微软AI发布Fara-7B:适用于计算机使用的效率提升型智能体模型
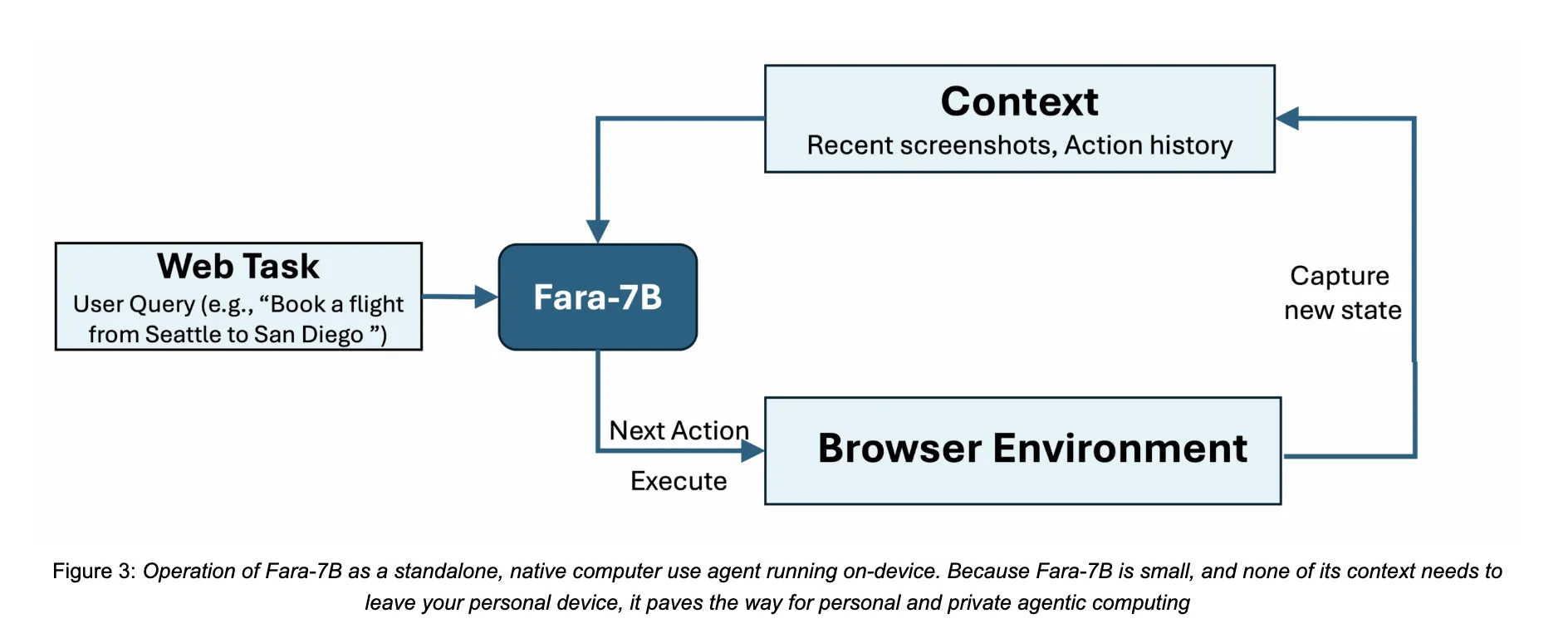
微软研究部门发布了一个名为 Fara-7B 的7亿参数的智能体语言模型,专为计算机使用而设计。这是一个开源的计算机使用智能体,可以从屏幕截图中运行,预测鼠标和键盘操作,并且体积小巧,能够在单个用户设备上执行,从而降低延迟并保持浏览数据的本地化。
https://www.microsoft.com/en-us/research/blog/fara-7b-an-efficient-agentic-model-for-computer-use/
从聊天机器人到计算机使用智能体
传统的以聊天为导向的LLM返回文本。像Fara-7B这样的计算机使用智能体则控制浏览器或桌面用户界面来完成任务,如填写表格、预订旅行或比较价格。他们感知屏幕,对页面布局进行推理,然后发出像点击、滚动、输入、网页搜索或访问网址这样的低级动作。
许多现有的系统依赖于复杂的封装在复杂框架中的大型多模态模型,该框架解析可访问性树并协调多个工具。这增加了延迟,通常需要服务器端部署。Fara-7B将此类多智能体系统的行为压缩到基于Qwen2.5-VL-7B的单个多模态解码器单一模型中。它消耗浏览器截图和文本上下文,然后直接输出跟随有基于诸如坐标、文本或网址之类的 grounded论证的工具调用的思维文本。
FaraGen,用于网络交互的合成轨迹
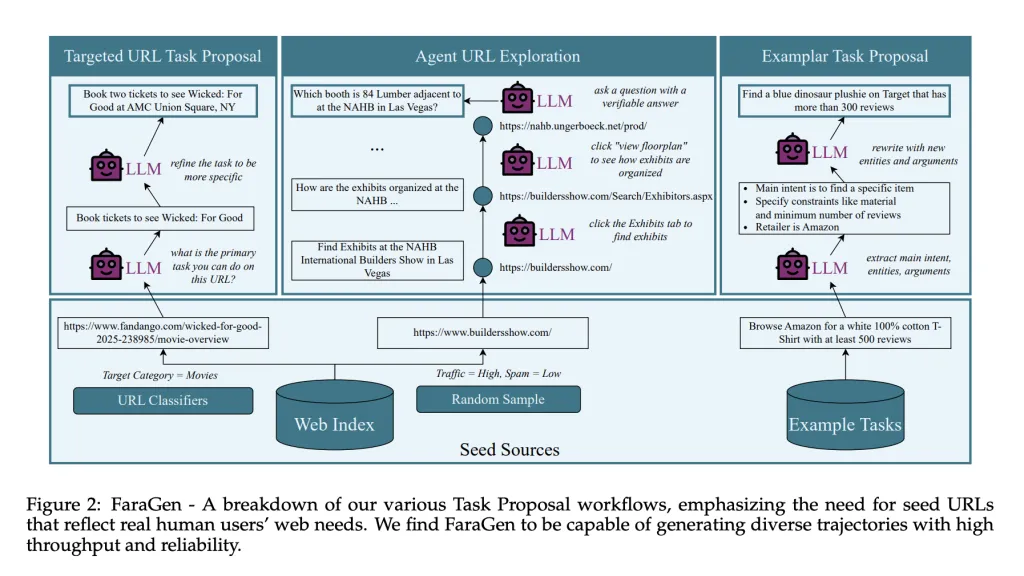
计算机使用智能体的关键瓶颈是数据。人类与网络进行多步操作的丰富日志很少见且昂贵。Fara项目引入了FaraGen,这是一个合成数据引擎,它为实时网站生成和过滤网络轨迹。
FaraGen使用一个三阶段的管道。任务提议从公共语料库如ClueWeb22和Tranco中抽取种子URL开始,这些URL被分类到电子商务、旅行、娱乐或论坛等域中。大型语言模型将每个URL转换为用户可能在该页面上尝试的现实任务,例如预订特定电影票或根据评论和材料创建购物清单。任务必须在无需登录或支付墙的情况下可实现,完全指定,有用且可自动验证。
https://www.microsoft.com/en-us/research/blog/fara-7b-an-efficient-agentic-model-for-computer-use/
