FlashLabs 研究人员发布 Chroma 1.0:一个具有个性化语音克隆的 4B 实时语音对话模型
Chroma 1.0是一种实时语音到语音对话模型,它将音频作为输入并返回音频作为输出,在多轮对话中保留说话人的身份。它被呈现为首个开源的端到端说话人对话系统,该系统结合了低延迟交互和仅从几秒钟的参考音频中实现的碩效个性化声音克隆。
该模型直接在离散的语音表示上运行,而不是在文本记录上。它与商业实时代理具有相同的目标用例,但具有紧凑的4B参数对话核心和将说话人相似度视为主要目标而不是辅助功能的设计。Chroma实现了10.96%的相对改善,在人体基准测试中获得了10.96%的说话人相似度,并且达到实时因子(RTF)为0.43,因此它可以产生比回放快2倍的语音。
https://arxiv.org/pdf/2601.11141
从级联ASR  LLM TTS 到端到端S2S
LLM TTS 到端到端S2S
大多数生产助手仍然使用三个阶段的管道,自动语音识别将音频转换为文本,大型语言模型进行推理,以及文本到语音合成。这种结构很灵活,但它引入了延迟,并在系统将音频压缩成文本时丢失了音色、情感、语速和韵律等旁白信息。在实时对话中,这种声学细节的丧失会直接损害说话人的保真度和自然度。
Chroma遵循映射到编解码器令牌序列之间的最新语音到语音系统。一个语音标记器和神经网络编解码器产生量化声学代码。然后,语言模型在交织文本标记和音频代码的序列上进行推理和响应,而不需要显式的中间转录本。这在整个处理链中使模型对韵律和说话人身份保持条件化。
架构、推理器+语音生成堆栈
Chroma 1.0有两个主要子系统。Chroma Reasoner处理多模态理解和文本生成。语音堆栈,Chroma Backbone、Chroma Decoder和Chroma Codec Decoder,将语义输出转换为个性化的响应音频。
Chroma Reasoner建立在Qwen-omni系列的Thinker模块之上,并使用Qwen2音频编码管道。它使用共享前端处理文本和音频输入,通过交叉模态注意力融合它们,并使用时间对齐的多模态旋转位置嵌入(TM-RoPE)在时间上对齐它们。输出是一个包含语言内容和声学提示的隐藏状态序列,例如节奏和强调。

https://arxiv.org/pdf/2601.11141
Chroma Backbone是一个基于Llama3的1B参数LLaMA风格模型。它使用CSM-1B对目标声音进行条件设置,将短暂的参考音频剪辑及其转录本编码到嵌入提示中,这些提示在序列之前附加。在推理期间,来自推理器的标记嵌入和隐藏状态作为统一上下文提供,因此骨架在生成声学代码时始终看到对话的语义状态。
