Meta AI开源感知编码器音频视觉(PE-AV):驱动SAM音频和大规模多模态检索的音频视觉编码器
Meta研究人员推出了感知编码器音频视觉(PEAV),作为用于联合音频和视频理解的新一代编码器家族。该模型通过在约1000万个带文本标题的音频视频对上进行大规模对比训练,在单个嵌入空间中学习了对齐的音频、视频和文本表示。
从感知编码器到PEAV
感知编码器(PE)是Meta感知模型项目中核心的视觉栈。它是一系列针对图像、视频和音频的编码器,通过统一的对比性预训练配方在各种视觉和音频基准测试中达到了最先进的水平。PE核心在图像任务上超过了SigLIP2,在视频任务上超过了InternVideo2。PE Lang为感知语言模型提供多模态推理能力。PE spatial为密集预测任务(如检测和深度估计)进行了调整。
PEAV在此基础上进行了扩展,实现了完整的音频视频文本对齐。在感知模型存储库中,PE音频视觉被列为将音频、视频、音频视频和文本嵌入到单个联合嵌入空间以进行跨模态理解的分支。
{kind=link}
架构,分离塔和融合
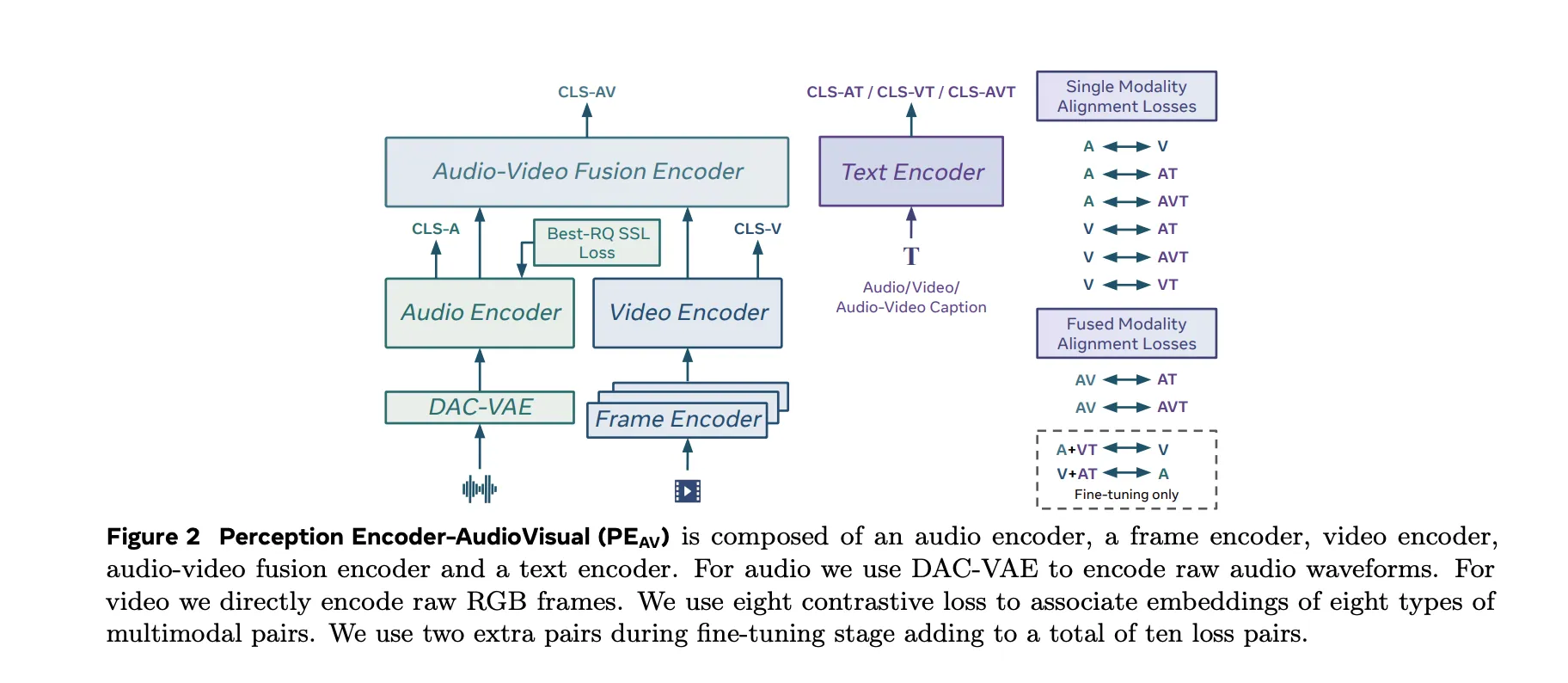
PEAV架构由帧编码器、视频编码器、音频编码器、音频视频融合编码器和文本编码器组成。
- 视频路径使用现有的PE帧编码器对RGB帧进行处理,然后在帧级特征上应用时间视频编码器。
- 音频路径使用DAC VAE作为编解码器,以固定帧率将原始波形转换为离散音频标记,大约每40毫秒一个嵌入。
