元实验室AI发布Yuan 3.0 Ultra:一款旗舰级的多样化MoE基础模型,专为更强的智能和无可比拟的效率而构建。
元实验室AI发布了Yuan3.0 Ultra,一个开源的专家混合(MoE)大型语言模型,总参数量为1T,激活参数量为68.8B。该模型架构旨在优化特定于企业的任务性能,同时保持有竞争力的通用能力。与传统的密集模型不同,Yuan3.0 Ultra利用稀疏化来扩展能力,而不需要线性增加计算成本。
层自适应专家剪枝(LAEP)
Yuan3.0 Ultra训练中的主要创新是层自适应专家剪枝(LAEP)算法。尽管专家剪枝通常在训练后应用,但LAEP在预训练阶段直接识别并移除利用率低的专家。
专家负载分布的研究显示,预训练中有两个不同的阶段:
- 初始过渡阶段:以从随机初始化继承的高度波动性的专家负载为特征。
- 稳定阶段:专家负载收敛,基于token分配的专家相对排名在大部分情况下保持固定。
一旦达到稳定阶段,LAEP基于两个约束进行剪枝:
- 个体负载约束(⍺):针对token负载显著低于层平均的专家。
- 累积负载约束(β):识别出对总token处理贡献最小的专家子集。
通过使用β=0.1和变化的⍺,模型从最初的1.5T参数剪枝到1T参数。这种33.3%的总参数减少在保留了模型的多领域性能的同时,显著降低了部署所需的内存要求。在1T配置中,每层的专家数量从64减少到最多48个保留专家。
https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra/blob/main/Docs/Yuan3.0_Ultra_Paper.pdf
硬件效率和专家重排
MoE模型在专家分布在一个计算集群上时,通常会在设备层面遭受负载不平衡。为了解决这个问题,Yuan3.0 Ultra实施了一个专家重排算法。
该算法根据token负载对专家进行排序,并使用贪婪策略将它们分配到GPU上,以使累积token方差最小化。
| 方法 | 每GPU TFLOPS |
|---|---|
| 基础模型(1515B) | 62.14 |
| DeepSeek-V3 辅助损失 | 80.82 |
| Yuan3.0 Ultra(LAEP) | 92.60 |
总的预训练效率提高了49%。这种改进归因于以下两个因素:
- 模型剪枝:对效率增益的贡献为32.4%。
- 专家重排:对效率增益的贡献为15.9%。
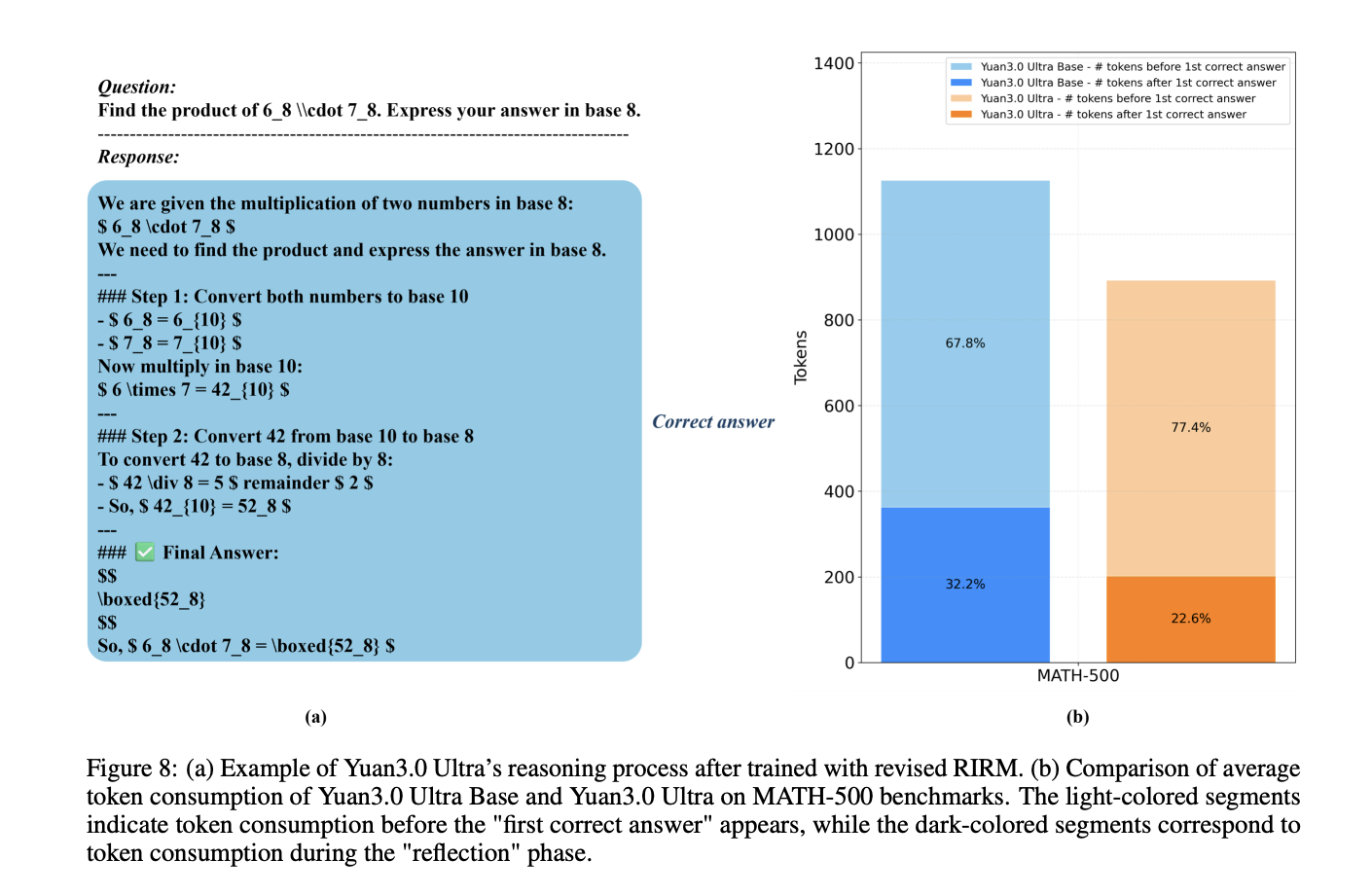