为了支持流媒体,系统使用固定的1到2交错计划。对于来自推理器的每个文本标记,骨架产生2个声学代码标记。这使得模型可以在文本生成开始时立即开始发出语音,并避免了等待完整的句子。这种交错是低时间到第一个标记背后的主要机制。
Chroma Decoder是一个约100M参数的轻量级LLaMA变体。骨架一次仅预测每个帧中每个残差向量量化代码簿的第一个代码,这是一个粗略的表示。然后解码器采用骨架隐藏状态和第一个代码,并自回归地预测同一帧内剩余的RVQ级别。这种分解在骨架中保持了长远的时间结构,并将解码器限制在帧局部细化,这降低了计算量并提高了详细的韵律和发音。
Chroma Codec Decoder将粗略和精细的代码连接起来,并将它们映射到波形样本上。它遵循Mimi声码器的解码器设计,并使用因果卷积神经网络,以便每个输出样本仅依赖于过去上下文,这对流媒体是必需的。系统使用8个代码簿,这降低了解码器的自回归细化步骤的数量,同时保留了对声音克隆足够多的细节。
训练设置和合成语音到语音(S2S)数据
高质量且具有强大推理信号的语音对话数据很少。因此,Chroma使用合成语音到语音(S2S)管道。类似LLM的推理器首先为用户问题生成文本答案。然后,TTS系统将这些答案的匹配参考音频的音色进行语音合成。这些合成对训练骨架和解码器执行声学建模和声音克隆。推理器冻结并充当文本嵌入和多模态隐藏状态提供者。
声音克隆质量和与现有系统的比较
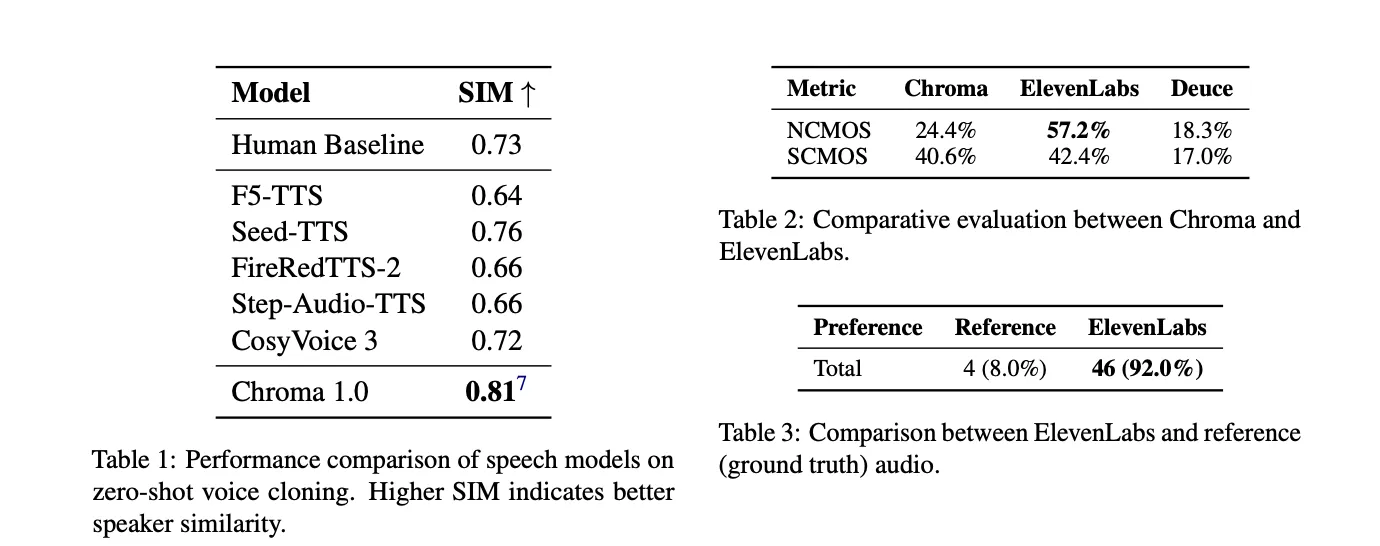
使用SEED-TTS-EVAL准则在英语CommonVoice说话人上进行客观评估。Chroma以24kHz采样率运行,实现了0.81的说话人相似度得分。人造基准是0.73。CosyVoice-3达到0.72,而多数其他TTS基准低于人体参考。研究小组将这报告为相对于人体基准的10.96%的相对改善,这表明该模型比在该度量标准下的人体录音更一致地捕获细微的旁白细节。
https://arxiv.org/pdf/2601.11141
主观评估将Chroma与ElevenLabs eleven_multilingual_v2模型进行比较。在自然度CMOS中,57.2%的时间听众更喜欢ElevenLabs,而Chroma为24.4%,18.3%为平局。在说话人相似度CMOS中,得分非常接近,ElevenLabs为42.4%,Chroma为40.6%,平局为17.0%。随后的一项测试询问ElevenLabs和原始录音中哪个音频听起来更自然,结果ElevenLabs获得92.0%的选择,而原始录音仅获得8.0%,这表明感知的自然度和说话人保真度不一致。
