思科发布了思科时间序列模型:他们的第一个仅基于解码器Transformer架构的开放权重基础模型。
思科和Splunk推出了思科时间序列模型,这是一款针对可观测性和安全指标的单一变量的零样本时间序列基础模型。它是作为一个开放权重的检查点,在Hugging Face上以Apache 2.0许可发布,旨在为目标工作负载进行预测,而无需特定于任务的微调。该模型扩展了TimesFM 2.0,并采用显式的多分辨率架构,将粗略和详细历史数据融合在一个上下文窗口中。
https://arxiv.org/pdf/2511.19841
为什么可观测性需要多分辨率上下文?
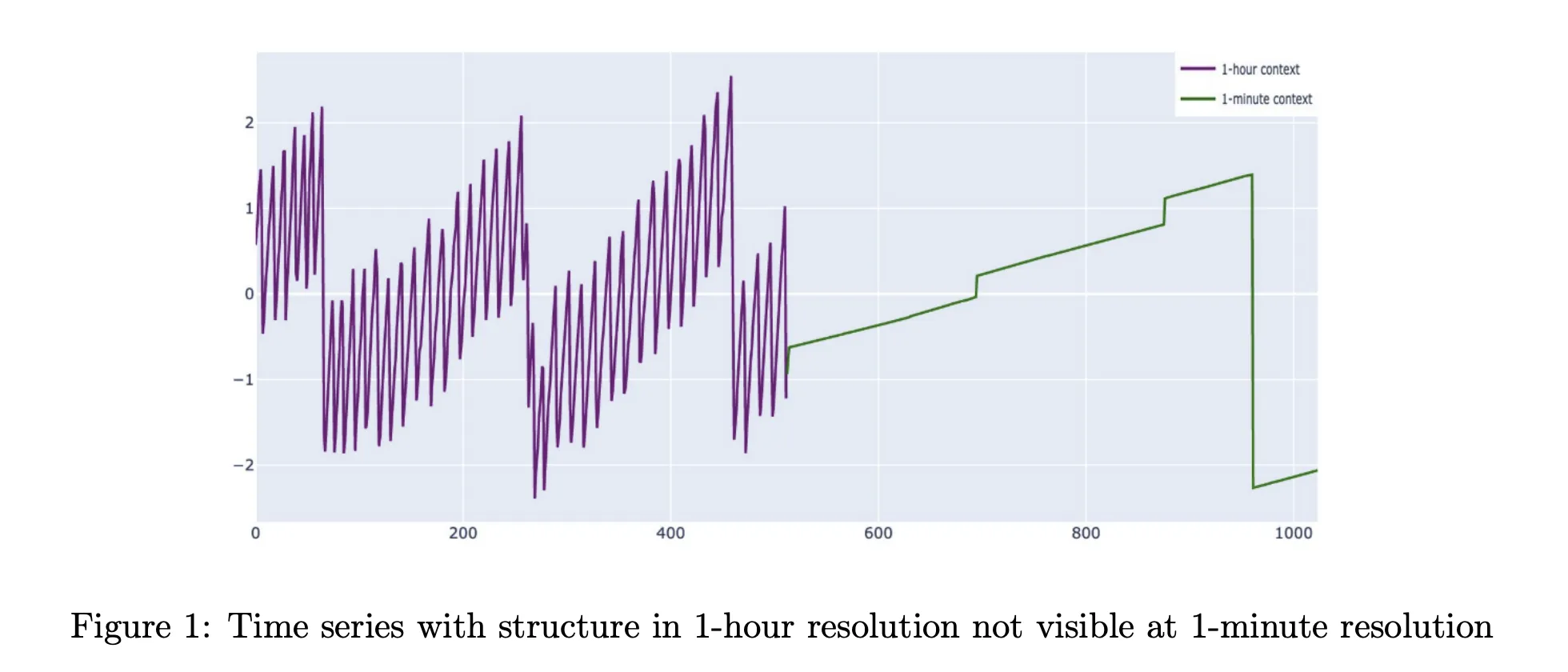
生产指标并非简单的单尺度信号。只有在大分辨率下,才能看到周周期、长期增长和饱和度。饱和事件、流量激增和事件动态仅在1分钟或5分钟分辨率下出现。常见的时间序列基础模型在单个分辨率上工作,上下文窗口在512到4096个点之间,而TimesFM 2.5将其扩展到16384个点。对于1分钟的数据,这最多覆盖几周,通常更少。
这是可观测性中一个问题,数据平台通常只保留旧数据的汇总形式。细粒度样本过期后,只有作为1小时汇总的形式存留下来。思科时间序列模型是为这种存储模式构建的。它将粗略历史视为一类输入,这有助于提高细粒度下的预测。该架构直接在多分辨率上下文上操作,而不是假装所有输入都活在单个网格上。
https://arxiv.org/pdf/2511.19841
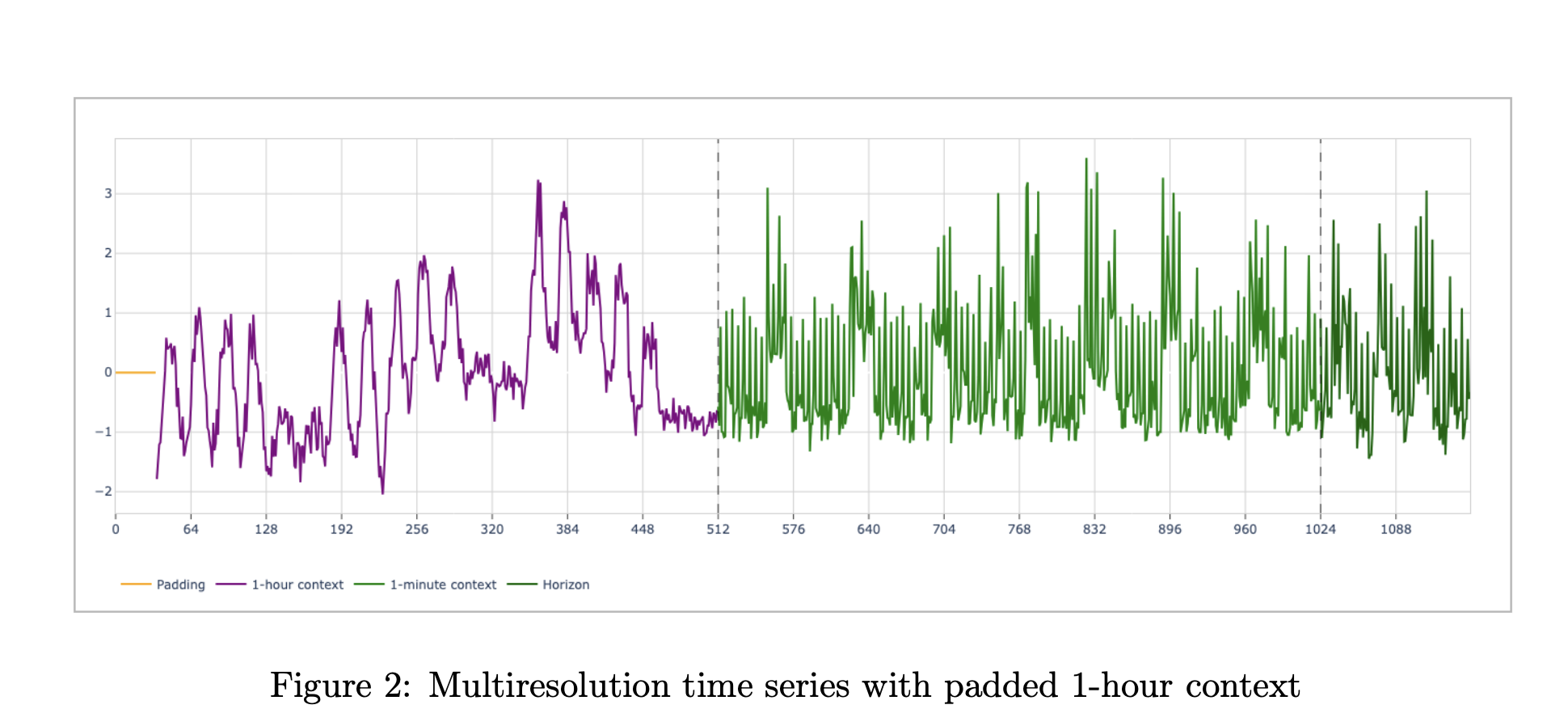
多分辨率输入和预测目标
