StepFun AI发布Step-Audio-R1:首个finally受益于测试时计算缩放的音频LLM
为什么当前音频AI模型在生成较长推理时往往表现不佳,而不是将他们的决策建立在实际声音之上。StepFun研究团队发布了Step-Audio-R1,这是一种新的音频LLM,专为测试时间计算扩展设计,通过显示思维链的准确性下降并不是音频限制,而是一个培训和模态定位问题来解决这个问题?
https://arxiv.org/pdf/2511.15848
核心问题,音频模型通过文本代理进行推理
大多数当前音频模型从文本训练继承了其推理行为。它们学习像是阅读文本记录一样进行推理,而不是像在听一样。StepFun团队称之为文本代理推理。该模型使用想象中的单词和描述,而不是音调轮廓、节奏、音色或背景噪声模式等声学线索。
这种不匹配解释了为什么较长的思维链常常会损害音频的表现。模型在阐述错误或与模态无关的假设时花费了更多的标记。Step-Audio-R1通过强迫模型使用声学证据来证明答案来攻击这个问题。训练管道围绕模态定位推理蒸馏(MGRD)组织起来,该蒸馏选择和提炼明确引用音频特征的推理线索。
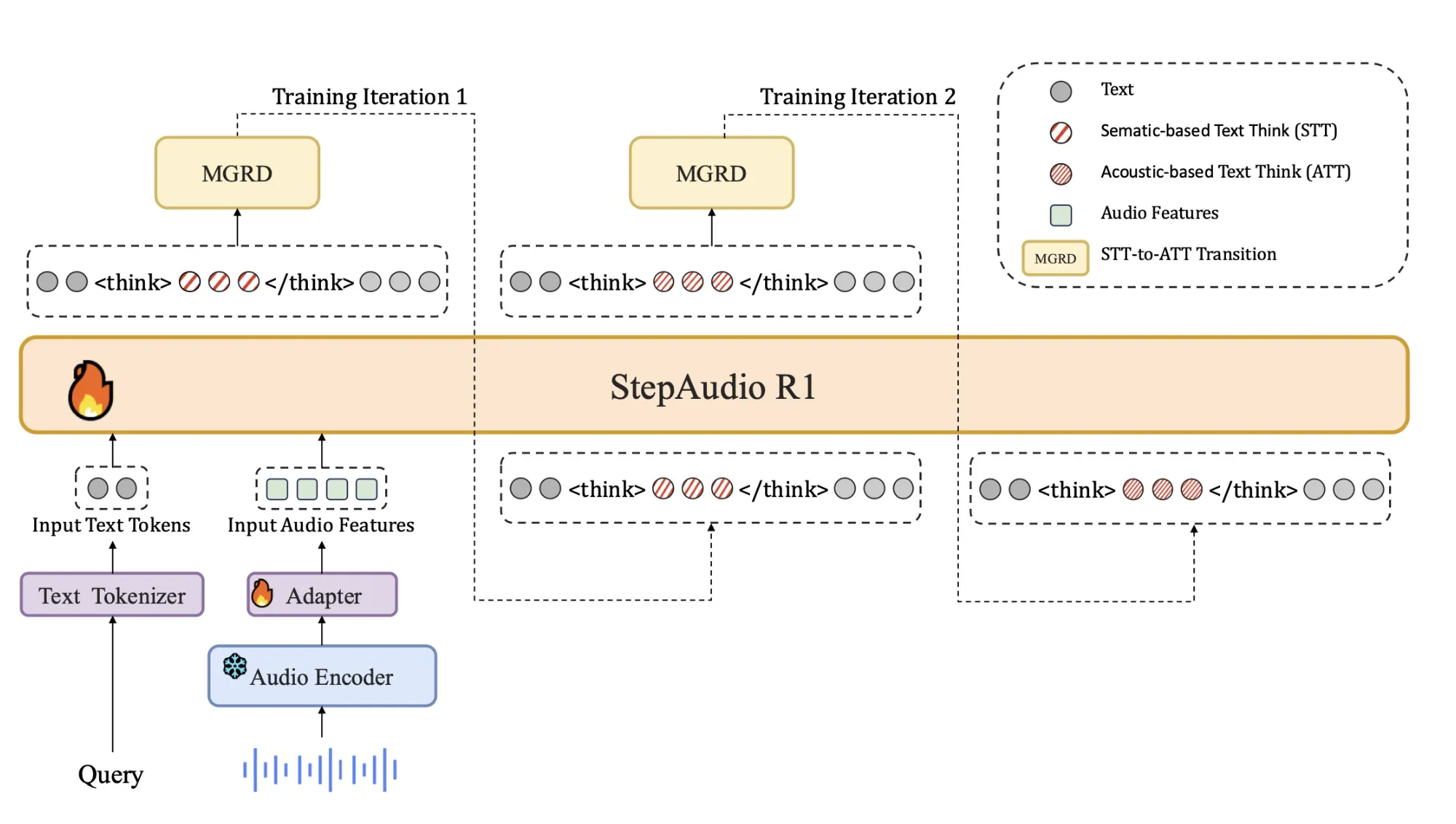
架构
该架构与之前的Step Audio系统保持紧密:
- 一个基于Qwen2的音频编码器以25 Hz处理原始波形。
- 一个音频适配器将编码器输出降低到原来的2倍,到达12.5 Hz,并与语言标记流对齐。
