NVIDIA AI发布Nemotron-Elastic-12B:一个无需额外训练成本的单一AI模型,可提供6B/9B/12B变体。
为什么AI开发团队仍在为不同的部署需求训练和存储多个大型语言模型,而一个可伸缩的模型可以以相同的成本生成多个尺寸?NVIDIA正在将通常的“模型家族”堆叠合并为一个单独的训练任务。NVIDIA AI团队发布Nemotron-Elastic-12B,一个12B参数的推理模型,该模型在同一参数空间中内嵌了9B和6B的变体,因此这三种尺寸都来自一个可伸缩的检查点,无需对每个尺寸进行额外的蒸馏运行。
一个模型家族中的多个模型
大多数生产系统需要多个模型尺寸,一个较大的模型用于服务器端工作负载,一个中等尺寸的模型用于强大的边缘GPU,一个较小的模型用于严格的延迟或电源预算。通常的管道对每个尺寸分别进行训练或蒸馏,因此标记成本和检查点存储与变体的数量成比例。
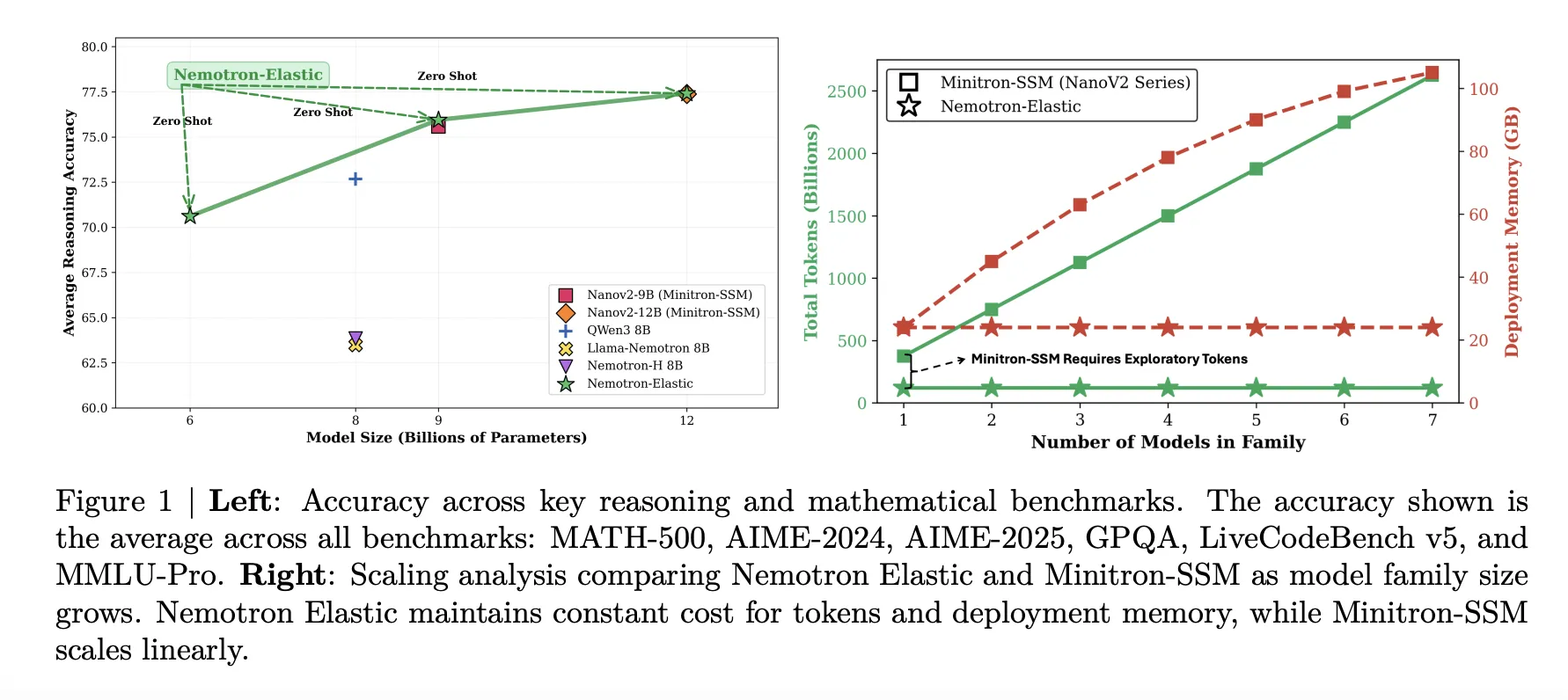
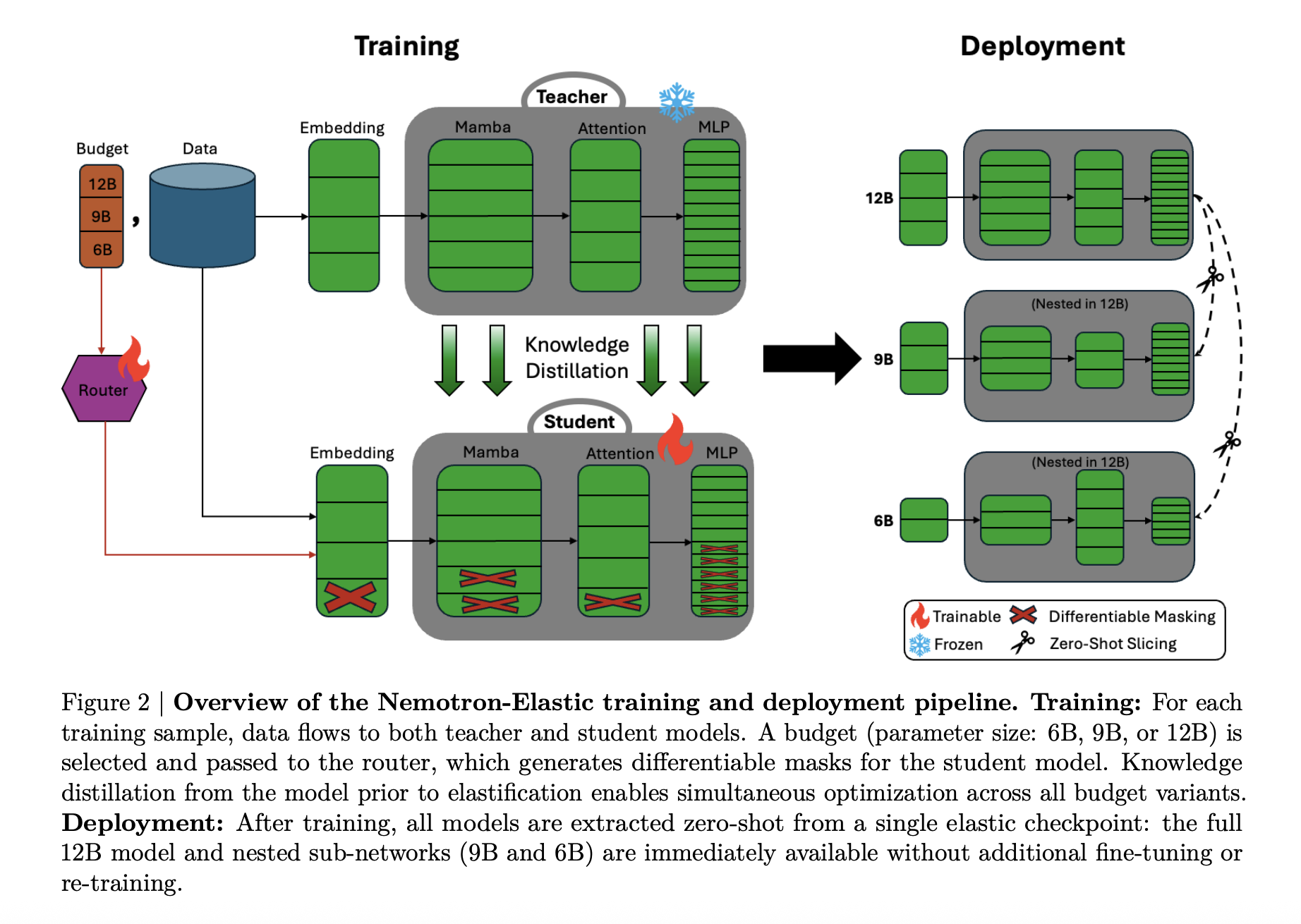
Nemotron Elastic采取不同的路径。它从Nemotron Nano V2 12B推理模型开始,并训练了一个可伸缩的混合Mamba Attention网络,该网络公开了多个嵌套的子模型。发布的Nemotron-Elastic-12B检查点可以使用提供的切片脚本切割成9B和6B变体,Nemotron-Elastic-9B和Nemotron-Elastic-6B,而无需任何额外的优化。
所有变体共享权重和路由元数据,因此训练成本和部署内存都与最大模型相关,而不是与家族中的尺寸数量相关。
