NVIDIA AI发布了Nemotron 3:一款混合Mamba Transformer MoE堆栈,用于长上下文的 Agentic AI。
NVIDIA已发布了Nemotron 3系列开源模型,作为全面堆栈的一部分以支持代理人工智能,包括模型权重、数据集和强化学习工具。该系列有三种大小,分别是Nano、Super和Ultra,旨在针对需要长期上下文推理并对推理成本有严格控制的多元智能系统。Nano大约有300亿个参数,每个标记大约有30亿个活动参数,Super大约有1000亿个参数,每个标记最多有100亿个活动参数,而Ultra大约有5000亿个参数,每个标记最多有500亿个活动参数。
https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Nano-Technical-Report.pdf
模型系列和目标工作负载
Nemotron 3被定位为高效的开源模型系列,适用于代理应用程序。该系列包括Nano、Super和Ultra模型,每个模型都针对不同的工作负载配置进行了优化。
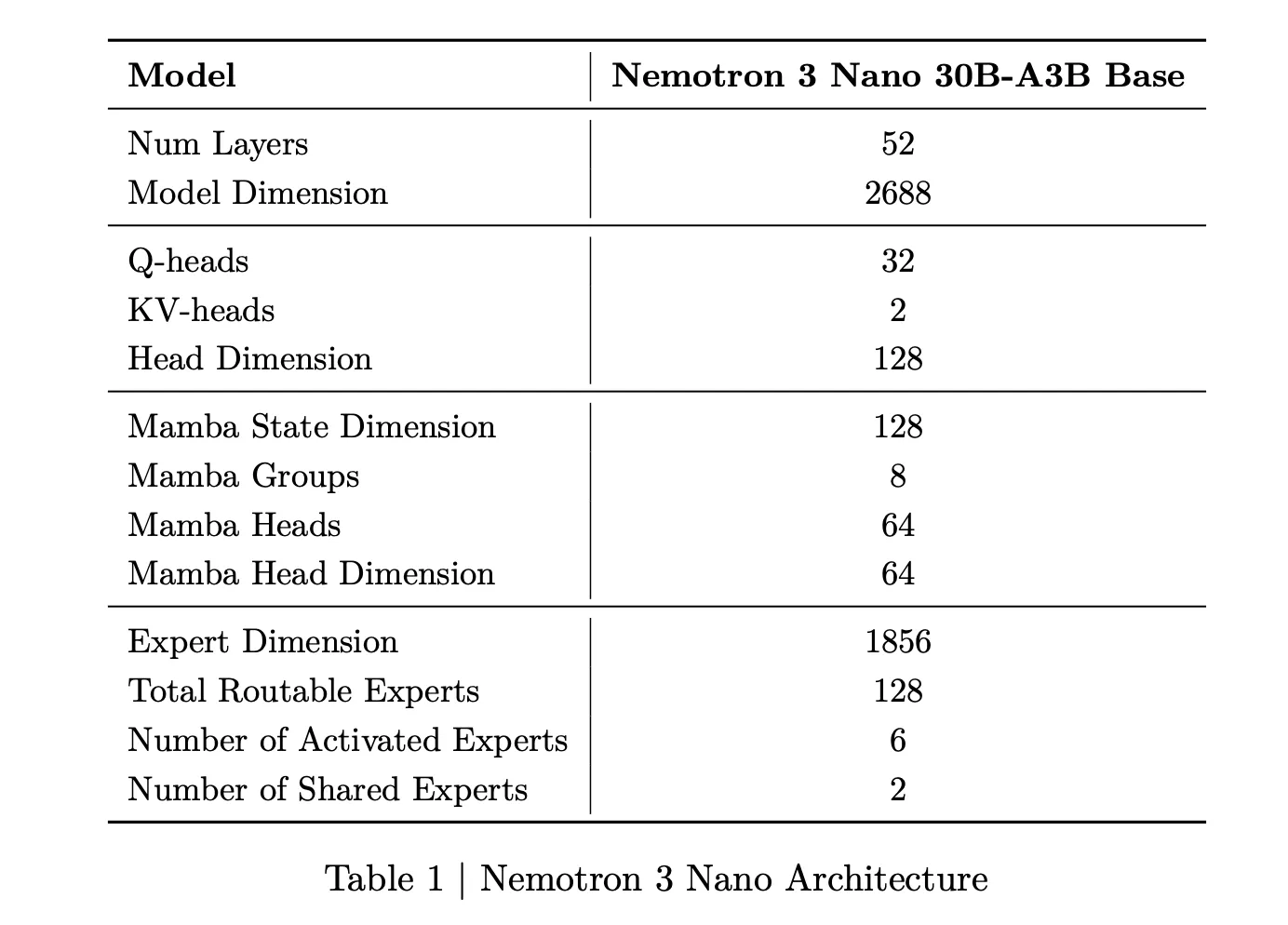
Nemotron 3 Nano是一款约31.6亿参数的混合专家Mamba Transformer语言模型。每个前向传递只有大约3.2亿个参数是活动的,包括嵌入体在内为36亿。这种稀疏激活使模型能够在保持高表示能力的同时降低计算量。
Nemotron 3 Super具有约1000亿个参数,每个标记最多有100亿个活动参数。Nemotron 3 Ultra将这种设计扩展到约5000亿个参数,每个标记最多有500亿个活动参数。Super旨在为大型的多元智能应用提供高精度推理,而Ultra旨在用于复杂的研发和一些工作流。
