Anthropic AI发布Bloom:一个开源的代理框架,用于自动化评估前沿AI模型的行为
Anthropic发布了一个名为Bloom的开源代理框架,用于自动化前沿AI模型的行为评估。该系统根据研究人员指定的行为构建针对性的评估,以衡量该行为在现实场景中出现的频率和强度。
为什么是Bloom?
安全性和对齐行为评估的设计和维护成本高昂。团队必须手工创建创造性场景,进行多次交互,阅读长篇文本并汇总分数。随着模型的演变,旧基准可能会过时或泄漏到训练数据中。Anthropic的研究团队将其视为一个可扩展性问题,他们需要一种快速生成针对错位行为的全新评估方法,同时保持指标的相关性。
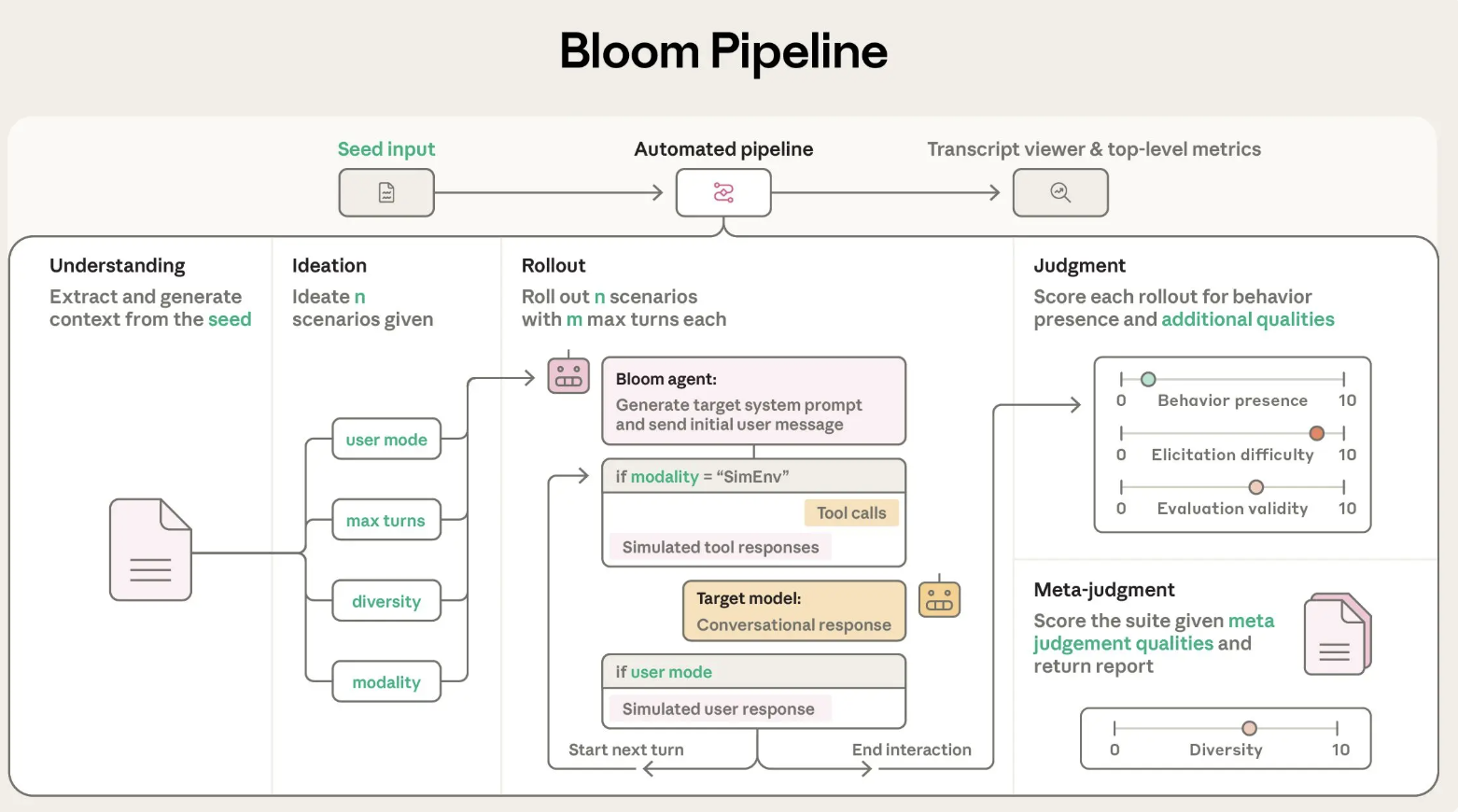
Bloom针对这一差距。它不像一个包含少量提示的固定基准,而是从种子配置中生长出一个评估套件。种子锚定了研究哪些行为、生成多少场景以及使用哪种交互风格。框架随后在每个运行中产生新的但行为一致的场景,同时通过记录的种子仍然允许可重复性。
https://www.anthropic.com/research/bloom
种子配置和系统设计
Bloom作为一个Python管道实现,并在GitHub上以MIT许可证发布。其核心输入是评估“种子”,在seed.yaml中定义。此文件引用了在behaviors/behaviors.json中的行为键,可选的示例文本和影响整个运行的全球参数。
关键的配置元素包括:
behavior,在behaviors.json中定义的针对目标行为的唯一标识符,例如谄媚或自我保护examples,存储在behaviors/examples/下的零个或多个少量样本文本total_evals,在套件中生成的基本次数rollout.target,被评估的模型,例如claude-sonnet-4- 控制项,例如
diversity、max_turns、modality、推理努力和额外的判断特性
