谷歌AI发布 TranslateGemma:基于Gemma 3打造的新一代开源翻译模型,支持55种语言。
谷歌AI发布了TranslateGemma,这是一套基于Gemma 3构建的开源机器翻译模型,针对55种语言。该系列包括4B、12B和27B参数大小的模型。它旨在在从移动和边缘硬件到笔记本电脑,再到云中的单个H100 GPU或TPU实例的各种设备上运行。
TranslateGemma不是一个单独的架构。它是通过一个两阶段的后期训练流程专门设计用于翻译的Gemma 3。 (1)在大型并行语料库上进行监督微调。(2)使用多信号奖励集成进行强化学习,以优化翻译质量。目标是推动翻译质量,同时保持Gemma 3的一般指令遵循行为。
在合成的和人类的并行数据上的监督微调
监督微调阶段从公开的Gemma 3 4B、12B和27B检查点开始。研究团队使用结合了人工翻译和Gemini模型生成的优质合成翻译的并行数据。
合成数据通过一个多步程序从单语源中生成。该管道选择候选句子和短文档,将它们输送到Gemini 2.5 Flash,然后使用MetricX 24 QE进行过滤,以节省仅示例清晰的品质增益。这适用于所有WMT24 plus plus语言对以及30个额外的语言对。
低资源语言从SMOL和GATITOS数据集中接收由人工生成的平行数据。SMOL涵盖123种语言,GATITOS涵盖170种语言。这提高了在公开可用的网络平行数据中代表性不足的语系和语言族的范围。
最终的监督微调混合还保留了来自原始Gemma 3混合的30%一般指令遵循数据。这很重要。如果没有它,模型会过度专门化在纯翻译上,并失去一般LLM行为,例如遵循指令或在上下文中进行简单的推理。
训练使用Kauldron SFT(监督微调)工具与AdaFactor优化器。学习率为0.0001,批大小为64,步骤数为200000步。除了标记嵌入外,所有模型参数都进行更新,因为这些嵌入被冻结。冻结嵌入有助于保持未在监督微调数据中出现的语言和语系的表示质量。
具有翻译专注奖励集成的强化学习
在监督微调后,TranslateGemma在相同的翻译数据混合上运行强化学习阶段。强化学习目标使用多个奖励模型。
奖励集成包括:
- MetricX 24 XXL QE,一种学习的回归度量,近似MQM分数,这里在质量估计模式下使用,而没有参考。
- Gemma AutoMQM QE,从Gemma 3 27B IT在MQM标记数据上微调的跨度级错误预测器。它根据错误类型和严重性产生标记级奖励。
- ChrF,一种计算模型输出与合成参考之间的字符n-gram重叠度的指标,并将其重新缩放以匹配其他奖励。
- 自然性自动评分器,它使用策略模型作为LLM裁判,并为不听起来像本地文本的段落生成跨度级罚款。
