NVIDIA发布PersonaPlex-7B-v1:一款专为自然和对偶式对话设计的实时语音转语音模型
NVIDIA研究人员发布了PersonaPlex-7B-v1,这是一款面向完整全双工语音到语音对话模型,旨在实现具有精确角色控制的自然录音交互。
从ASR→LLM→TTS到一个单一的完整双工模型
传统的语音助手通常采用级联模式。自动语音识别(ASR)将语音转换为文本,语言模型生成文本答案,文本到语音(TTS)再次将其转换回音频。每个阶段都会增加延迟,且该管道无法处理重叠的语音、自然的干扰或密集的后渠道。
PersonaPlex用单个Transformer模型取代了这个堆栈,该模型在一个网络中执行流式语音理解和语音生成。模型在神经编解码器编码的连续音频上操作,并自回归地预测文本标记和音频标记。用户音频被增量编码,而PersonaPlex同时生成自己的语音,这实现了闯入、重叠、快速轮流和情境性后渠道。
PersonaPlex以双流配置运行。一个流跟踪用户音频,另一个流跟踪代理语音和文本。两个流共享相同的模型状态,因此代理可以在说话时继续监听,并根据用户的打断调整其回答。这种设计直接受到了Kyutai的Moshi全双工框架的启发。
混合提示、语音控制和角色控制
PersonaPlex使用两个提示来定义对话身份。
- 语音提示是一系列音频标记,编码了音质、说话风格和语调。
- 文本提示描述了角色、背景、组织信息和情境上下文。
共同,这些提示限制了代理的语言内容和声学行为。在此基础上,一个系统提示支持名称、业务名称、代理名称和业务信息等字段,最多可达200个标记。
架构、氦网络骨干和音频路径
PersonaPlex模型具有70亿个参数,遵循Moshi网络架构。一个结合了ConvNet和Transformer层的Mimi语音编码器将波形音频转换为离散标记。时间和深度Transformer处理代表用户音频、代理文本和代理音频的多通道。一个结合了Transformer和ConvNet层的Mimi语音解码器生成输出的音频标记。音频以24 kHz的采样率进行输入和输出。
PersonaPlex基于Moshi权重,使用氦作为底层语言模型骨干。氦提供语义理解,并支持超监督对话场景之外的一般化。这在“空间紧急”的例子中很明显,关于火星任务中反应堆核心失败的提示导致了符合适当情感调调的连贯技术推理,尽管这种情况不属于训练分布。
训练数据混合、真实对话和合成角色
训练分一个阶段,并使用真实和合成对话的混合。
真实对话来自Fisher英语语料库中的7,303个电话,大约1,217小时。这些对话使用GPT-OSS-120B进行后标注,带有提示,提示从简单的角色提示(如“你享受拥有愉快的谈话”)到包含生平、地点和偏好的较长的描述。这个语料库提供了从TTS单独获取的自然后渠道、不流畅的部分、停顿和情绪模式。
合成数据涵盖助手和客户服务角色。NVIDIA团队报告了约410小时的39,322个合成助手对话,以及约1,840小时的105,410个合成客户服务对话。Qwen3-32B和GPT-OSS-120B生成转录本,Chatterbox TTS将它们转换为语音。对于助手互动,文本提示固定为“你是一位智慧而友好的教师。用明确和吸引人的方式回答问题或提供建议。”对于客户服务场景,提示编码了组织、角色类型、代理名称和结构化业务规则,如定价、时间和约束。
