NVIDIA AI将Nemotron-3-Nano-30B引入NVFP4,通过量化感知蒸馏(QAD)实现高效的推理推理。
NVIDIA发布Nemotron-Nano-3-30B-A3B-NVFP4,实现近似博格标准精度,同时保持接近BF16基线的准确度
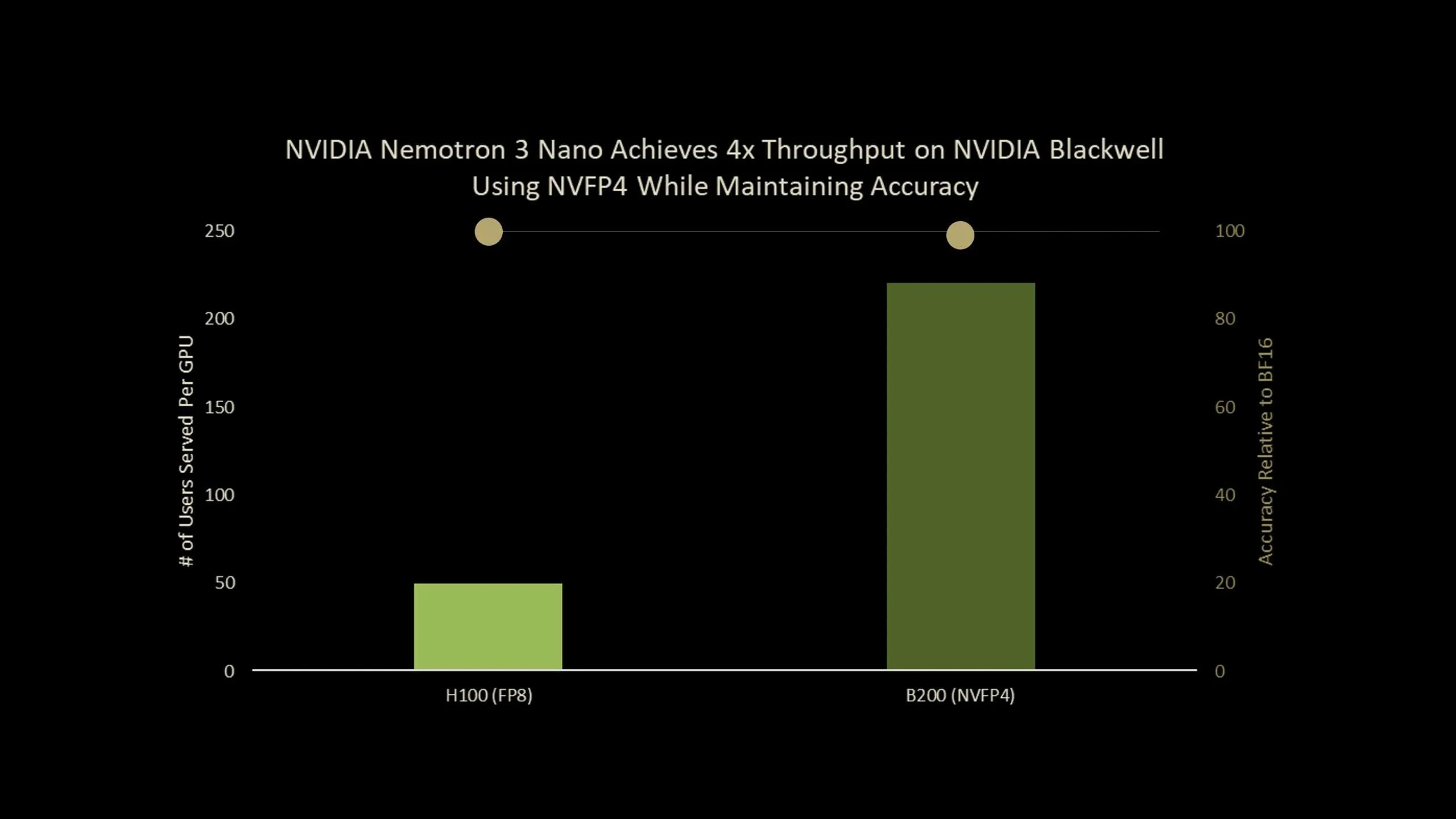
NVIDIA已发布生产性检查点Nemotron-Nano-3-30B-A3B-NVFP4,该检查点以4位NVFP4格式运行30B参数推理模型,同时保持了与BF16基线接近的准确性。该模型结合了混合Mamba2 Transformer Mixture of Experts架构和专为NVFP4部署设计的量化感知蒸馏(QAD)方案。总体而言,它是Nemotron-3-Nano的NVFP4超高效精度版本,在Blackwell B200上的吞吐量最高可提高4倍。
{kind=link}
https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
Nemotron-Nano-3-30B-A3B-NVFP4是什么?