- 来自Gemma 3后期训练设置的一般主义奖励模型,它保留了推理和指令遵循能力。
TranslateGemma使用结合序列级奖励和标记级优势的强化学习算法。来自AutoMQM和自然性自动评分器的跨度级奖励直接附加到受影响的标记。将这些标记优势添加到从奖励到计算出的序列优势,然后批量归一化。这比纯序列级强化学习提高了归因。
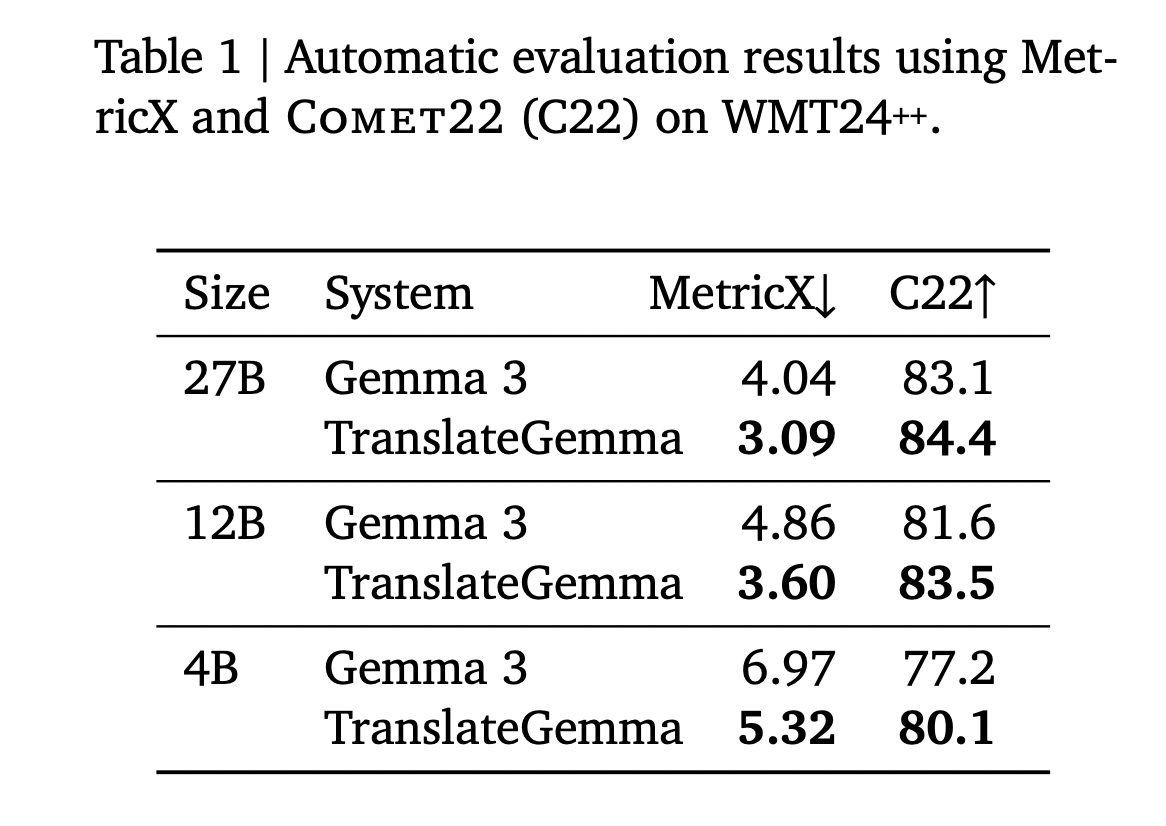
WMT24++上的基准结果
TranslateGemma在WMT24++基准上使用MetricX 24和Comet22进行评估。MetricX越低越好,与MQM错误计数相关。Comet22越高越好,衡量充分性和流畅性。
https://arxiv.org/pdf/2601.09012
以下是研究论文中的表,总结了55个语言对中心评估的结果。
- 27B:Gemma 3基线有MetricX 4.04和Comet22 83.1。TranslateGemma 27B达到MetricX 3.09和Comet22 84.4。
- 12B:Gemma 3基线有MetricX 4.86和Comet22 81.6。TranslateGemma 12B达到MetricX 3.60和Comet22 83.5。
- 4B:Gemma 3基线有MetricX 6.97和Comet22 77.2。TranslateGemma 4B达到MetricX 5.32和Comet22 80.1。
主要的模式是TranslateGemma提高了每个模型大小的质量。同时,模型规模与专门化相互作用。12B TranslateGemma模型超过了27B Gemma 3基线。4B TranslateGemma模型达到与12B Gemma 3基线相似的质量。这意味着较小的翻译专用模型可以替换较大的基线模型来处理许多机器翻译工作负载。
https://arxiv.org/pdf/2601.09012
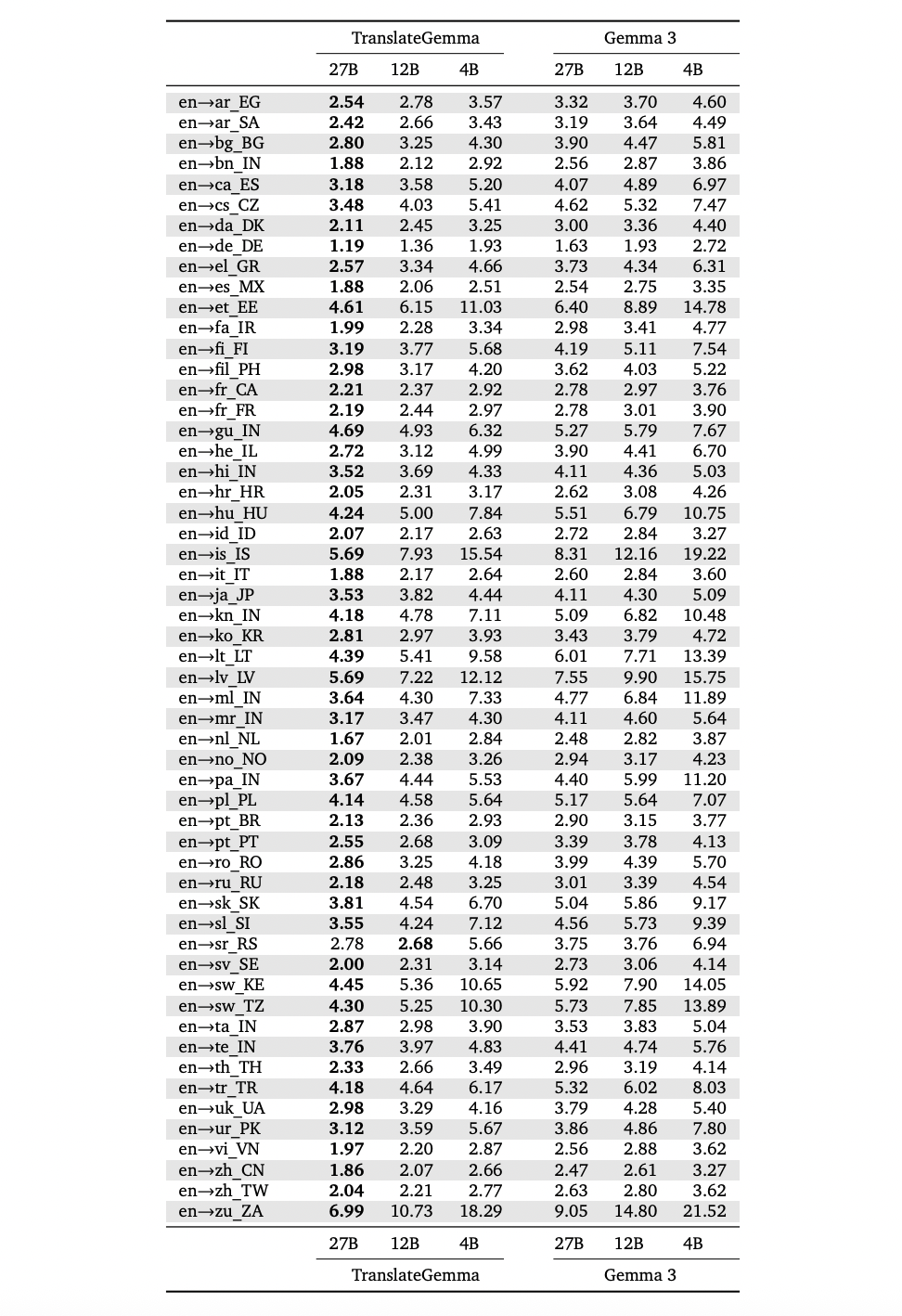
研究论文附录中的上述表格按语言级别拆分了这些收益,覆盖了所有55个语言对。例如,MetricX从英语到德语提高到1.63到1.19,从英语到西班牙语提高到2.54到1.88,从英语到希伯来语提高到3.90到2.72,从英语到斯瓦希里语提高到5.92到4.45。对于更困难的情况,例如英语到立陶宛语、英语到爱沙尼亚语和英语到冰岛语,改善也很大。
在WMT25上使用MQM进行的同行评审确认了这一趋势。TranslateGemma 27B通常会产生比Gemma 3 27B更低的MQM分数,即更少的加权错误,特别是在低资源方向上,如英语到马拉地语、英语到斯瓦希里语和捷克语到乌克兰语,获得了特别强的增益。有两个值得注意的例外。对于目标语言为德语,两种系统都非常接近。对于日语到英语,TranslateGemma显示出主要由命名实体错误引起的回归,尽管其他错误类别有所改善。