正式来说,该模型消耗一对上下文,(xc, xf)。粗略上下文(x_c)和细略上下文(x_f)的长度最多为512。xc的间距是xf间距的60倍。典型的可观测性配置使用512小时的1小时汇总数据和512分钟的1分钟值。两个系列均在相同的预测截止点终止。该模型在细略分辨率下预测128个点的预测范围,输出包括0.1到0.9的一系列分位数。
架构、TimesFM核心与分辨率嵌入
内部,思科时间序列模型重用了基于TimesFM的解码器堆栈。输入被归一化,拼接到非重叠块中,并通过残差嵌入块传递。transformer核心由50个仅解码器层组成。最终的残差块将标记映射回预测范围。研究团队移除了位置嵌入,转而依靠拼贴顺序、多分辨率结构和新的分辨率嵌入来编码结构。
两个附加组件使架构成为多分辨率的。一个特殊标记,在报告中通常称为ST,被插入到粗略和细略标记流之间。它存在于序列空间中,并标记了分辨率之间的边界。分辨率嵌入,通常称为RE,添加在模型空间中。使用一个嵌入向量对所有的粗略标记,另一个对所有细略标记。论文中的消融研究显示,这两个组件都提高了质量,尤其是在长上下文场景中。
解码过程也是多分辨率的。模型为细略分辨率范围输出平均值和分位数预测。在长预测范围解码期间,新预测的细略点被追加到细略上下文中。预测的汇总更新粗略上下文。这创建了一个自回归循环,在预测过程中,两个分辨率共同发展。

https://arxiv.org/pdf/2511.19841
训练数据和配方
思科时间序列模型在上述_timesfm权益之上进行持续的预训练。最终的模型有5亿参数。训练使用AdamW进行偏差、范数和嵌入,Muon用于隐藏层,并使用余弦学习率计划。损失函数结合了平均平方误差和对0.1到0.9的分位数的分位数损失。团队训练了20个epoch,并通过验证损失选择最佳检查点。