https://arxiv.org/pdf/2511.16664v1
混合Mamba Transformer带可伸缩掩码
在架构上,Nemotron Elastic是一个Mamba-2 Transformer混合体。基础网络遵循Nemotron-H风格设计,其中大部分层都是基于Mamba-2的序列状态空间块加MLP,一小部分注意力层保留了全局感受野。
可伸缩性通过将这种混合体变成由掩码控制的动态模型来实现:
- 宽度、嵌入通道、Mamba头、头通道、注意力头和FFN中间尺寸可以通过二进制掩码减少。
- 深度、层可以根据学习到的排序顺序进行裁剪,残差路径保持信号流。
路由模块为每个预算输出离散配置选择。将这些选择转换为Gumbel Softmax掩码,然后应用于嵌入、Mamba投影、注意力投影和FFN矩阵。研究团队添加了一些细节以保持SSM结构的有效性:
- 分组感知的SSM弹性化,尊重Mamba头和通道分组。
- 异构MLP弹性化,其中不同层可以有不同的大小。
- 基于归一化MSE的层重要性来决定哪些层在深度减少时留留下来。
较小的变体始终是排名组件列表中的前缀选择,这使得6B和9B模型成为12B父模型的真正嵌套子网络。
https://arxiv.org/pdf/2511.16664v1
推理工作负载的两阶段训练
Nemotron Elastic作为具有冻结教师推理模型进行训练。教师是原始的Nemotron-Nano-V2-12B推理模型。弹性12B学生针对所有三个预算,6B、9B、12B进行联合优化,使用知识蒸馏加上语言建模损失。
训练分两个阶段进行:
- 第一阶段:短上下文,序列长度8192,批量大小1536,约65B个标记,在三个预算上均匀采样。
- 第二阶段:扩展上下文,序列长度49152,批量大小512,约45B个标记,采用非均匀采样,优先考虑完整的12B预算。
https://arxiv.org/pdf/2511.16664v1
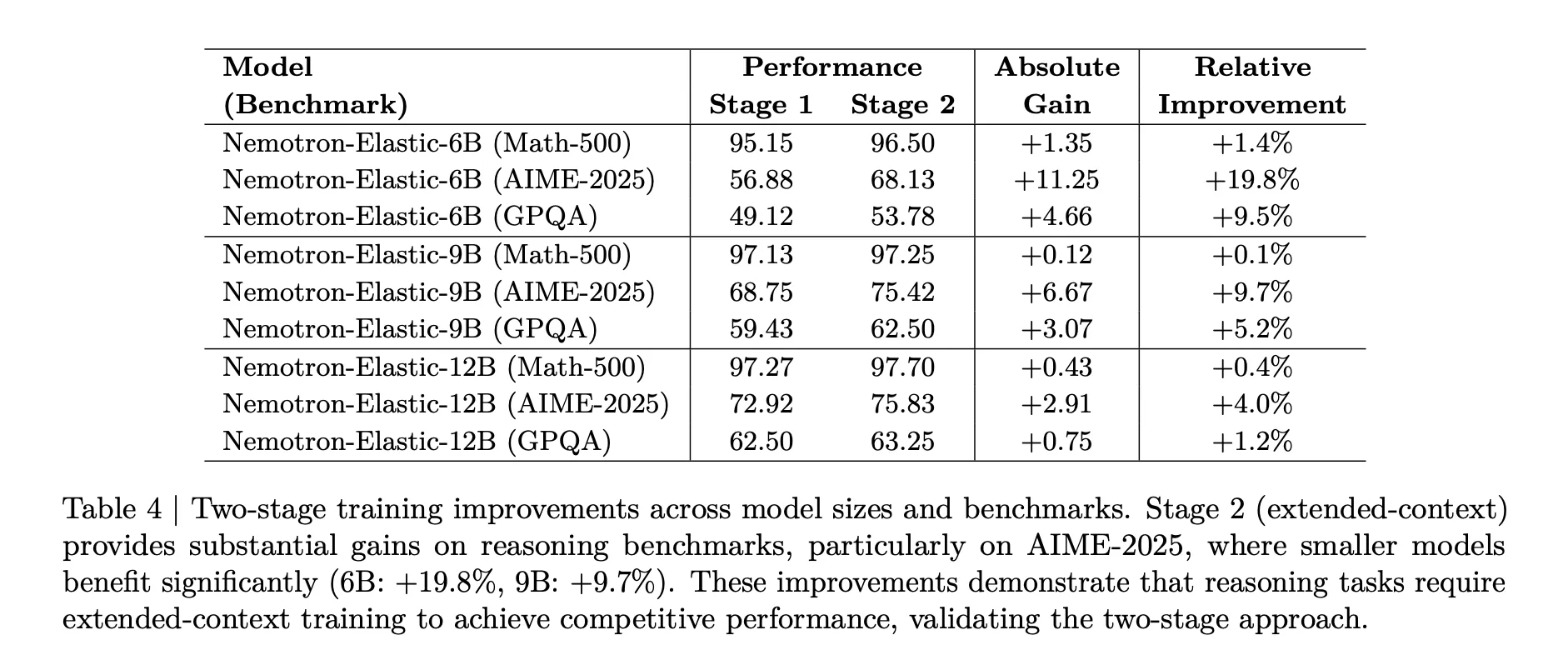
第二阶段对于推理任务来说很重要。上面的表格显示,对于AIME 2025,6B模型在扩展上下文训练后从56.88提高到68.13,相对增益为19.8%,而9B模型增益9.7%,12B模型在扩展上下文训练后增益4.0%。
预算采样也进行了调整。在第二阶段,12B、9B、6B的非均匀权重为0.5、0.3、0.2,避免了最大模型的退化,并保持了所有变体在与Math 500、AIME 2025和GPQA的竞争中具有竞争力。
基准测试结果
Nemotron Elastic在推理密集型基准测试上进行了评估,包括MATH 500、AIME 2024、AIME 2025、GPQA、LiveCodeBench v5和MMLU Pro。以下表格总结了在1准确率下的通过率。

https://arxiv.org/pdf/2511.16664v1
12B可伸缩模型在平均意义上与NanoV2-12B基线相当,为77.41比77.38,同时还提供了来自同一运行中的9B和6B变体。9B可伸缩模型与NanoV2-9B基线紧密跟踪,为75.95比75.99。6B可伸缩模型达到70.61,略低于Qwen3-8B在72.68,但考虑到其参数数量,仍然很强大,因为它并没有单独进行训练。
训练标记和内存节省