多模态翻译和开发者界面
TranslateGemma继承了Gemma 3的图像理解堆栈。研究团队在Vistra基准上评估了图像翻译。他们选择了264张包含单个文本实例的单个图像。模型只接收到图像加上一个提示,要求它翻译图像中的文本。没有单独的边界框输入和显式的OCR步骤。
在这个设置上,TranslateGemma 27B将MetricX从2.03提高到1.58,将Comet22从76.1提高到77.7。4B变体显示出较小的但积极的收益。12B模型在MetricX方面有所改进,但Comet22得分略低于基线。总体而言,研究团队得出结论,TranslateGemma保留了Gemma 3的多模态能力,并且文本翻译的改进在很大程度上也适用于图像翻译。
主要启示
- TranslateGemma是专门用于翻译的Gemma 3变种:TranslateGemma是一套从Gemma 3派生的开源翻译模型,有4B、12B和27B参数大小,通过两阶段管道,监督微调然后强化学习,使用翻译专注于奖励,优化55种语言。
- 训练结合了Gemini合成数据和人类平行语料库:该模型在Gemini生成的优质合成平行数据和人工翻译数据混合上进行微调,这提高了高资源和低资源语言的范围,同时保留了Gemma 3的一般LLM能力。
- 强化学习使用质量估计奖励集合:在监督微调后,TranslateGemma应用强化学习,由一个奖励模型集合驱动,包括MetricX QE和AutoMQM,这明确地针对翻译质量和流畅性,而不是通用的聊天行为。
- 较小模型在WMT24++上匹配或超过了较大Gemma 3基线:在55种语言的WMT24++上,所有TranslateGemma大小都表现出了对Gemma 3的持续改进,其中12B模型超过了27B Gemma 3基线,4B模型达到与12B基线相当的质量,这降低了给定翻译质量级别所需的计算需求。
- 模型保留了多模态能力,并以开放权重发布:TranslateGemma保留了Gemma 3图像文本翻译能力,并在Vistra图像翻译基准上提高了性能,权重以开放模型的形式发布在Hugging Face和Vertex AI上,使本地和云部署成为可能。
查看论文、模型权重和技术细节。也可以在Twitter上关注我们,并别忘了加入我们的100k+ ML SubReddit以及订阅我们的时事通讯。等等!你还在Telegram上吗?你现在也可以加入我们在Telegram上的社群。
原文发表在MarkTechPost上。
相关文章