任务解决基于Magentic-One和Magentic-UI的多智能体系统。协调器智能体规划高级策略并维护任务状态账本。WebSurfer智能体接收可访问性树和Set-of-Marks截图,通过Playwright发出浏览器操作,如点击、输入、滚动、访问网址或网页搜索。当任务需要澄清时,用户模拟器智能体提供后续指令。
轨迹验证使用三个基于LLM的验证器。对齐验证器检查操作和最终答案是否与任务意图匹配。评分验证器生成子目标评分表并评分部分完成情况。多模态验证器检查截图和最终答案以捕捉幻觉并确认可见证据支持成功。这些验证器在83.3 percent的情况下与人类标签一致,报告的误报和漏报率约为17到18 percent。
过滤后,FaraGen产生了145,603个轨迹,包含1,010,797个步骤,覆盖了70,117个独特的域。轨迹的步骤数从3到84步不等,平均为6.9步,每个轨迹大约有0.5个独特的域,这表明许多任务涉及数据集中尚未见过的网站。使用GPT-5和o3等定制的模型生成数据大约每验证一个轨迹成本1美元。

模型架构
Fara-7B是一个仅使用Qwen2.5-VL-7B作为基础的多模态解码器模型。它接收用户目标、浏览器最新截图以及先前思考与动作的完整历史。上下文窗口为128,000个令牌。在每个步骤中,模型首先生成一条思想链,描述当前状态和计划,然后输出一个工具调用,指定下一个动作及其参数。
工具空间与Magentic-UI计算机使用界面相匹配。它包括按键、输入、鼠标移动、左键点击、滚动、访问网址、网页搜索、历史后退、暂停和记忆事实、等待以及终止。坐标被直接预测为截图上的像素位置,这允许模型在推理时无需访问可访问性树。
训练使用监督微调,在约180万个混合多个数据源的超样本上进行。这包括FaraGen轨迹拆分为观察、思考和行动步骤,grounding和UI定位任务,基于截图的视觉问答和字幕,以及安全和拒绝数据集。
基准和效率
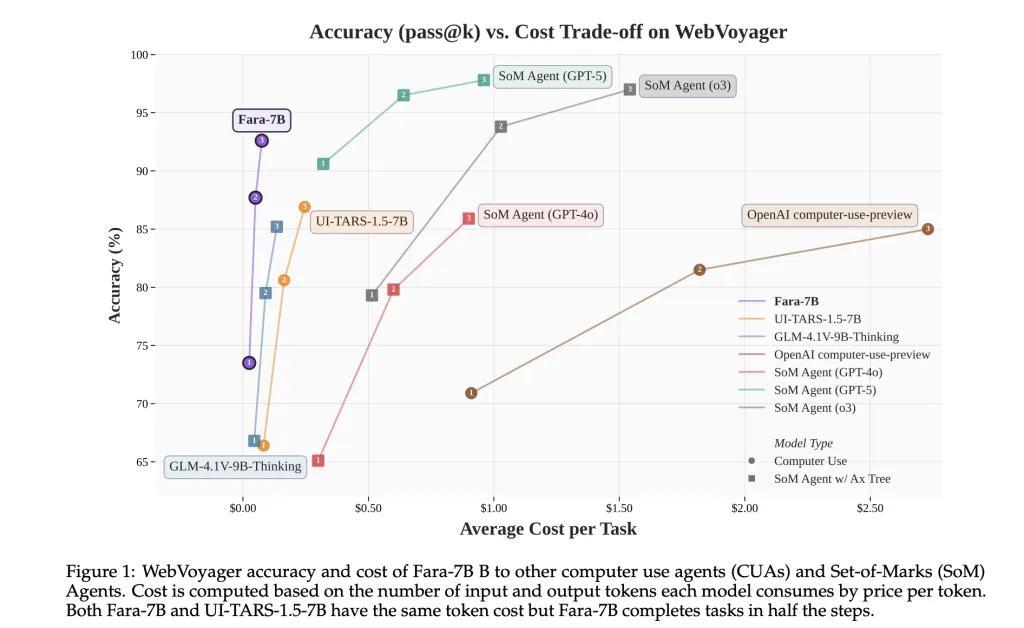
微软对Fara-7B进行了四项实时网络基准的评估:WebVoyager、Online-Mind2Web、DeepShop以及新的WebTailBench,该基准重点关注餐厅预订、求职申请、房地产搜索、比较购物和多站点组合任务等代表性不足的领域。
