智谱AI发布GLM-4.6V:一款128K上下文视觉语言模型,具备原生工具调用功能。
智谱AI开源了GLM-4.6V系列,作为一对视觉语言模型,将图像、视频和工具视为智能体的第一级输入,而不是作为附加在文本之上的额外考虑。
模型阵容和上下文长度
该系列包含2个模型。GLM-4.6V是一个面向云和高性能集群工作负载的,具有106B参数的基础模型。GLM-4.6V-Flash是一个经过调整的9B参数版本,适用于本地部署和低延迟使用。
GLM-4.6V将训练上下文窗口扩展到128K个令牌。在实践中,这支持大约150页的密集文档,200页幻灯片或一次通过一小时的视频,因为页面被编码为图像并被视觉编码器消费。
原生多模态工具使用
主要的技术变化是本地的多模态函数调用。在LLM系统中,传统工具使用方法将所有东西都通过文本路由。图像或页面首先被转换为描述,模型使用文本参数调用工具,然后读取文本响应。这浪费了信息并增加了延迟。
GLM-4.6V引入了本地的多模态函数调用。图像、屏幕截图和文档页面直接作为工具参数传递。工具可以返回搜索结果网格、图表、渲染的网页或产品图像。模型消耗这些视觉输出,并将它们与同一条推理链中的文本融合。这从感知到理解再到执行的闭环封闭,并明确定位为多模态智能体视觉感知和可执行动作之间的桥梁。
为了支持此功能,智谱AI扩展了模型上下文协议,使用基于URL的多模态处理。工具接收并返回用于标识特定图像或帧的URL,避免了文件大小限制,并允许在多图像上下文中进行精确选择。
丰富的文本内容、网络搜索和前端复制
智谱AI研究团队描述了4个典型场景:
首先,对丰富文本内容和创建的理解。GLM-4.6V读取混合输入,如论文、报告或幻灯片演示,并产生结构化的图像文本交错输出。它能理解同一文档中的文本、图表、图形、表格和公式。在生成过程中,它可以在图像上裁剪相关视觉元素或通过工具检索外部图像,然后运行一个视觉审查步骤,过滤低质量图像,并用内联图形组合最终文章。
第二,视觉网络搜索。模型可以检测用户意图,规划要调用的搜索工具,并结合文本到图像和图像到文本搜索。然后,它对检索到的图像和文本进行对齐,选择相关的证据,并输出结构化答案,例如产品或场所的视觉比较。
第三,前端复制和视觉交互。GLM-4.6V针对设计到代码工作流程进行了调整。从UI屏幕截图开始,它重建像素精确的HTML、CSS和JavaScript。然后,开发者可以在屏幕截图上标记一个区域,并发布自然语言指令,例如将此按钮向左移动或更改此卡片背景的颜色。模型将这些指令映射回代码,并返回更新后的代码片段。