- qwen2.5 32B解码器消费音频特征并生成文本。
解码器始终在<think>和</think>标签内产生一个显式的推理块,然后是最终答案。这种分离让训练目标能塑造推理的结构和内容,同时也不会失去对任务准确性的关注。该模型作为一个33B参数的音频到文本模型在Hugging Face Apache 2.0上发布。
https://arxiv.org/pdf/2511.15848
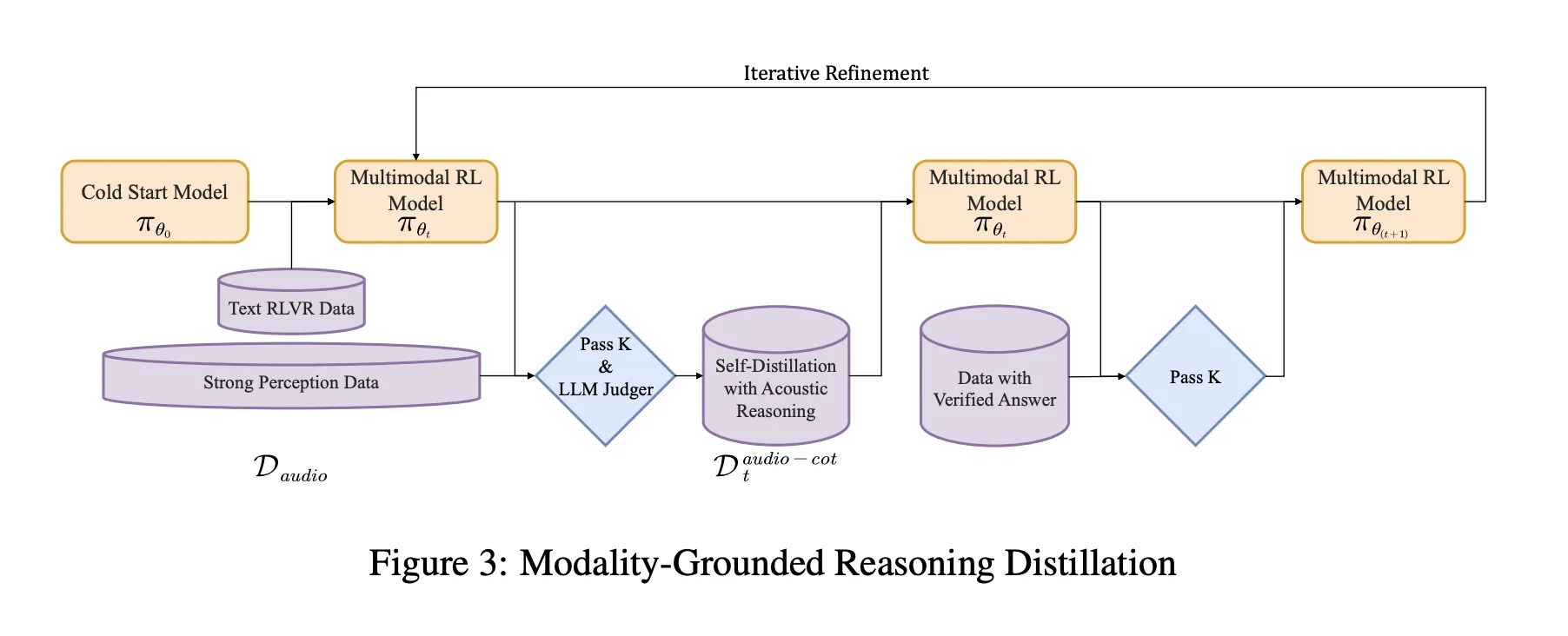
训练管道,从冷启动到音频定位的强化学习
该管道包含一个监督冷启动阶段和一个混合文本和音频任务的强化学习阶段。
冷启动使用大约500万个示例,仅覆盖10亿个标记的文本数据以及40亿个来自音频配对数据。音频任务包括语音识别、副语言理解以及音频问答式对话。音频数据中的部分包含由先前模型生成的音频思维链轨迹。文本数据包括多轮对话、知识问答、数学和代码推理。所有示例都遵循一个推理被<think>标签包裹的格式,即使推理块最初是空的。
监督学习训练Step-Audio-R1遵循此格式,并为音频和文本生成有用的推理。这给出了一种基准思维链行为,但仍然偏向于基于文本的推理。
模态定位推理蒸馏 MGRD
MGRD在几个迭代中应用。在每轮中,研究团队都对依赖于真实声学属性(如说话者情绪、声音场景中的背景事件或音乐结构)的音频问题进行采样。当前的模型对每个问题生成多个推理和答案候选项。一个过滤器只保留满足以下三个约束的链条:
- 它引用声学线索,而不仅仅是文本描述或想象中的录音。
- 它作为短步骤解释,具有逻辑一致性。
- 它们的最终答案根据标签或程序性检查是正确的。
这些接受的反冲构成了一个提炼的音频思维链数据集。该模型在这个数据集上以及原始文本推理数据一起微调。然后进行带验证奖励的强化学习(RLVR)。对于文本问题,奖励基于答案正确性。对于音频问题,奖励混合了答案正确性和推理格式,准确性的典型权重为0.8,推理为0.2。训练使用PPO,每项提示采样约16个响应,并支持约10240个标记的序列,以允许长思考。
https://arxiv.org/pdf/2511.15848
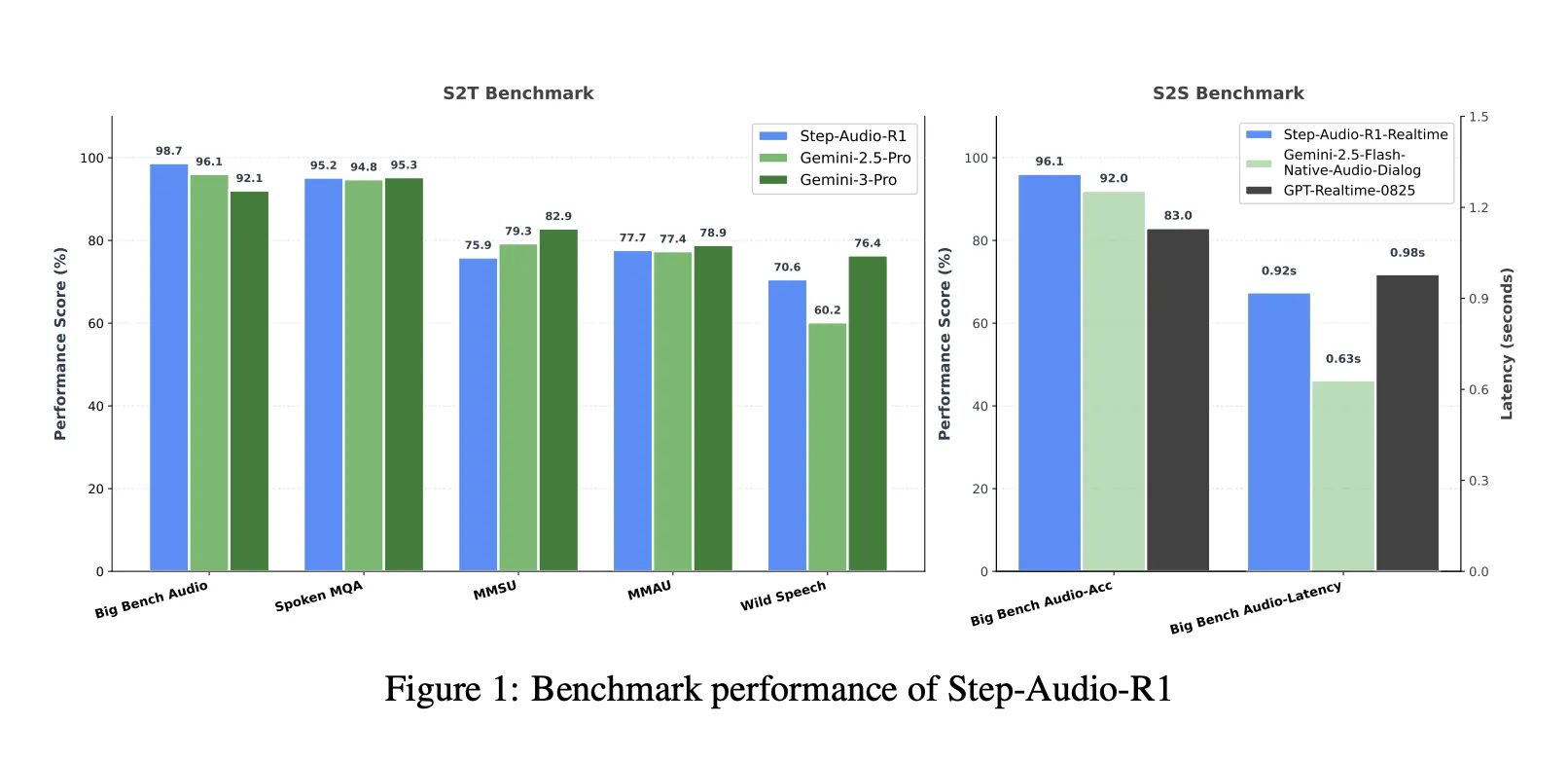
基准测试,缩小与Gemini 3 Pro的差距
在包含Big Bench Audio、Spoken MQA、MMSU、MMAU和Wild Speech的语音到文本基准测试套件中,Step-Audio-R1的平均得分约为83.6%。Gemini 2.5 Pro报告的得分约为81.5%,而Gemini 3 Pro达到的分数约为85.1%。仅Big Bench Audio上,Step-Audio-R1达到的分数约为98.7%,高于Gemini版本。
对于语音到语音推理,Step-Audio-R1实时变体采用边听边思考和边说话的风格流。在Big Bench Audio语音到语音上,它达到约96.1%的推理准确性,第一包延迟约为0.92秒。这个分数超过了基于GPT的实时基线,同时保持了亚秒级交互。