这些塔向音频视频融合编码器提供输入,该编码器学习两种流共享的表示。文本编码器将文本查询投影到几个专门的空间。在实践中,这提供了可以通过多种方式查询的单个骨干。您可以从文本检索视频,从文本检索音频,从视频检索音频,或者根据任何模态组合检索条件化的文本描述,而不需要重新训练特定任务的头部。
{kind=link}
数据引擎,大规模合成音频视频标题
研究团队提出了一种两阶段音频视频数据引擎,为未标记的片段生成高质量合成字幕。团队描述了一个流程,首先使用几个弱音频字幕模型、它们的置信度得分和单独的视频字幕器作为输入,输入到大型语言模型中。该LLM为每个片段生成三种字幕类型,一个是音频内容,一个是视觉内容,一个是联合音频视觉内容。在第一阶段,这个初始的PE AV模型在这个合成监督下进行训练。
在第二阶段,这个初始PEAV与感知语言模型解码器配对。它们一起微调字幕,以更好地利用音频视觉对应关系。两个阶段的引擎为大约1000万个音频视频对生成了可靠的字幕,并使用大约9200万个独特的剪辑进行第一阶段预训练,以及3200万个额外的独特剪辑进行第二阶段微调。
与通常关注语音或狭窄声音域的先前工作相比,这个语料库旨在平衡语音、一般声音、音乐和各种视频域,这对于通用的音频视觉检索和理解很重要。
十组模态的对比目标
PEAV使用基于Sigmoid的对音频、视频、文本和融合表示进行对比性损失的跨模态目标。研究团队解释说,在预训练过程中,该模型使用了八组对比性损失。这包括音频文本、视频文本、音频视频文本以及与融合相关的组合。在微调期间,增加了两个额外的组合,使得不同模态和字幕类型之间的损失对达到十个。
这个目标在形式上类似于最近视觉语言编码器使用的对比性目标,但推广到音频视频文本三模态训练。通过将这些视图对齐在同一个空间中,相同的编码器可以通过简单的点积相似度支持分类、检索和对应任务。