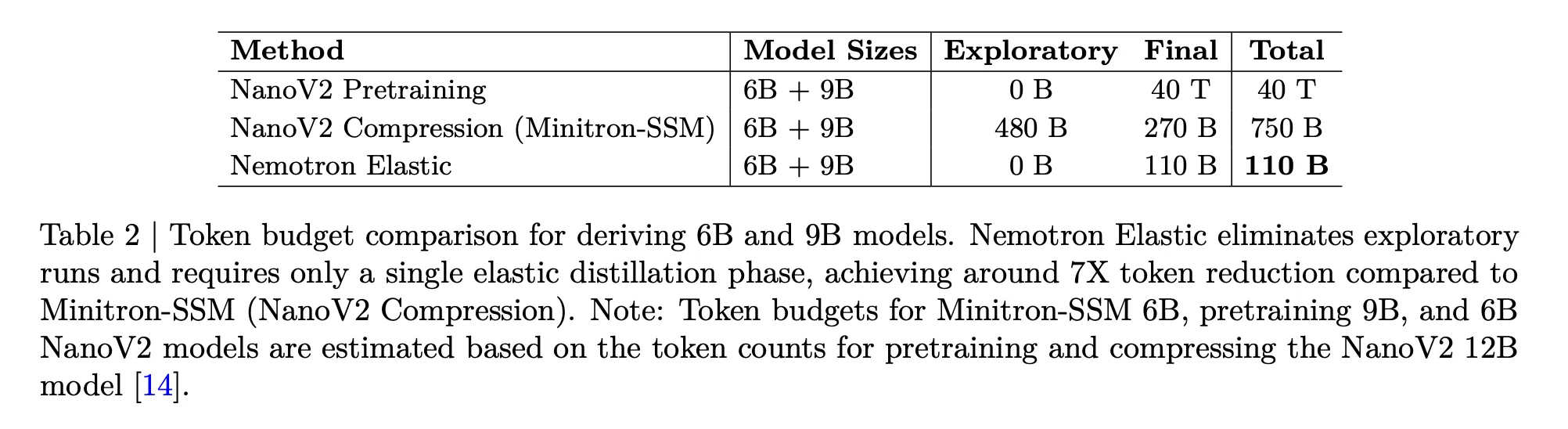
Nemotron Elastic直接针对成本问题。以下表格比较了从12B父模型派生6B和9B模型所需的标记预算:
- NanoV2预训练6B和9B,总共40T个标记。
- NanoV2压缩加Minitron SSM,480B探查加270B最终,750B个标记。
- Nemotron Elastic,单次弹性蒸馏运行中110B个标记。
https://arxiv.org/pdf/2511.16664v1
该研究团队报告称,这比从头开始训练两个额外模型减少了大约360倍,与压缩基线相比减少了大约7倍。
部署内存也得到了减少。以下表格声明,存储Nemotron Elastic 6B、9B和12B总共需要24GB的BF16权重,而存储NanoV2 9B加12B则需要42GB。这减少了43%的内存,同时还可以额外提供一个6B选项。
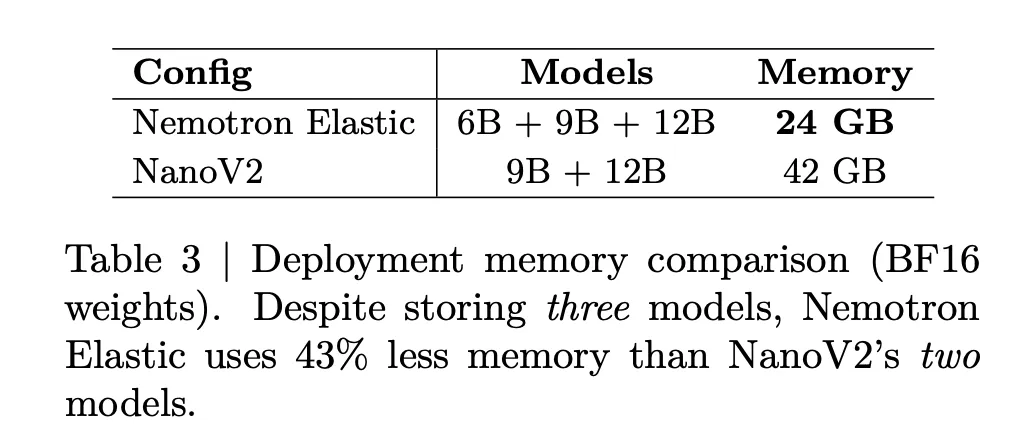
https://arxiv.org/pdf/2511.16664v1
比较
| 系统 | 尺寸 (B) | 平均推理分数* | 6B + 9B所需的标记 | BF16内存 |
|---|---|---|---|---|
| Nemotron Elastic | 6, 9, 12 | 70.61 / 75.95 / 77.41 | 110B | 24GB |
| NanoV2 Compression | 9, 12 | 75.99 / 77.38 | 750B | 42GB |
| Qwen3 | 8 | 72.68 | n / a | n / a |
关键要点
