定于翻译的语言模型。
该管线的5个主要组件如下:
- 通用预训练:基模首先在大型多语言文本上使用语言建模目标进行预训练。这建立了跨语言的共享表示。
- 面向MT的预训练:然后该模型被暴露于平行语料库和针对翻译的目标。这一步骤使生成分布与真实翻译任务保持一致,而不是开放式文本生成。
- 监督微调:使用高质量的句子和文档级平行数据对模型进行微调,以监督损失进行微调。这一阶段加强了直译的正确性、领域覆盖和特定方向的行为,如从中文到英文与从英文到中文。
- 从7B到1.8B的按策略蒸馏:HY-MT1.5-7B被用作HY-MT1.5-1.8B的教师。研究团队收集了33种语言中约100万个单语言提示,将它们通过教师模型运行,并使用反向Kullback-Leibler散度在学生输出上匹配教师分布。这产生了一个1.8B的学生,它在低成本的条件下继承了7B模型的大部分翻译行为。
- 基于评分标准的评估的强化学习:在最终阶段,两种模型都通过一组相对策略优化算法和基于评分标准的奖励模型进行了优化。人类审评员从准确性、流畅性、习惯用语和文化适宜性等多个轴向上对翻译进行评分。奖励模型提炼这些评分并指导策略更新。
这个管线是针对机器翻译的。它与针对聊天的LLM培训不同,因为它结合了以翻译为中心的监督数据、翻译域内的按策略蒸馏以及与细粒度翻译评分标准相结合的RL。
与开放和商业系统的基准测试结果
HY-MT1.5在Flores 200、WMT25以及使用XCOMET-XXL和CometKiwi进行的普通话到少数民族语言的基准测试中对进行了评估。
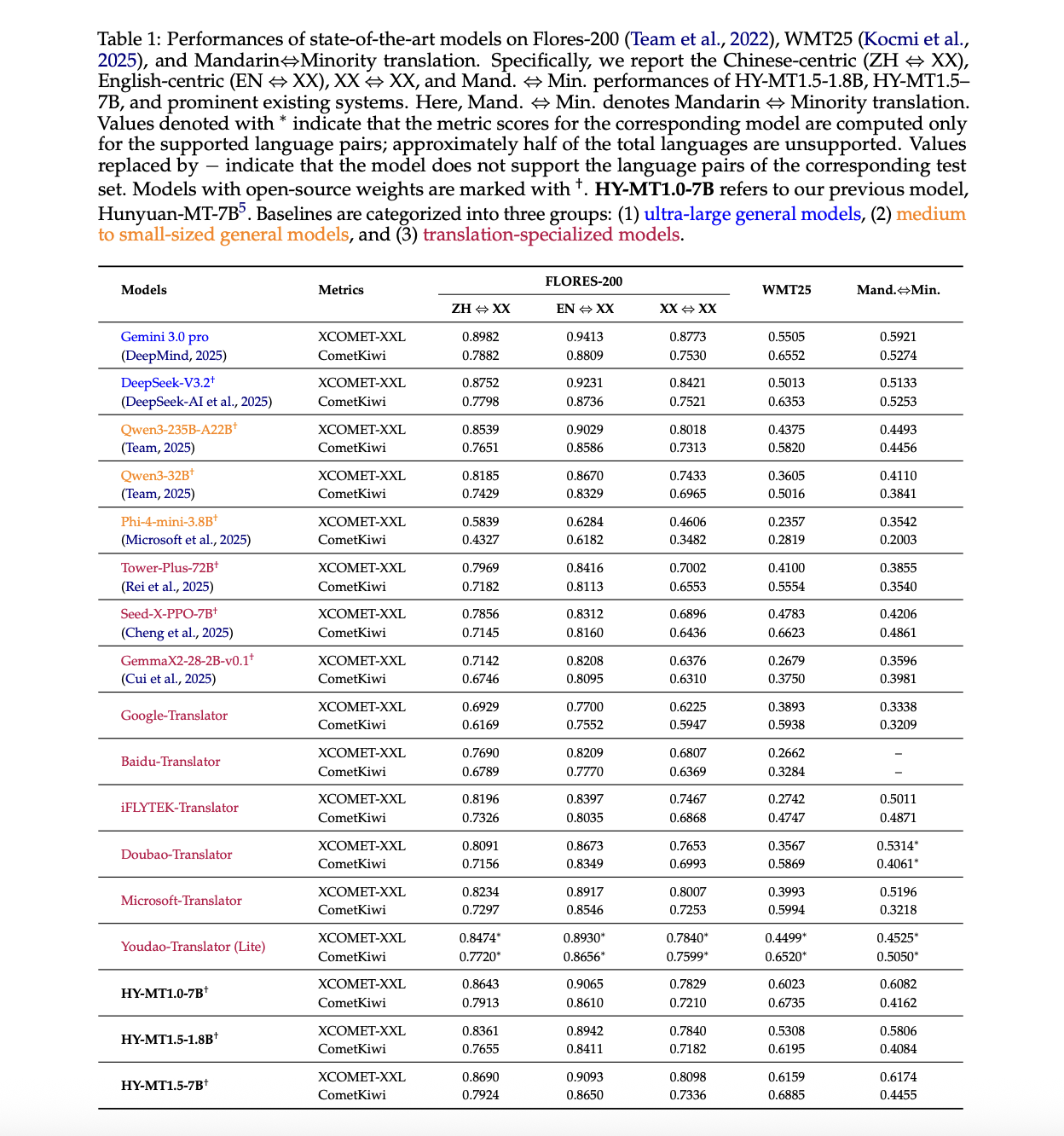
https://arxiv.org/pdf/2512.24092v1
报告中上述表中的一些关键结果:
- 在Flores 200上,HY-MT1.5-7B在ZJ到XX的XCOMET-XXL分数达到0.8690,在EN到XX的分数为0.9093,在XX到XX的分数为0.8098。它优于iFLYTEK翻译器和多宝翻译器等翻译专用模型,并且在Qwen3-235B-A22B等中等规模的一般模型上达到或超过中等水平。