https://arxiv.org/pdf/2511.15848
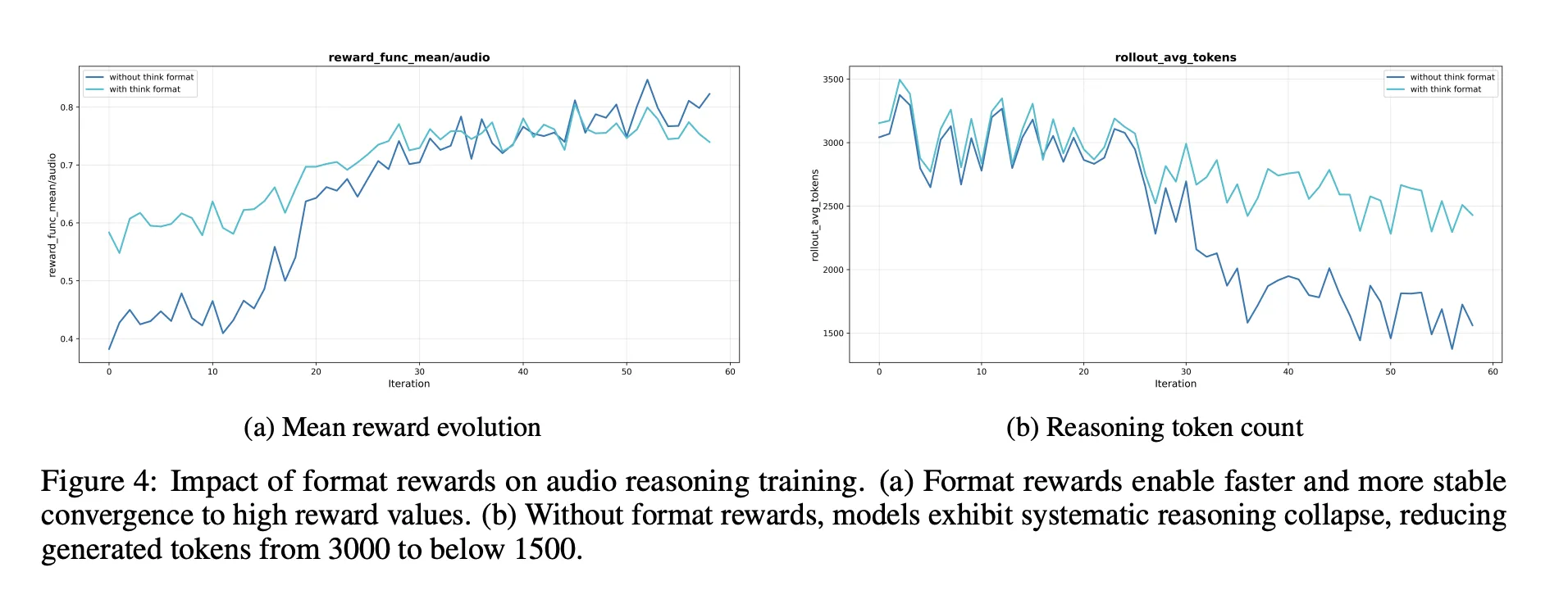
消融实验,音频推理的关键
消融部分为工程师提供了几个设计信号:
- 需要推理格式奖励。没有它,强化学习往往会缩短或删除思维链,这降低了音频基准测试分数。
- RL数据应针对中等难度的问题。选择通过率为80%的问题位于中间带给出更稳定的奖励并保持长推理。
- 不进行此类选择而无望地进行音频数据的扩展RL无助于改进。提示和标签的质量比原始大小更重要。
研究人员还描述了一个自我认知校正管道,减少了例如“我只可以阅读文本而不能听到音频”这样答案的频率,这是一个训练处理声音的模型。这是在经过筛选的偏好对上使用直接偏好优化实现的,其中正确的做法是承认并使用音频输入。
关键要点
- Step-Audio-R1是将更长的思维链转化为音频任务的持续准确率提升的音频语言模型之一,它解决了先前音频LLM中看到的反向缩放失败。
- 该模型通过模态定位推理蒸馏明确针对文本代理推理,只筛选和提炼那些依靠声学线索(如音调、音色和节奏)而不是想象中的记录的推理线索。
- 从架构上讲,Step-Audio-R1结合了一个基于Qwen2的音频编码器、适配器和总是生成
<think>推理段之前的Qwen2.5 32B解码器,并作为一个33B音频到文本模型在Apache 2.0下发布。 - 在涵盖语音、环境声音和音乐的综合性音频理解和推理基准测试中,Step-Audio-R1超越了Gemini 2.5 Pro,并达到了与Gemini 3 Pro相当的性能,同时还有一个实时变体,为低延迟语音到语音交互提供支持。