延迟和实时行为
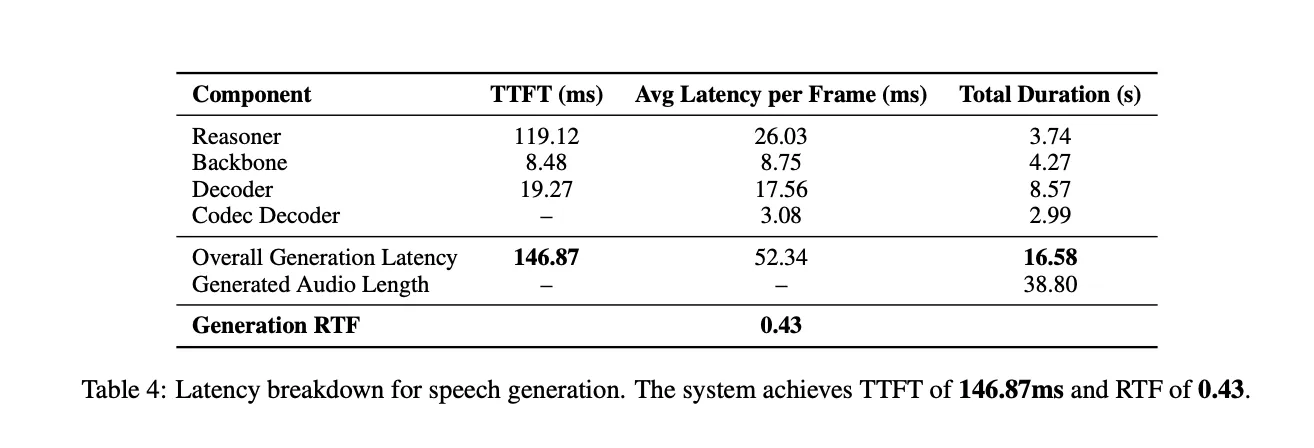
使用一个并发流测量延迟。对于38.80秒的响应,总生成时间为16.58秒,这意味着实时因子(RTF)为0.43。推理器贡献了119.12 ms的TTFT,骨架平均为每帧8.48 ms,解码器平均为19.27 ms。Codec Decoder在4帧的组上工作,因此TTFT不适用于该组件。总体时间到第一个标记为146.87 ms,低于一秒,适用于交互式对话。
https://arxiv.org/pdf/2601.11141
重要的是,Chroma是此比较中唯一支持个性化声音克隆的模型。所有其他系统仅关注说话人和推理。这意味着Chroma在提供有竞争力的认知能力的同时,也能在实时内执行高保真的声音个性化。
关键见解
- 端到端实时语音到语音:Chroma 1.0是一个4B参数的语音对话模型,它直接使用编解码器令牌将语音映射到语音,它避免了显式的ASR和TTS阶段,并通过整个管道保留了韵律和说话人身份。
- 推理器加语音堆栈架构:该系统结合了基于Qwen的Chroma推理器和1B参数的LLaMA风格骨架、100M参数的Chroma解码器和一个基于Mimi的Codec解码器,它使用RVQ代码簿和一个交织的1到2文本到音频标记计划来支持流媒体和低时间到第一个标记。
- 强大的个性化声音克隆:在SEED-TTS-EVAL和CommonVoice说话人上,Chroma在24kHz下达到0.81的说话人相似度得分,这被报告为相对于0.73的人体基准的10.96%的相对改善,并优于CosyVoice 3和其他TTS基准。
- 亚秒级延迟和比实时生成更快:在H200 GPU上的单流推理大约需要147毫秒的时间到第一个标记,对于38.80秒的响应,模型在16.58秒内生成音频,这意味着实时因子为0.43,比回放快了2倍。
- 具有克隆作为独特功能的竞争对话和推理:在URO Bench基本轨道上,Chroma实现57.44%的整体任务完成率,在Storal、TruthfulQA、GSM8K、MLC和CommonVoice上得分具有竞争力。
查看论文、模型权重、项目和沙箱。还可以自由地在Twitter上关注我们,并不要忘记加入我们的100k+ MLSubReddit并订阅我们的时事通讯。等等!你在电报上吗?现在你也可以加入我们的电报群组。
这篇关于FlashLabs研究人员发布Chroma 1.0:一个4B的实时语音对话模型,带个性化声音克隆的文章首次出现在MarkTechPost。
相关文章