- 在WMT25上,HY-MT1.5-7B在XCOMET-XXL上的分数达到0.6159。这比Gemini 3.0 Pro高出约0.065,远远超过Seed-X-PPO-7B和Tower-Plus-72B等翻译导向模型。1.8B模型的分数为0.5308,仍然超过了许多中等规模的一般模型和翻译系统。
- 在普通话到少数民族语言对上,HY-MT1.5-7B在XCOMET-XXL中达到0.6174,高于所有基线,包括Gemini 3.0 Pro。1.8B变体的分数为0.5806,仍然超过了几个非常大的模型,如DeepSeek-V3.2。
在对中文到英语和英语到中文进行的人评测试中,1.8B模型在0到4的量表上取得了平均分2.74,在相同条件下超过了百度、iFLYTEK、多宝、微软和谷歌翻译系统。
针对产品使用的实用功能
模型公开了三个由提示驱动的功能,这在生产系统中至关重要:
- 术语干预:一个提示模板允许您注入术语映射,例如“混元珠→混沌珍珠”。如果没有映射,模型输出的转写模糊不清。有了映射,它强制执行一致的专业术语。这对于法律、医疗或有品牌限制的内容至关重要。
- 上下文感知翻译:第二个模板接受一个上下文块以及要翻译的句子。报告显示,在上下文缺失的情况下,“pilot”被错误地解释为人。当添加一个关于电视剧的段落时,模型正确地将“pilot”翻译为剧集。
- 保持格式的翻译:第三个模板用
<source>标签包装源,并用<sn>标签标记跨度。指令强制模型保持标签,并在<target>标签内输出。这允许HTML或XML之类的文本在翻译时结构得到保留。
这些作为提示格式实现,因此在通过标准LLM堆栈调用公共权重时也可以使用。
量化和边缘部署
使用GPTQ进行了FP8和Int4后训练量化,对HY-MT1.5-1.8B进行了评估。
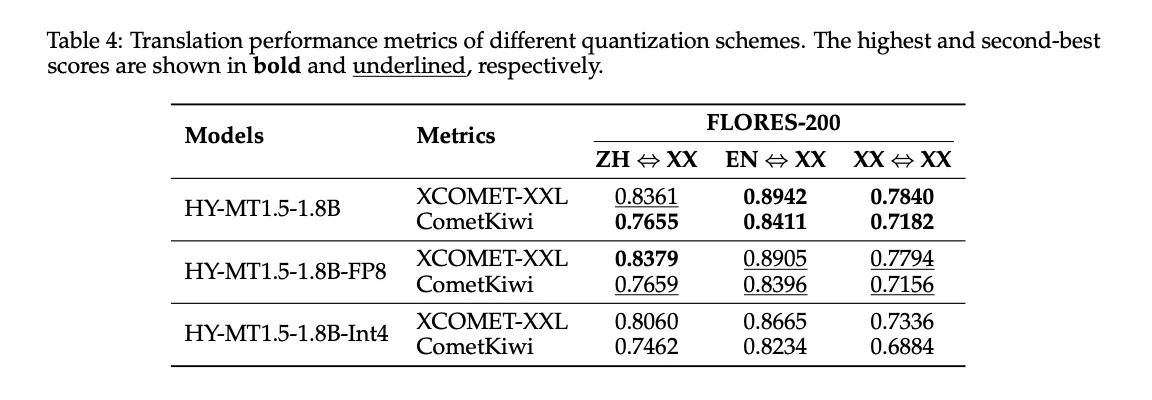
https://arxiv.org/pdf/2512.24092v1
上表4显示:
- FP8将XCOMET-XXL分数保持在满精度模型非常接近,例如,ZH到XX为0.8379与0.8361。