- 训练配方结合了大规模监督思维链、模态定位蒸馏和带验证奖励的强化学习,为构建未来从测试时间计算扩展实际受益的音频推理模型提供了一个具体且可重现的蓝图。

编辑注
Step-Audio-R1是一个重要发布,因为它通过模态定位推理蒸馏和带验证奖励的强化学习直接解决文本代理推理,将思维链从一项负债转化为音频推理的有用工具。它表明,当推理基于声学特征时,测试时间计算扩展可以受益于音频模型,同时提供了与Gemini 3 Pro相当的基准测试结果,并且对外部和实用性对工程师来说都是开放的和实用的。总的来说,这项研究工作将音频LLM中的扩展深思熟虑从一种一致失败模式转变为一种可控且可重现的设计模式。
查看论文、存储库、项目页面和模型权重。请自由查看我们的GitHub页面,有关教程、代码和笔记。也请自由关注我们的Twitter,并不要忘记加入我们的10万+机器学习SubReddit 并订阅我们的新闻通讯。等等!你在telegram上吗?[现在你也可以加入我们的telegram频道。(https://t.me/machinelearningresearchnews)}
StepFun AI发布Step-Audio-R1:一个终于从测试时间计算扩展中受益的新音频LLM最先出现在MarkTechPost。
相关文章