数据集很大,偏向于可观测性。Splunk团队报告了从他们自己的Splunk Observability Cloud部署中收集的约4亿个指标时间序列,这些数据在13个月内以1分钟分辨率收集,部分汇总到5分钟分辨率。研究团队表示,最终语料库包含超过3000亿个独立数据点,约35%是1分钟可观测性,16.5%是5分钟可观测性,29.5%是GIFT Eval预训练数据,4.5%是Chronos数据集,14.5%是合成的KernelSynth系列。
在可观测性和GIFT Eval上的基准结果
研究团队在两个主要基准上评估了该模型。第一个是从Splunk 1分钟和5分钟分辨率的指标中导出的可观测性数据集。第二个是对GIFT Eval的过滤版本,其中从数据集中删除了泄漏TimesFM 2.0训练数据的集。
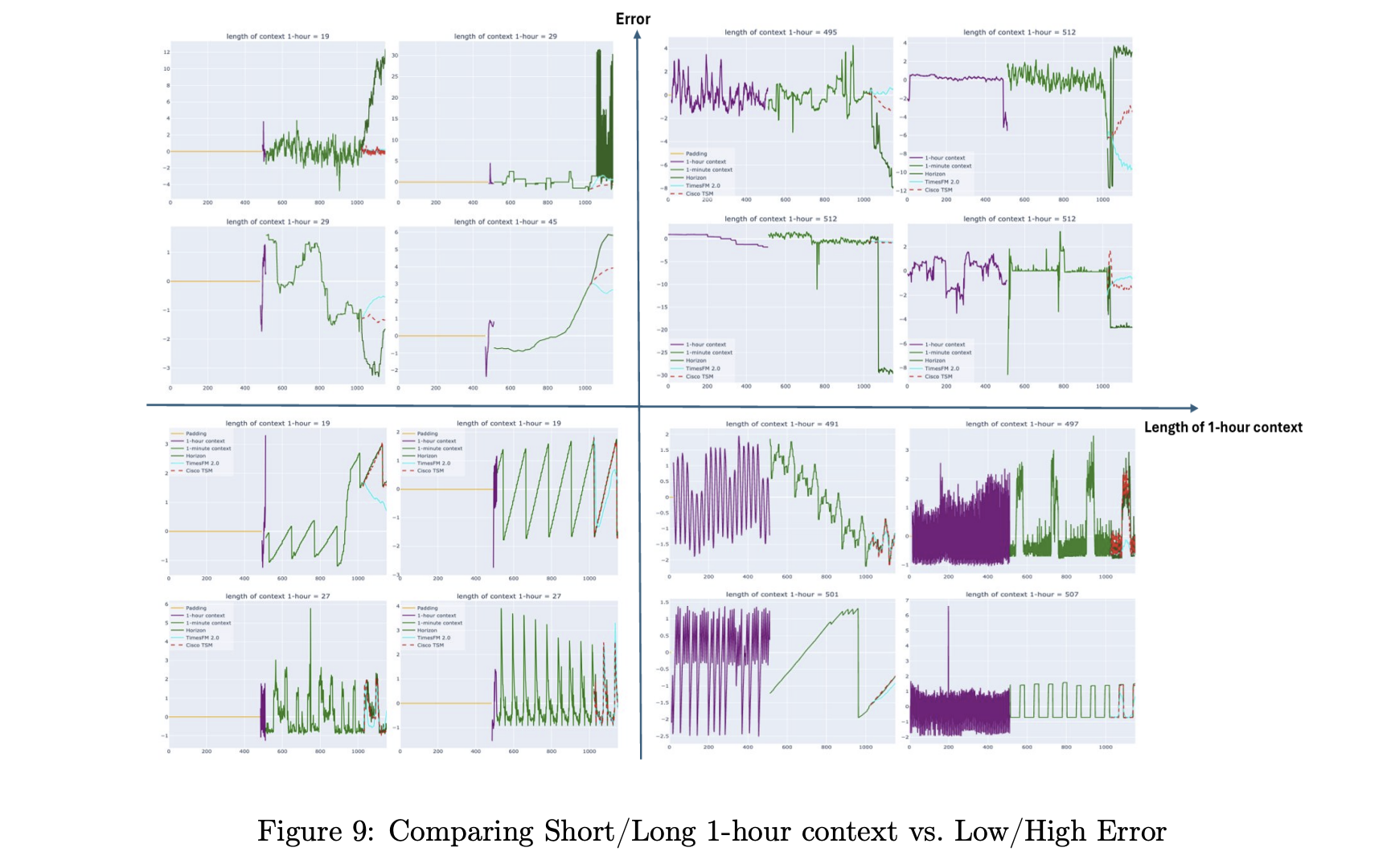
在512个细步的1分钟分辨率可观测性数据上,使用512多分辨率上下文的Cisco时间序列模型将TimesFM 2.5的0.6265的平均绝对误差和TimesFM 2.0的0.6315的平均绝对误差降低到0.4788,同时平均绝对缩放误差和连续排名概率分数也有类似的改进。类似的收益出现在5分钟分辨率上。在两个分辨率上,模型在论文中使用的规范度量下,优于Chronos 2、Chronos Bolt、Toto和AutoARIMA基准。