通过修订的RIRM减轻过度思考
在强化学习(RL)阶段,模型采用改进的反射抑制奖励机制(RIRM)来防止对简单任务的过度长期推理。
反射奖励$$ R_{ver} $$的计算使用基于阈值的惩罚系统:
- rmin=0:直接响应的理想反射步骤数。
- rmax=3:可容忍的最大反射阈值。
对于正确样本,随着反射步骤接近rmax,奖励减少,而“过度思考”(超出rmax)的错误样本将受到最大惩罚。这种机制在训练准确性上实现了16.33%的提升,并使输出token长度减少了14.38%。

https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra/blob/main/Docs/Yuan3.0_Ultra_Paper.pdf
企业基准性能
Yuan3.0 Ultra在各种专门的企业基准上,包括GPT-5.2和Gemini 3.1 Pro进行了评估。
| 基准 | 任务类别 | Yuan3.0 Ultra得分 | 领先竞品得分 |
|---|---|---|---|
| Docmatix | 多模态RAG | 67.4% | 48.4%(GPT-5.2) |
| ChatRAG | 文本检索(平均) | 68.2% | 53.6%(Kimi K2.5) |
| MMTab | 表格推理 | 62.3% | 66.2%(Kimi K2.5) |
| SummEval | 文本摘要 | 62.8% | 49.9%(Claude Opus 4.6) |
| Spider 1.0 | 文本到SQL | 83.9% | 82.7%(Kimi K2.5) |
| BFCL V3 | 工具调用 | 67.8% | 78.8%(Gemini 3.1 Pro) |
结果表明,Yuan3.0 Ultra在多模态检索(Docmatix)和长上下文检索(ChatRAG)中实现了最前沿的准确性,同时在结构化数据处理和工具调用方面保持稳健的性能。
查看论文和代码库。也请关注我们的Twitter,并别忘了加入我们的120k+ 机器学习 SubReddit,订阅我们的 newsletter。等等!你在telegram上吗?现在你也可以加入我们了。
文章元实验室AI发布Yuan 3.0 Ultra:旗舰的多模态MoE基础模型,专为更强的智能和无与伦比的效率构建最早出现在MarkTechPost。
相关文章