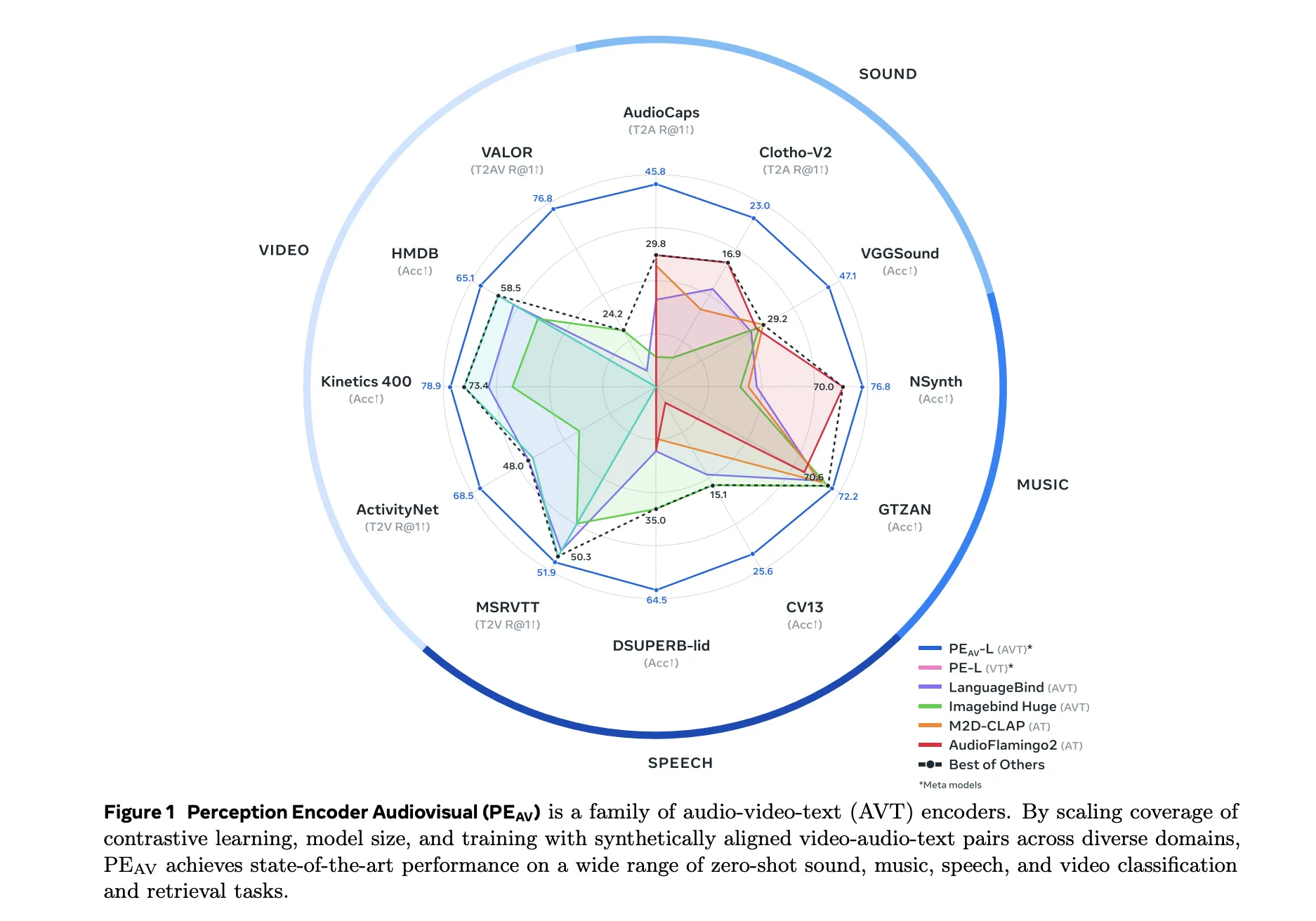
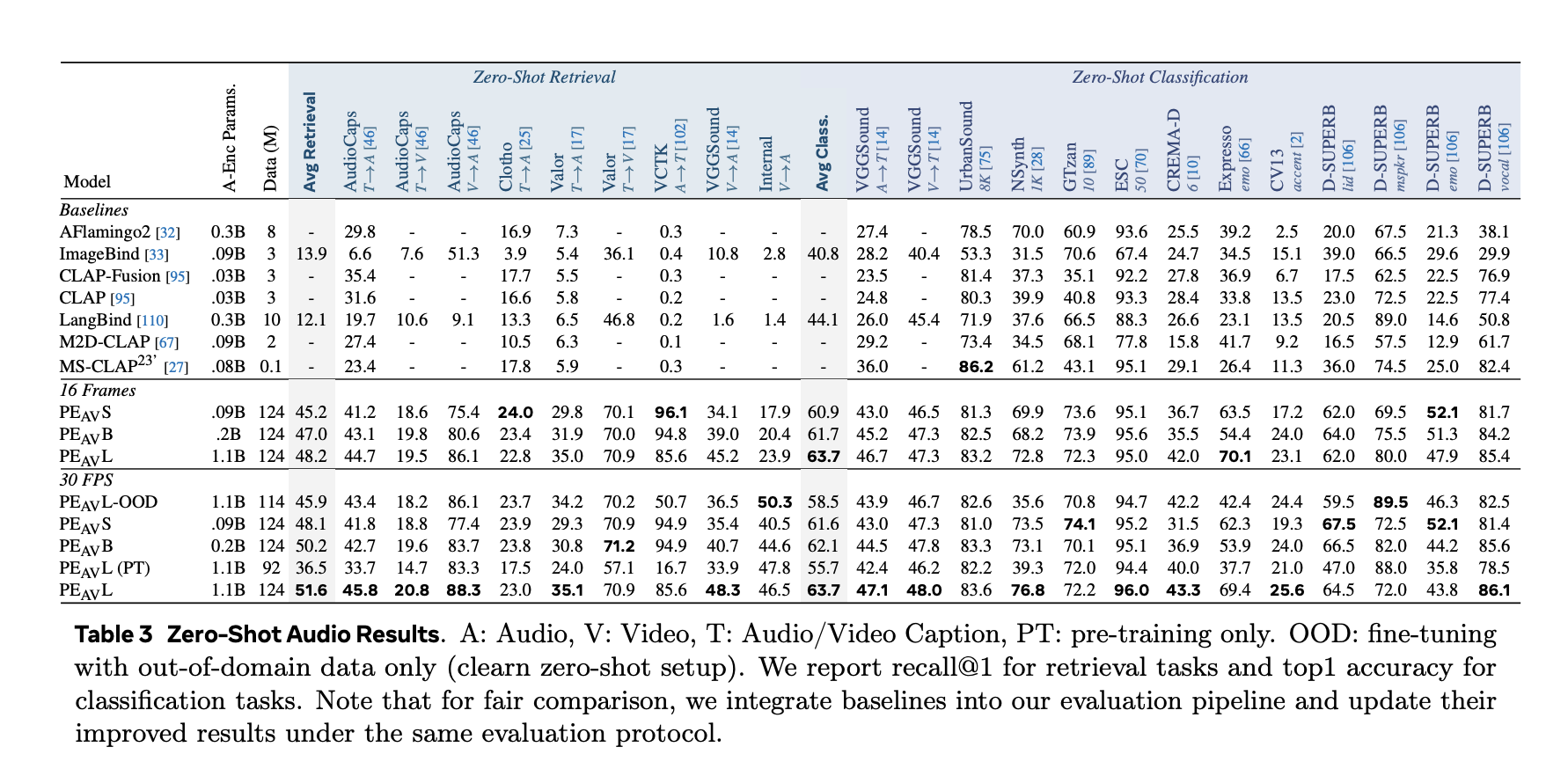
音频、语音、音乐和视频上的性能
在基准测试中,PEAV针对多个域的目标是零样本检索和分类。PE AV与CLAP、Audio Flamingo、ImageBind和LanguageBind等工作的音频文本和音频视频文本模型的最近表现相比,在几个音频和视频基准上实现了最先进的表现。
具体收益包括:
- 在AudioCaps上,文本到音频检索从1的35.4 R提高到了1的45.8 R。
- 在VGGSound上,剪辑级分类精度从36.0提高到47.1。
- 在VCTK样式任务上的语音检索,PE AV达到了85.6的准确率,而早期模型接近0。
- 在ActivityNet上,文本到视频检索从1的60.4 R提高到了1的66.5 R。
- 在Kinetics 400上,零样本视频分类从76.9提高到78.9,打败了2到4倍的模型。
{kind=link}
PEA-Frame,帧级音频文本对齐
与PEAV一起,Meta发布了感知编码器音频帧(PEA-Frame),用于声音事件定位。PE A Frame是一个音频文本嵌入模型,每40毫秒的帧输出一个音频嵌入,每个查询输出一个文本嵌入。该模型可以返回时间跨度,标记在音频中每个描述的事件发生的位置。
PEA-Frame使用帧级对比性学习对齐音频帧与文本。这使事件(如特定说话者、乐器或瞬态声音)在长音频序列中的精确定位成为可能。
在感知模型和SAM音频生态系统中的作用