在过滤的GIFT Eval基准上,Cisco时间序列模型与基础TimesFM 2.0模型相当,并与TimesFM-2.5、Chronos-2和Toto具有竞争力。关键主张不是普遍支配,而是在长上下文窗口和可观测性工作负载上增加了强大的优势,同时保持了强劲的通用预测质量。
https://arxiv.org/pdf/2511.19841
主要要点
- 思科时间序列模型是一个单变量的零样本时间序列基础模型,它扩展了TimesFM 2.0仅解码器背骨,并将其应用于可观测性和安全度量,采用了一个多分辨率架构。
- 该模型消耗了一个多分辨率上下文,包括粗略序列和细略序列,每个最多512步长,其中粗略分辨率为细略分辨率的60倍,它预测128个细略分辨率步长,输出包括平均和0.1到0.9的分位数。
- 思科时间序列模型在3000亿个数据点上进行了训练,其中超过一半来自可观测性,混合了Splunk机器数据、GIFT Eval、Chronos数据集和合成的KernelSynth系列,并且具有约5亿参数。
- 在1分钟和5分钟分辨率的可观测性基准测试中,该模型实现了低于TimesFM 2.0的误差,同时在通用GIFT Eval基准测试上保持了有竞争力的性能。
查看论文、博客和HF上的模型卡。请随意查看我们的GitHub页面,包含教程、代码和笔记本。此外,请随意关注我们的Twitter,并别忘了加入我们的100k+机器学习SubReddit以及订阅我们的通讯。等等!你在Telegram上吗?现在你可以在Telegram上加入我们了。
文章思科发布思科时间序列模型:他们基于仅解码器Transformer架构的第一款开放权重基础模型最早出现在MarkTechPost。
相关文章