Nemotron 3 Nano目前已经以开放权重和食谱的形式提供,可在Hugging Face上使用,作为NVIDIA NIM微服务。Super和Ultra计划于2026年上半年推出。
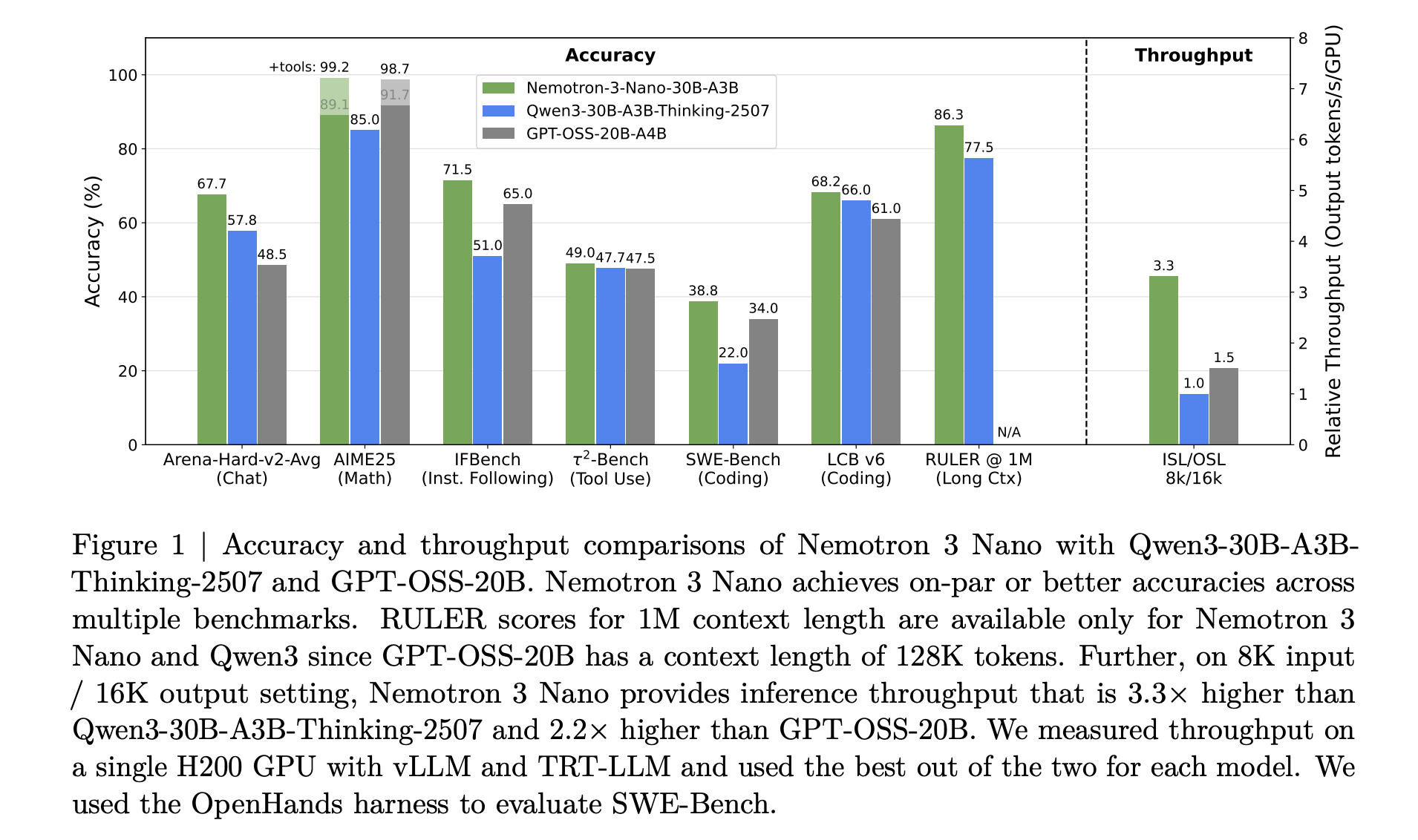
NVIDIA Nemotron 3 Nano的标记吞吐量比Nemotron 2 Nano高出约4倍,同时显著降低了推理标记的使用,同时支持长达1百万个标记的本地上下文长度。这种组合旨在用于操作在大工作空间中工作的多元智能系统,例如长文档和大型代码库。
https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Nano-Technical-Report.pdf
混合Mamba Transformer MoE架构
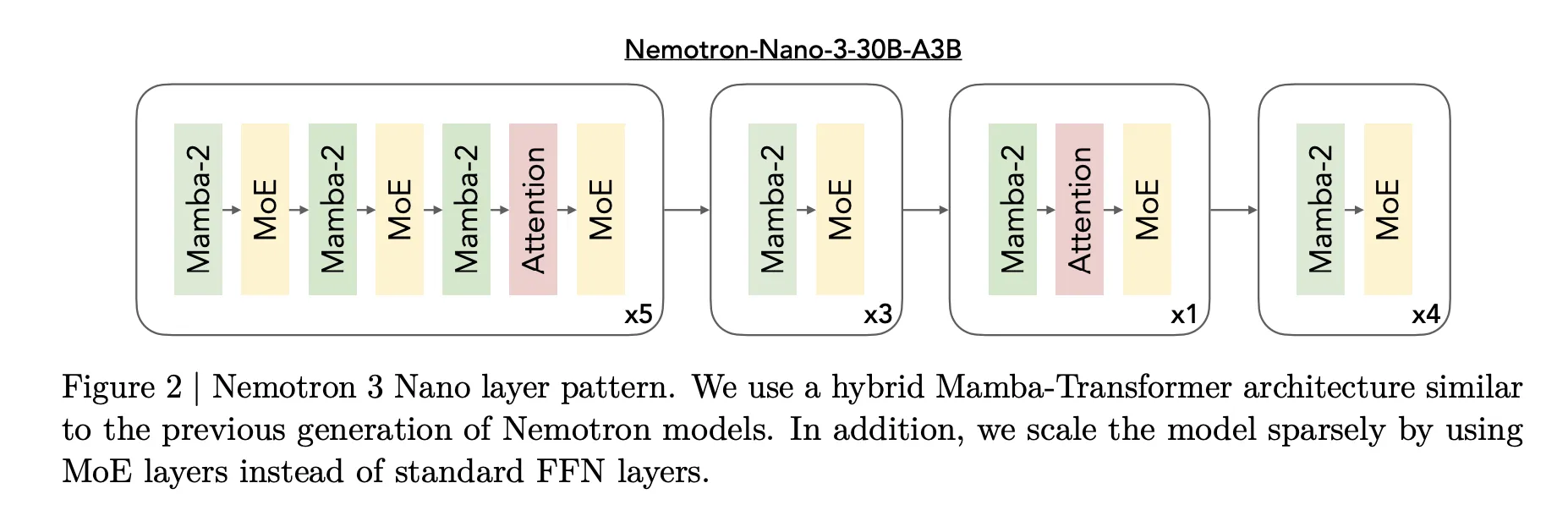
Nemotron 3的核心设计是一种混合专家Mamba Transformer架构。模型在单个堆栈内混合了Mamba序列块、注意力和稀疏专家块。
对于Nemotron 3 Nano,研究团队描述了一种模式,它交错使用Mamba 2块、注意力块和MoE块。与前几代Nemotron中的标准前馈层相比,MoE层取代了它们。一个学习路由器为每个标记选择专家的一个小型子集,例如Nano中的6个(128个可路由专家中的6个),在保持完全模型31.6亿参数的同时,使活动参数计数接近3.2亿。
https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Nano-Technical-Report.pdf