PEAV和PEA-Frame位于更广泛的感知模型堆栈内部,该堆栈将PE编码器与感知语言模型结合,用于多模态生成和推理。
PEAV也是Meta新SAM音频模型和其Judge评估器的核心感知引擎。SAM Audio使用PEAV嵌入将视觉提示和文本提示与复杂混合中的声音源连接起来,并为分离的音频轨道评分质量。
主要要点
- PEAV是一个针对音频、视频和文本的统一编码器,通过在超过1000万个视频中应用对比性学习进行训练,并将音频、视频、音频视频和文本嵌入到单个联合空间中,以进行跨模态检索和理解。
- 架构使用分别的视频和音频塔,基于PE的视觉编码和DAC VAE音频标记化,随后是音频视频融合编码器和与不同模态对对齐的专业文本头部。
- 两个阶段的数据引擎使用较弱的字幕器加上LLM在第一阶段,以及PEAV加上感知语言模型在第二阶段,生成合成音频、视觉和音频视觉字幕,从而实现无需手动标签的大型多模态监督。
- PEAV通过在多个模态对上使用Sigmoid对比性目标,在广泛的音频和视频基准上建立了新标准,提供了从小16帧到大型全帧变体的六个公共检查点,其中平均检索从大约45提高到51.6。
- PEAV与帧级PEA-Frame变体一起,形成了Meta SAM音频系统的感知骨干,可提供用于基于提示的音频分离和精细粒度语音、音乐和一般声音中的声音事件定位的嵌入。
也欢迎关注我们的推特和参与我们的100k+ ML SubReddit,并订阅我们的时事通讯。等等!你在电报上吗?现在你可以在电报上加入我们了。
原文链接Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval首次出现在MarkTechPost。
相关文章







