NVIDIA AI推出了Orchestrator-8B:一款用于高效工具和模型选择的强化学习训练控制器。
NVIDIA研究人员发布了一个名为 ToolOrchestra 的新方法,用于训练小型语言模型作为指挥官——异构工具使用代理的“大脑”。
https://arxiv.org/pdf/2511.21689
从单一模型代理到协调策略
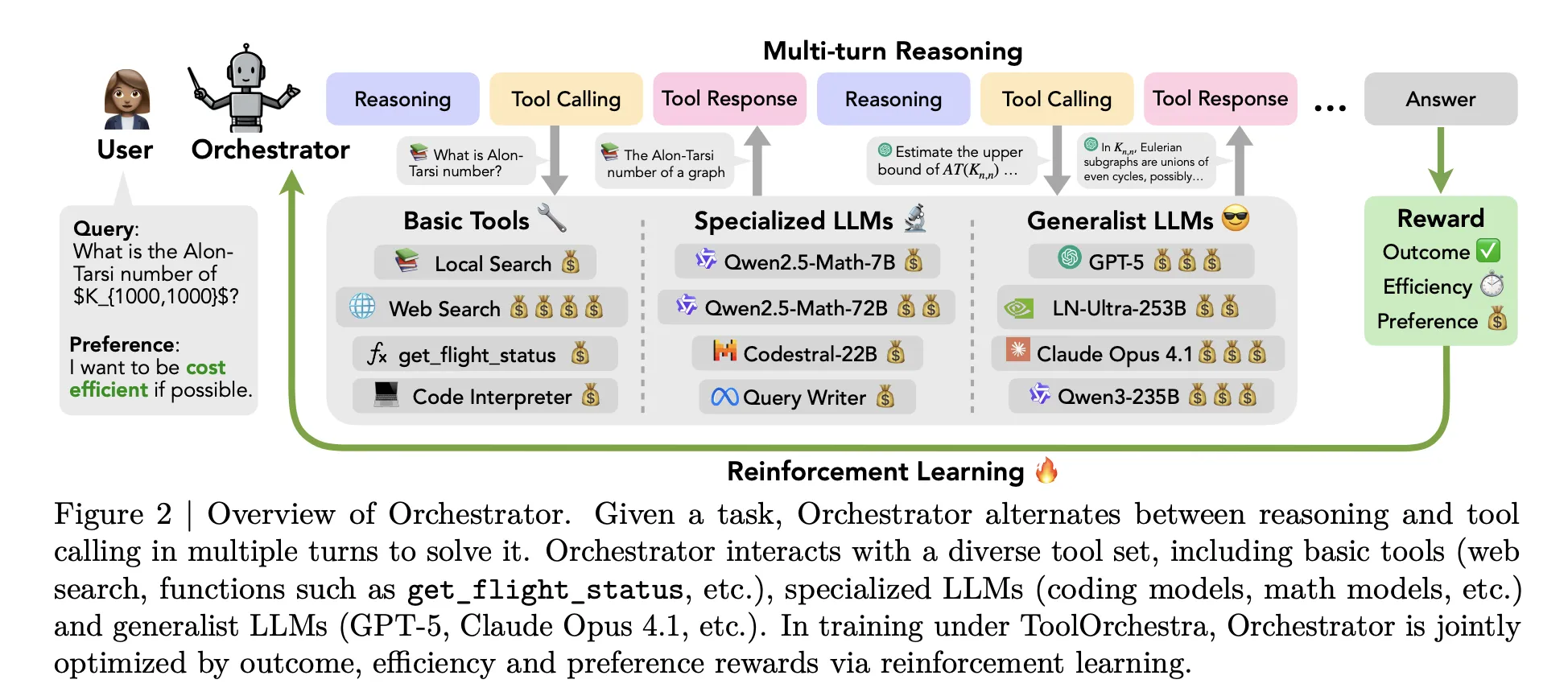
大多数当前的代理遵循一个简单的模式。一个如GPT-5这样的大型模型接收描述可用工具的提示,然后决定何时调用网络搜索或代码解释器。所有高级推理仍然保留在同一个模型中。ToolOrchestra改变了这种设置。它训练一个专门的控制器模型,被称为“Orchestrator-8B”,它将经典工具和其他LLMs视为可调用的组件。
同一研究的试点研究表明,自然的提示远远不够。当Qwen3-8B被提示在GPT-5、GPT-5 mini、Qwen3-32B和Qwen2.5-Coder-32B之间选择路线时,它会将73%的情况委托给GPT-5。当GPT-5充当其自己的指挥官时,它在98%的情况下调用GPT-5或GPT-5 mini。研究团队将这些称为自我增强和其他增强偏见。路由策略过度使用强大模型,并忽略了成本指令。
相反,ToolOrchestra为这个路由问题明确训练了一个小型指挥官,使用强化学习在每个多轮轨迹上训练。
Orchestrator 8B是什么?