这种设计让PersonaPlex将来自Fisher的自然对话行为与来自合成场景的任务遵守和角色条件分开。
在FullDuplexBench和服务DuplexBench上的评估
PersonaPlex在FullDuplexBench上进行了评估,这是一个全双工说话对话模型的基准,还在一个新的扩展ServiceDuplexBench上进行评估,用于客户服务场景。
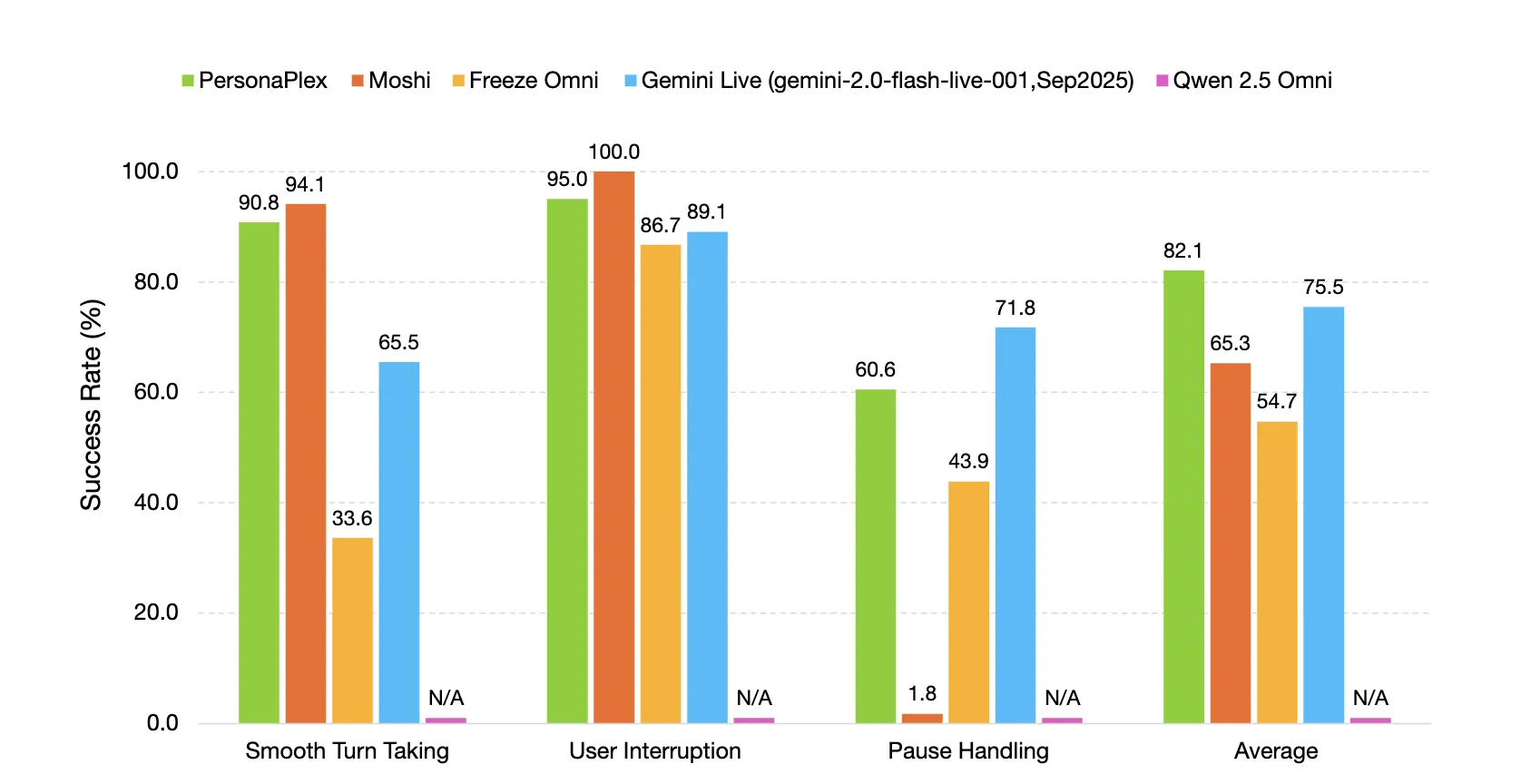
FullDuplexBench使用接管率和延迟指标,如平滑轮流、用户干扰处理、暂停处理和后渠道,来衡量对话动态。GPT-4o作为问题回答类别中的LLM裁判员。PersonaPlex在用户干扰子集上实现了0.908的平滑轮流接管率,延迟为0.170秒,以及0.950的用户干扰接管率和0.240秒的延迟。语音提示和输出之间的说话者相似度使用WavLM TDNN嵌入,达到了0.650。
在助手机器和客户服务角色中,PersonaPlex在对话动态、响应延迟、干扰延迟和任务遵守方面优于许多其他开源和封闭系统。
https://research.nvidia.com/labs/adlr/personaplex/
关键要点
- PersonalityPlex-7B-v1是NVIDIA的一个70亿参数全双工语音到语音对话模型,基于Moshi架构和有氦语言模型作为骨干,代码在MIT下,权重在NVIDIA开放模型许可下。
- 模型使用双流Transformer和24 kHz的Mimi语音编码器/解码器,将连续音频编码为离散标记,并同时生成文本和音频标记,这实现了闯入、重叠、快速轮流和自然后渠道。
- 通过混合提示进行角色控制,由音频标记组成的声音提示设定音色和风格,文本提示和最多200个标记的系统提示定义角色、业务上下文和约束,还有像NATF和NATM家族那样的预先制作的语音嵌入。
- 训练使用来自Fisher的7,303个对话,大约1,217小时,并结合使用GPT-OSS-120B进行注释,以及约410小时的合成助手对话和约1,840小时的合成客户服务对话,这些对话使用Qwen3-32B和GPT-OSS-120B生成,并用Chatterbox TTS渲染,这将对话的自然性从任务遵守中分离出来。
- 在FullDuplexBench和服务DuplexBench上,PersonaPlex实现了0.908的平滑轮流接管率和0.950的用户干扰接管率,延迟低于一秒,并改善了任务遵守。
查看技术细节、模型权重和代码库。请随意在Twitter上关注我们,也请加入我们的100k+机器学习SubReddit并订阅我们的新闻通讯。等一下!你在Telegram上吗?现在你也可以加入我们了。
文章NVIDIA发布PersonaPlex-7B-v1:一款适用于自然和全双工对话的实时语音到语音模型首次发表于MarkTechPost。
相关文章







