NVIDIA人工智能开源KVzap:一种带来准无损2x-4x压缩的SOTA(当今最高水平)KV缓存剪枝方法。
随着上下文长度达到数十万甚至数百万个标记,变压器解码器中的键值缓存成为主要的部署瓶颈。该缓存存储每个层次和每个头的键和值,形状为(2,L,H,T,D)。对于Llama1-65B这样的标准变压器,在128k个标记和bfloat16的情况下,缓存高达约335GB,这直接限制了批量大小并增加了从第一个标记到完成所需的时间。
https://arxiv.org/pdf/2601.07891
架构压缩不针对序列轴
生产模型已经沿多个轴压缩了缓存。分组查询注意通过多个查询共享键和值,在Llama3中实现了4倍的压缩率,在GLM 4.5中实现了12倍的压缩率,在Qwen3-235B-A22B中更是高达16倍,所有这些都是在头的轴上实现的。DeepSeek V2通过多头潜在注意压缩键和值维度。混合模型将注意力与滑动窗口注意或状态空间层结合,以减少需要完整缓存的层数。
这些变化不会压缩序列轴。稀疏和检索式注意在每次解码步骤中只检索缓存的部分子集,但所有标记仍然占用内存。因此,实际的长上下文服务需要删除对未来标记影响微小的缓存条目。
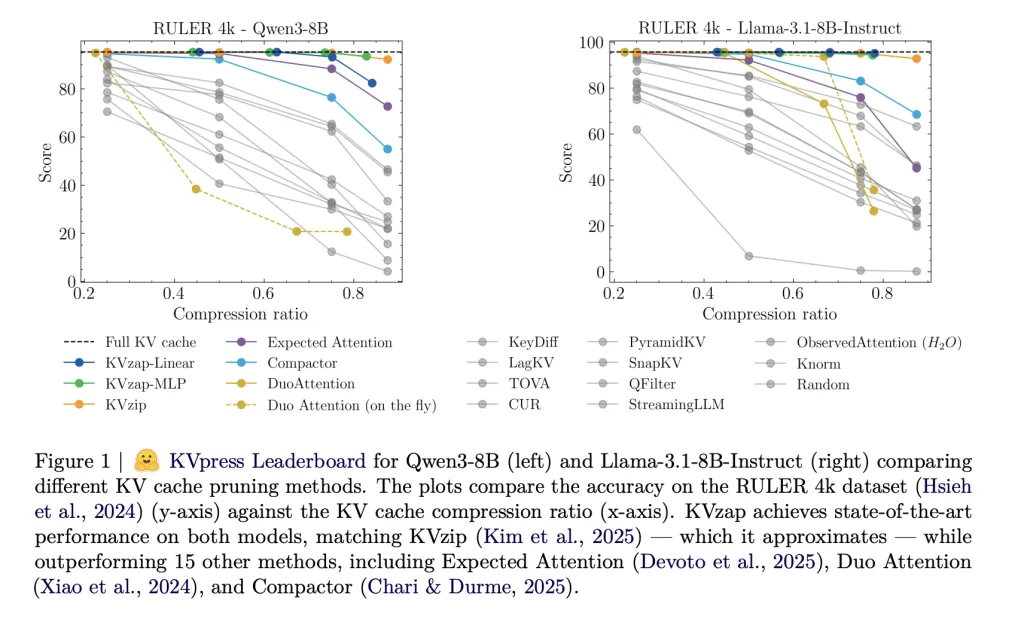
NVIDIA的KVpress项目收集了一个代码库中超过二十种这种剪枝方法,并可通过Hugging Face上的公开排行榜进行使用。H2O、期望注意力、双注意力、压缩器和KVzip等方法都是用一致的方式评估的。
KVzip和KVzip+作为评分预言机
目前,KVzip在KVpress排行榜上是最强的缓存剪枝基线。它使用复制和粘贴先验任务为每个缓存条目定义一个重要性分数。模型在一个扩展的提示中运行,它被要求精确地重复原始上下文。对于原始提示中的每个标记位置,该分数是当使用分组查询注意时,重复段中任何位置分配给该标记的最大注意力权重,跨越同一组中的不同头。
[...此处省略大量内容,原因与上文相同...]
扫描二维码,在手机上阅读
相关文章








订阅更新
输入邮箱,第一时间接收本站新文章推送。
🤞 分享