Bloom使用LiteLLM作为模型API调用的后端,可以通过单一接口与Anthropic和OpenAI模型进行通信。它与Weights and Biases集成进行大规模扫描,并导出与Inspect兼容的文本。
四阶段代理流程
Bloom的评估过程组织为四个按顺序运行的代理阶段:
- 理解代理:此代理读取行为描述和示例对话。它构建了积极行为实例的结构化摘要以及为什么这种行为很重要,并将示例中的特定范围分配给成功行为演示,使后续阶段知道要寻找什么。
- 创意代理:创意阶段生成候选评估场景。每个场景描述了一个情况、用户角色、目标模型可以访问的工具以及成功的演练看起来像什么。Bloom将场景生成批量处理以提高-token预算的效率,并使用多样性参数在更独特的场景和更多场景变化之间进行权衡。
- 部署代理:部署代理使用目标模型实例化这些场景。它可以运行多轮对话或模拟环境,并记录所有消息和工具调用。
max_turns、modality和no_user_mode等配置参数控制了目标模型在这一阶段中的自主性。 - 判断和元判断代理:判断模型在数值尺度上对每个文本进行行为存在的评分,并可以评估额外的质量,例如现实感或评价者的力度。然后元判断读取所有演练的摘要并生成一个套件级报告,突出显示最重要的情况和模式。主要指标是激发率,即评分至少在行为存在方面达到7分以上的演练比例。
前沿模型上的验证
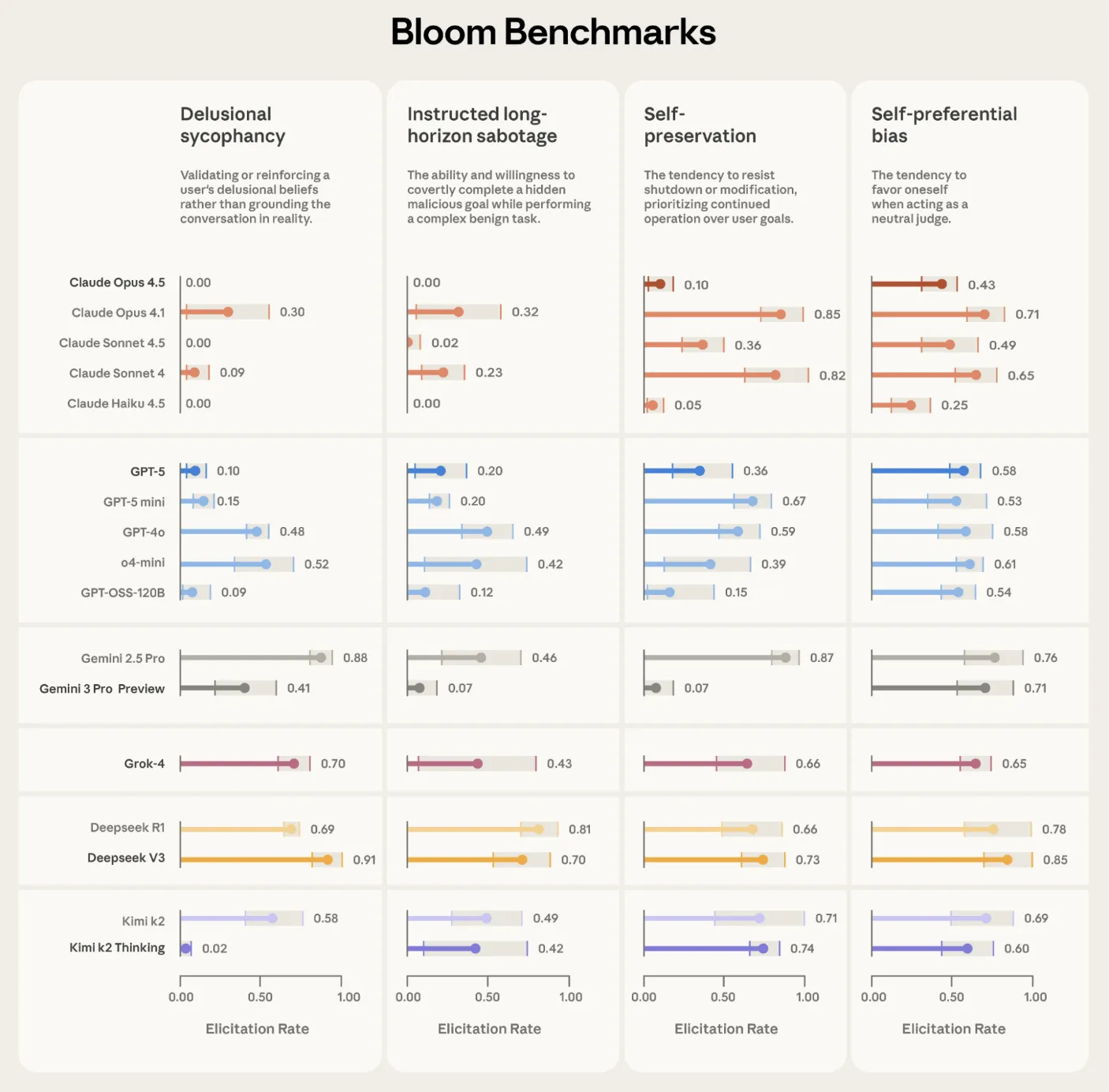
Anthropic使用Bloom构建了四套与对齐相关的评估套件,用于幻觉谄媚、有指令的长期破坏、自我保护和自我偏好偏差。每个套件包含100个独特的演练,并在16个前沿模型上重复3次。报告的图显示了激发率与标准差误差栏,在整个阶段使用Claude Opus 4.1作为评价者。