- Nemotron Elastic训练一个包含嵌套9B和6B变体的12B推理模型,这些变体可以通过零样本提取,无需额外的训练。
- 弹性家族使用混合Mamba-2和Transformer架构,以及一个学习到的路由器,该路由器通过在宽度和深度上应用结构化掩码来定义每个子模型。
- 该方法需要110B训练标记从12B父模型中派生6B和9B,这比750B令牌的Minitron SSM压缩基线少了大约7倍,比从头开始训练额外模型少了大约360倍。
- 在推理基准测试,如MATH 500、AIME 2024和2025、GPQA、LiveCodeBench和MMLU Pro上,6B、9B和12B弹性模型达到了平均分数约为70.61、75.95和77.41,这与或接近NanoV2基线,并与Qwen3-8B具有竞争力。
- 所有三个尺寸共享一个24GB BF16检查点,因此与约42GB的单独NanoV2-9B和12B模型相比,部署内存保持恒定,这为多级LLM部署简化了车队管理。总体而言,Nemotron-Elastic-12B将多尺寸推理LLM转换为单个弹性系统设计问题。
查看论文和模型权重。请随意检查我们的GitHub页面,包含教程、代码和笔记本。此外,请随意关注我们的Twitter,并别忘了加入我们的10k+机器学习SubReddit和订阅我们的时事通讯。等等!你使用Telegram吗?现在你可以在telegram上加入我们了。
文章NVIDIA AI发布Nemotron-Elastic-12B:一个无需额外训练成本的单一AI模型即可生成6B/9B/12B变体首先出现在MarkTechPost。
相关文章