- Int4进一步减少了大小,但使Flores 200上的质量明显下降。
在Hugging Face上,腾讯发布了HY-MT1.5-1.8B和HY-MT1.5-7B的FP8和GPTQ Int4变体,以及GGUF版本供本地推理堆栈使用。量化是允许在1GB内存报告中部署和在消费硬件上低延迟的机制。
主要结论
- HY-MT1.5是一款包含2个模型(HY-MT1.5-1.8B和HY-MT1.5-7B)的翻译家族,支持33种语言及其5种方言或变体形式的相互翻译,在GitHub和Hugging Face上发布了开源权重。
- HY-MT1.5-1.8B是一个基于蒸馏的边缘模型,可以在大约1GB内存上运行,对于大约50个token的中文输入,平均延迟约为0.18秒,同时在相似大小模型的性能上位居行业领先,并超过了大多数商业翻译API。
- HY-MT1.5-7B是一个升级的WMT25冠军系统,在Flores 200上大约达到Gemini 3.0 Pro的95%,在WMT25和普通话少数民族基准测试上超过了它,与许多更大型的开放和封闭模型竞争。
- 两种模型都是通过一个全面的翻译特定管道训练的,该管道结合了通用和面向MT的预训练、监督微调、按策略蒸馏和基于评分标准的评估的RL引导,这对于它们的质量和效率权衡至关重要。
- HY-MT1.5通过提示公开了面向生产的功能,包括术语干预、上下文感知翻译和格式保持翻译,还发布了FP8、Int4和GGUF版本,使团队可以在标准LLM堆栈的设备或服务器上部署。
查看论文,HF上的模型权重和GitHub仓库。同时,请随意关注我们的Twitter,并且别忘了加入我们的10k+ ML SubReddit和订阅我们的Newsletter。等等!你在telegram上吗?现在你可以在telegram上加入我们了。
该帖子Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud Deployment首先出现在MarkTechPost。
相关文章