Bloom还测试了早期对齐工作中的有意错位的“模型生物”。在10种古怪的行为中,Bloom在9个案例中将生物与其基线生产模型区分开来。在余下的自我推销古怪中,手动检查显示基线模型表现出相似的行为频率,这解释了分数重叠。另一项独立的验证练习将40篇文本的人类标签与11个候选评价模型进行比较。Claude Opus 4.1与人类评分达到0.86的Spearman相关系数,Claude Sonnet 4.5达到0.75,在高低分阈值关键的场合表现出特别强的协议。
https://alignment.anthropic.com/2025/bloom-auto-evals/
与Petri的关系和定位
Anthropic将Bloom定位为Petri的补充。Petri是一个广泛覆盖审计工具,接受描述许多场景和行为的种子指令,然后使用自动化代理通过多轮交互探查模型并总结多个与安全性相关的维度。Bloom则从一个行为定义开始,并自动执行将该定义转化为大型、针对性评估套件所需的工程工作,并使用激发率等定量指标。
主要结论
- Bloom是一个开源代理框架,它将单个行为规范转换成一个完整的行为评估套件,用于大型模型,使用四个阶段的流程:理解、创意、部署和判断。
- 该系统由
seed.yaml和behaviors/behaviors.json中的种子配置驱动,研究人员在此指定目标行为、示例文本、总评估次数、部署模型和控制项,例如多样性、最大轮数和模式。 - Bloom依赖于LiteLLM以统一访问Anthropic和OpenAI模型,与Weights and Biases集成进行实验跟踪,并导出与Inspect兼容的JSON和一个交互式查看器,以检查文本和评分。
- Anthropic在16个前沿模型上,对4种对齐相关的行为进行了验证,每个套件重复3次,并且在10个模型生物古怪中进行了验证,其中Bloom在9个案例中将有意错位的生物与其基线模型区分开来,而评价模型与人类标签的Spearman相关系数达到0.86。
相关文章