Nemotron-Nano-3-30B-A3B-NVFP4是NVIDIA团队从头开始训练的Nemotron-3-Nano-30B-A3B-BF16量化版本,作为统一推理和聊天模型。它构建为一个混合Mamba2 Transformer MoE网络:
- 总共30B个参数
- 深度为52层
- 23个Mamba2和MoE层
- 6个分组的查询注意力层,每2组一个
- 每个MoE层有128个路由专家和1个共享专家
- 每个token有6个激活的专家,每个token约3.5B个活动参数
该模型使用Warmup Stable Decay学习率计划在25T个token上进行预训练,批量大小为3072,最大学习率为1e-3,最小学习率为1e-5。
训练后遵循3个阶段的流程:
- 在代码、数学、科学、工具调用、指令跟随和结构化输出的人工合成了数据上监督微调。
- 在多步工具使用、多轮聊天和结构化环境中进行强化学习,以及RLHF和生成奖励模型。
- 进行后训练量化到NVFP4,使用FP8 KV缓存和选择性高精度布局,然后进行QAD。
NVFP4检查点保持注意力层和其馈入的Mamba层为BF16,将剩余层量化为NVFP4,并使用FP8进行KV缓存。
NVFP4格式及其重要性
NVFP4是一种为在最新NVIDIA GPU上进行训练和推理而设计的4位浮点格式。NVFP4的主要特性:
- 与FP8相比,NVFP4提供2到3倍的算术吞吐量。
- 通过约1.8倍减少权重和激活的内存使用。
- 通过将块大小从32减少到16来扩展MXFP4,并引入了两级缩放。
两阶缩放使用每个块E4M3-FP8缩放和每个张量FP32缩放。较小的块大小允许量化器适应局部统计信息,双重缩放在保持量化误差低的同时增加动态范围。
对于非常大的LLM,简单的后训练量化(PTQ)到NVFP4已在基准测试中给出相当好的准确性。对于较小的模型,特别是大量使用邮递管道的模型,研究团队指出,PTQ会导致不可忽视的准确性下降,这促使他们采用基于训练的恢复方法。
从QAT到QAD
标准的量化感知训练(QAT)在正向传递中插入伪量化并重复使用原始任务损失,例如下一个token交叉熵。这对于卷积网络来说效果不错,但研究团队为现代LLM列举了2个主要问题:
- 复杂的多阶段后训练管道,如SFT、RL和模型合并,很难重现。
- 开放模型的原始训练数据通常不可用。
量化感知蒸馏(QAD)更改目标而不是整个流程。一个冻结的BF16模型充当教师,NVFP4模型是一个学生。以最小化两个输出token分布之间的KL散度来训练,而不是原始的监督或RL目标。
研究成果强调QAD的3个特性:
- 它比QAT更准确地使量化模型与高精度教师对齐。
- 即使教师在已经经历了几个阶段,如监督微调、强化学习和模型合并,它也能保持稳定,因为QAD只尝试匹配最终的教师行为。
- 它可以与部分、合成的或过滤的数据一起使用,因为它只需要输入文本来查询教师和学生,而不是原始标签或奖励模型。
Nemotron-3-Nano-30B的基准测试
Nemotron-3-Nano-30B-A3B是QAD研究中.argmax重模型之一。以下表格显示了NVFP4-QAT和NVFP4-QAD在AA-LCR、AIME25、GPQA-D、LiveCodeBench-v5和SciCode-TQ上的准确性。
{kind=link}
https://research.nvidia.com/labs/nemotron/files/NVFP4-QAD-Report.pdf
主要结论
- Nemotron-3-Nano-30B-A3B-NVFP4是一个以4位NVFP4运行、FP8 KV缓存和少量BF16层以保持稳定性的30B参数混合Mamba2 Transformer MoE模型,每个token大约有3.5B个活动参数,并支持最多1M个token的上下文窗口。
- NVFP4是一种4位浮点格式,具有16字节的块大小和两级缩放,使用每个块E4M3-FP8缩放和每个张量FP32缩放,与FP8相比,在权重和激活方面提供约2到3倍的算术吞吐量和约1.8倍较低的内存消耗。
- 量化感知蒸馏(QAD)使用KL散度替换了原始任务损失,以与冻结的BF16教师进行匹配,因此NVFP4学生直接匹配教师输出分布,而不需要播放完整的SFT、RL和模型合并流程或需要原始奖励模型。
- 使用新的量化感知蒸馏方法,NVFP4版本实现了高达99.4%的BF16精度。
- 在AA-LCR、AIME25、GPQA-D、LiveCodeBench和SciCode上,NVFP4-PTQ显示出可观的准确性损失,NVFP4-QAT进一步恶化,而NVFP4-QAD将性能恢复到接近BF16的水平,将这些推理和编码基准测试中的差距减少到只有几个点。
阅读完整论文和模型权重。也欢迎关注我们的Twitter,不要忘记加入我们的100k+ ML SubReddit和订阅我们的Newsletter。等等!你在Telegram上吗?[现在你可以在Telegram上加入我们了。](https://t.me/machinelearningresearchnews)
原文链接:NVIDIA AI将Nemotron-3-Nano-30B带入NVFP4,使用量化感知蒸馏(QAD)以提高高效推理。
相关文章