Mamba 2使用状态空间式更新处理长距离序列建模,注意力层提供结构敏感任务中标记到标记的直接交互,而MoE提供参数扩展,而无需成比例的计算扩展。重要的是,大多数层要么是快速序列或者稀疏专家计算,而全注意只在推理最重要的地方使用。
对于Nemotron 3 Super和Ultra,NVIDIA增加了LatentMoE。将标记投影到一个低维潜在空间中,专家在那种潜在空间中操作,然后将输出投影回去。这种设计允许以相似的总通信和计算成本支持更多专家,这支持了更多任务和语言之间的专业化。
Super和Ultra还包括多标记预测。多个输出头共享一个共同的树干,并在单个传递中预测几个未来的标记。在训练期间,这提高了优化,在推理期间,它能够实现像执行更少的前向传递那样的投机式解码。
训练数据、精度格式和上下文窗口
Nemotron 3在大型文本和代码数据上进行了训练。研究团队报告了在约2500万亿个标记上的预训练,比Nemotron 2产生了超过300亿个新的唯一标记。Nemotron 3 Nano使用Nemotron Common Crawl v2点1、Nemotron CC Code和Nemotron预训练代码v2,以及用于科学和推理内容的专用数据集。
Super和Ultra主要在NVFP4中训练,NVFP4是一种针对NVIDIA加速器优化的4位浮点格式。矩阵乘法操作在NVFP4中运行,而累积使用更高的精度。这降低了内存压力,提高了吞吐量,同时保持精度接近标准格式。
所有Nemotron 3模型支持最长可达1百万个标记的上下文窗口。架构和训练流程针对跨越这个长度的长期推理进行了调整,这对于传递大量痕迹和代理之间的共用工作内存的多代理环境至关重要。
主要结论