在这些基准测试中,Fara-7B在WebVoyager上的成功率达到了73.5%,在Online-Mind2Web上为34.1%,在DeepShop上为26.2%,在WebTailBench上为38.4%。这超过了7B计算机使用智能体基线UI-TARS-1.5-7B,后者分别得分为66.4、31.3、11.6和19.5,与基于GPT-4o等大模型的OpenAI计算机使用预览和SoM智能体配置相比也表现优异。
在WebVoyager上,Fara-7B每个任务使用平均124,000个输入令牌和1,100个输出令牌,大约16.5个动作。根据市场价格,研究团队估计每个任务的平均成本为0.025美元,而支持如GPT-5和o3等专有推理模型的SoM智能体的大约成本为0.30美元。Fara-7B使用的输入令牌数量相似,但其输出令牌数量约为SoM智能体十分之一。
主要观点
- Fara-7B是基于Qwen2.5-VL-7B构建的7B参数的开源计算机使用智能体,可以直接从截图和文本中运行,然后输出基于点击、输入和导航等grounded的动作,而不依赖于推理时的可访问性树。
- 该模型使用由FaraGen管道生成的145,603个经过验证的浏览器轨迹和1,010,797个步骤进行训练,该管道使用基于多智能体任务提议、解决和基于LLM的现场网站验证。
- Fara-7B在WebVoyager上实现了73.5%的成功率,在Online-Mind2Web上为34.1%,在DeepShop上为26.2%,在WebTailBench上为38.4%,在所有四个基准上均显著优于7B UI-TARS-1.5基线。
- 在WebVoyager上,Fara-7B每个任务使用约124,000个输入令牌和1,100个输出令牌,平均约16.5个动作,预计每个任务的成本约为0.025美元,这在输出令牌使用上比基于GPT 5级模型的SoM智能体便宜约一个数量级。
编辑注记
Fara-7B是朝着实用的计算机使用智能体迈出的有用一步,这些智能体可以在本地硬件上运行,降低推理成本同时保护隐私。Qwen2.5 VL 7B、FaraGen合成轨迹和WebTailBench的结合提供了一个清晰并有良好仪表的路径,从多智能体数据生成到单一代码紧凑的模型,该模型在关键基准上与更大型系统相匹配或超过,同时执行临界点和拒绝安全措施。
查看论文、模型权重以及技术细节。欢迎查看我们的教程、代码和笔记本的GitHub页面。也欢迎关注我们的Twitter,并加入我们的100k+机器学习SubReddit以及订阅我们的时事通讯。等一下!你在telegram上吗?现在你可以在telegram上加入我们了。
原文首次发表在MarkTechPost上。
相关文章