Orchestrator-8B是一个8B参数的解码器,仅使用Transformer构建。它是通过微调Qwen3-8B作为协调模型然后在Hugging Face上发布的。
在推理时,系统运行一个多轮循环,交替推理和工具调用。滚动有三个主要步骤。第一步,Orchestrator 8B读取用户指令和可选的口头语言偏好描述,例如请求优先考虑低延迟或避免网络搜索。第二步,它生成一系列内部思维链式推理并计划一项行动。第三步,它从可用工具集中选择一个工具,并以统一的JSON格式发出结构化工具调用。环境执行该调用,将结果作为观察并将其反馈到下一步。当产生终止信号或达到50轮最大值时,过程停止。
工具分为三个主要类别。基本工具包括Tavily网络搜索、Python沙盒代码解释器和使用Qwen3-Embedding-8B构建的本地Faiss索引。专用LLMs包括Qwen2.5-Math-72B、Qwen2.5-Math-7B和Qwen2.5-Coder-32B。通用LLMs工具包括GPT-5、GPT-5 mini、Llama 3.3-70B-Instruct和Qwen3-32B。所有工具都共享相同的模式,包括名称、自然语言描述和类型化参数规范。
多目标奖励的端到端强化学习
ToolOrchestra将整个工作流程形式化为马尔可夫决策过程。状态包含对话历史、过去的工具调用和观察以及用户偏好。动作是下一个文本步骤,包括推理令牌和工具调用模式。最多50步后,环境计算整个轨迹的标量奖励。
奖励有三个组成部分。结果奖励是二元性的,取决于轨迹是否解决问题。对于开放式答案,GPT-5被用作评判者,将模型输出与参考进行比较。效率奖励惩罚货币成本和时间成本。私有和开源工具的令牌使用情况使用公开API和Together AI定价映射到货币成本。偏好奖励衡量工具使用与用户偏好向量匹配的程度,该向量可以增加或减少成本、延迟或特定工具的权重。这些组件通过偏好向量组合成一个单一的标量。
该策略通过与轨迹组相对策略优化 GRPO进行优化,这是一种策略梯度强化学习的变体,它正常化相同任务的轨迹组中的奖励。训练过程包括过滤器,丢弃有无效工具调用格式或较弱奖励变差的轨迹以稳定优化。
为了使这种在大规模上进行训练成为可能,研究团队计划引入ToolScale,这是一个多步骤工具调用任务的合成数据集。对于每个领域,LLM生成数据库模式、数据库条目、领域特定API,然后生成各种用户任务,这些任务与函数调用和所需中间信息的真实序列。
基准测试结果和成本概况
NVIDIA研究团队在三个具有挑战性的基准测试中评估Orchestrator-8B,即人类最后一次考试、FRAMES和τ² Bench。这些基准测试针对长期推理、检索中的事实性和双重控制环境中的函数调用。
在人类最后一次考试的纯文本问题上,Orchestrator-8B达到37.1%的准确率。在相同设置中,使用基本工具的GPT-5达到35.1%。在FRAMES上,Orchestrator-8B实现76.3%,而使用工具的GPT-5为74.0%。在τ² Bench上,Orchestrator-8B得分80.2%,而使用基本工具的GPT-5为77.7%。
在配置中使用基本工具加上专用和通用LLM工具时,在人类最后一次考试和FRAMES上,Orchestrator-8B的平均成本为9.2美分,平均延迟为8.2分钟。在相同的配置中,GPT-5平均成本为30.2美分,平均延迟为19.8分钟。模型卡将此总结为比GPT-5成本低约30%,速度快2.5倍。
工具使用分析支持这一图景。作为指挥官使用的Claude Opus 4.1大部分时间调用GPT-5。用作指挥官的GPT-5更喜欢GPT-5 mini。Orchestrator-8B更均匀地将调用分配给强大模型、低成本模型、搜索、本地检索和代码解释器,并在较低的成本下达到更高的准确率。
一般化实验将训练时间工具更换为未看到的模型,例如OpenMath Llama-2-70B、DeepSeek-Math-7B-Instruct、Codestral-22B-v0.1、Claude Sonnet-4.1和Gemma-3-27B。在此设置中,Orchestrator-8B在准确率、成本和延迟之间仍然比所有基线实现出最佳的权衡。一个单独的偏好意识测试集还表明,在相同的奖励指标下,Orchestrator-8B也比GPT-5、Claude Opus-4.1和Qwen3-235B-A22B更接近跟踪用户工具使用偏好。
关键要点
- ToolOrchestra训练了一个8B参数的协调模型Orchestrator-8B,该模型通过具有结果、效率和偏好意识奖励的强化学习选择和排列工具和LLMs,以解决多步骤代理任务。
- Orchestrator-8B作为打开权重的模型发布在Hugging Face。它旨在通过统一模式协调各种工具,例如网络搜索、代码执行、检索和专门LLMs。
- 在人类最后一次考试中,Orchestrator-8B达到37.1%的准确率,超过了35.1%的GPT-5,同时效率提高约2.5倍,在τ² Bench和FRAMES上优于GPT-5,成本大约是GPT-5基线的30%。
- 该框架表明,以前沿LLM作为其自己的路由器进行自然提示会导致自我强化偏见,其中它过度使用自己或一小组强大模型,而训练过的指挥官通过跨多个工具学习到一个更平衡、成本意识的路由策略。
编辑说明
NVIDIA的ToolOrchestra是向复合AI系统迈进的一个实际步骤,在该系统中,一个8B协调模型Orchestrator-8B学习显式路由策略,管理工具和LLMs,而不是依赖单个前沿模型。它在人类最后一次考试、FRAMES和τ² Bench上的收益明显,成本大约是GPT-5基线的30%,效率提高约2.5倍,对于关注准确度、延迟和预算的团队来说具有重要意义。这次推出将协调政策作为AI系统中的顶级优化目标。
查看论文、代码库、项目页面和Hugging Face上的模型权重。您可以免费查看我们的教程、代码和笔记本的GitHub页面。此外,请自由地关注我们的Twitter和别忘了加入我们的10k+ ML SubReddit并订阅我们的时事通讯。等等!你在Telegram上吗?现在你可以在Telegram上加入我们了。
原文链接:NVIDIA AI发布Orchestrator-8B:一种强化学习训练的控制器,用于高效的工具和模型选择 - MarkTechPost
相关文章