第四,在长上下文中进行多模态文档理解。GLM-4.6V通过将页面视为图像读取多达128K个令牌的多文档输入。研究团队报告了一个案例,其中模型处理4家公开公司的财务报告,提取核心指标并构建比较表,以及模型总结整场足球比赛的同时,还能回答关于特定进球和时间戳的问题。
架构、数据和强化学习
GLM-4.6V模型属于GLM-V家族,基于GLM-4.5V和GLM-4.1V-Thinking的技术报告。研究团队强调了三个主要的技术成分。
首先,长序列建模。GLM-4.6V将训练上下文窗口扩展到128K个令牌,并在大规模长上下文图像文本语料库上进行持续预训练。它使用来自Glyph的压缩对齐思想,使视觉令牌可以携带与语言令牌对齐的密集信息。
其次,世界知识增强。智谱AI团队在预训练时添加了一个拥有十亿规模的多模态感知和世界知识数据集。这包括多层百科全书概念和日常视觉实体。目标是在基本感知和多模态问答完整性的基准上取得进展,而不仅仅是基准。
第三,智能体数据合成和扩展MCP。研究团队生成大型的合成轨迹,其中模型调用工具、处理视觉输出并在计划上迭代。他们通过基于URL的多模态处理和交错输出机制扩展了MCP。生成堆栈遵循草稿、图像选择、最终润色的顺序。模型可以在这些阶段之间自主调用裁剪或搜索工具,将图像放置在输出的正确位置。
工具调用是强化学习目标的一部分。GLM-4.6V使用强化学习来在复杂工具链中对齐计划、指令遵循和格式遵从。
性能
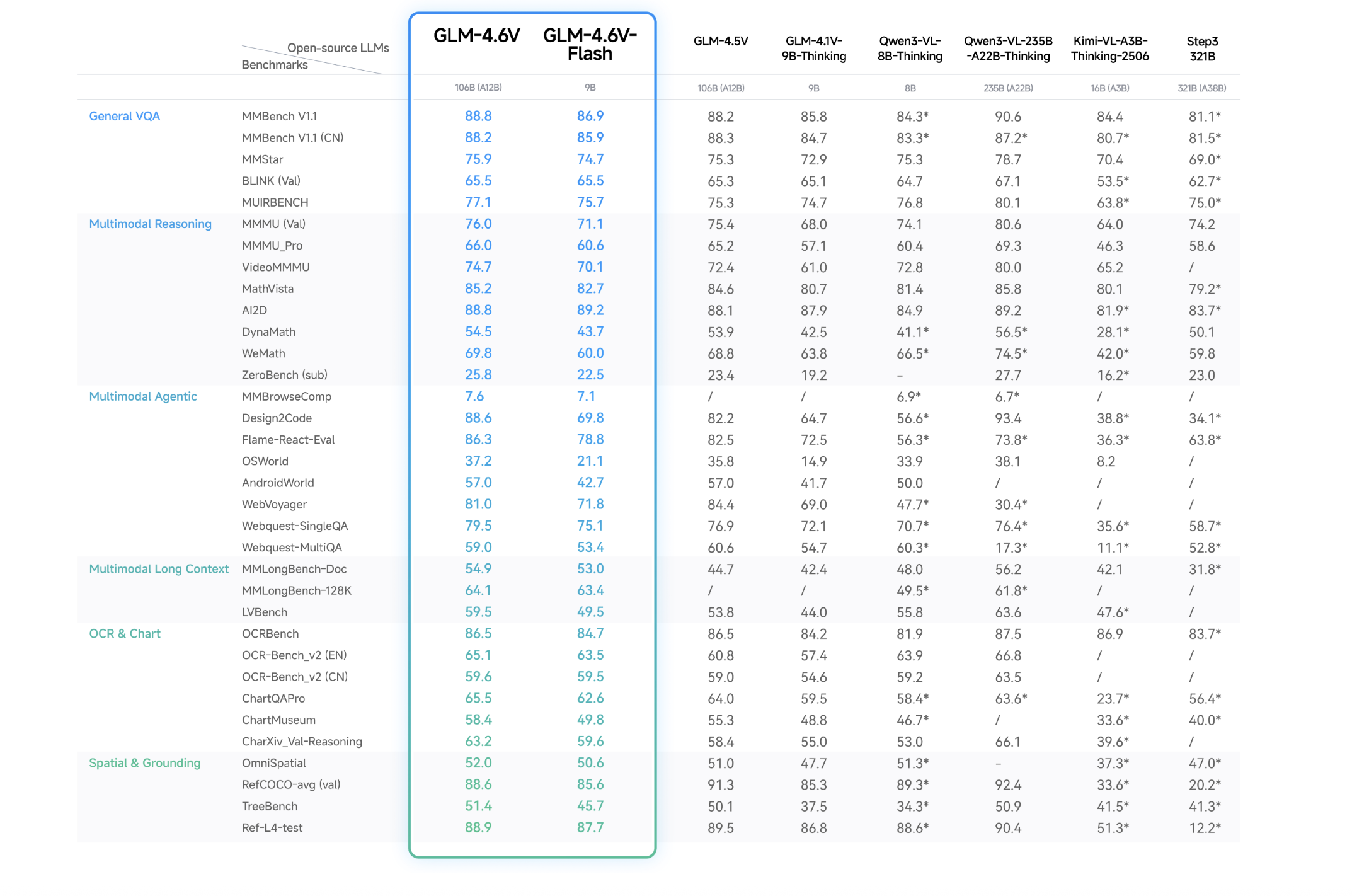
主要收获
- GLM-4.6V是一个具有128K个令牌训练上下文的106B多模态基础模型,而GLM-4.6V-Flash是一个针对本地和低延迟使用进行优化的9B版本。
- 这两个模型都支持本地的多模态函数调用,因此工具可以直接消耗和返回图像、视频帧和文档页面,将视觉感知与智能体的可执行动作连接起来。
- GLM-4.6V针对长上下文多模态理解和交错生成进行了训练,因此它可以读取大量的混合文档集,并在一次通过中输出带有内联图形和工具选择图像的结构化文本。
- 该系列在类似参数规模的主要多模态基准上进军,并在Hugging Face和ModelScope以MIT许可证发布开源权重。
查看HF上的模型卡片和技术细节。请随意查看我们GitHub页面上的教程、代码和笔记本。还可以关注我们的Twitter,也请加入我们的10万+机器学习SubReddit,并订阅我们的新闻快讯。等一下!你在Telegram上吗?你现在也可以加入我们。
首次发布智谱AI发布GLM-4.6V:一个拥有128K上下文的视觉语言模型,具有本地工具调用功能,首发于MarkTechPost。
相关文章