- Nemotron 3是针对代理人工智能的三层开源模型系列:Nemotron 3提供Nano、Super和Ultra三种变体。Nano大约有30亿个参数,每个标记大约有3亿个活动参数,Super大约有100亿个参数,每个标记最多有10亿个活动参数,Ultra大约有500亿个参数,每个标记最多有500亿个活动参数。该系列针对需要高效上下文推理的多代理应用。
- 具有百万标记上下文的混合Mamba Transformer MoE:Nemotron 3模型使用混合Mamba 2加上Transformer架构,有稀疏混合专家和支持百万标记的上下文窗口。这种设计为长上下文处理带来了高吞吐量,其中每个标记仅激活专家的小子集,并且只在推理最有用的时候使用注意力。
- Super和Ultra中的隐式MoE和多标记预测:Super和Ultra变体增加了在较小潜在空间中计算专家的隐式MoE,这降低了通信成本并允许更多的专家,以及多标记预测输出,每次前向传递生成多个未来的标记。这些变化提高了质量并使长文本和思维链工作负载能够实现投机式加速。
- 大规模训练数据和NVFP4精度以提高效率:Nemotron 3在约2500万亿个标记上进行预训练,比前一代产生了超过300亿个新标记,Super和Ultra主要在NVFP4上训练,这是一种针对NVIDIA GPU的4位浮点格式。这种组合提高了吞吐量并减少了内存使用,同时将精度保持在标准精度附近。
查看论文,技术博客和HF上的模型权重_.__。请随时查看我们的GitHub页面以获取教程、代码和笔记本。此外,请随时关注我们的Twitter并加入我们的100k+机器学习SubReddit和订阅我们的新闻简报。
文章NVIDIA AI发布Nemotron 3: 用于长期上下文代理人工智能的混合Mamba Transformer MoE堆栈首先发布在MarkTechPost。
相关文章







