Moonshot AI 发布 Kimi K2.5:一个具有原生蜂群执行的开放源代码视觉智能模型
Moonshot AI 已将 Kimi K2.5 作为开源视觉智能代理模型发布。它结合了一个大型混合专家语言骨干、一个原生视觉编码器以及一个名为 Agent Swarm 的并行多代理系统。该模型针对编码、多模态推理和深度网络研究,在智能、视觉和编码套件上有强大的基准结果。
模型架构和训练
Kimi K2.5 是一个混合专家模型,拥有 1T 总参数,每个标记约 32B 激活参数。网络有 61 层。它使用 384 个专家,每个标记选择 8 个专家加 1 个共享专家。注意力隐藏大小为 7168,有 64 个注意力头。
模型使用 MLA 注意力和 SwiGLU 激活函数。标记器词汇大小为 160K。训练和推理过程中的最大上下文长度为 256K 个标记。这支持长工具轨迹、长文档和多步研究工作流程。
视觉由 MoonViT 编码器处理,参数约为 400M。视觉标记与文本标记一起在单个多模态骨干中进行训练。Kimi K2.5 是在 Kimi K2 Base 上进行持续预训练,约 15T 混合视觉和文本数据获得的。这种原生多模态训练很重要,因为它从一开始就使模型从图像、文档和语言中学习联合结构。
发布的确认点支持标准推断堆栈,如 vLLM、SGLang 和 KTransformers,包含版本 4.57.1 或更新的 transformer。提供了量化 INT4 变体,重用了 Kimi K2 Thinking 中的方法。这允许在内存预算更低的价格位通用 GPU 上部署。
编码和多模态功能
Kimi K2.5 被定位为一个强大的开源编码模型,尤其是在代码生成依赖于视觉上下文时。该模型可以阅读 UI 模拟、设计截图,甚至视频,然后输出具有布局、样式和交互逻辑的结构化前端代码。
Moonshot 展示了模型阅读拼图图像、推理最短路径,然后编写代码以生成可视化解决方案的示例。这展示了跨模态推理,模型在单个流中将图像理解、算法规划和代码综合结合起来。
由于 K2.5 有 256K 的上下文窗口,它可以在上下文中保留长期规范历史。为开发者提供的一种实际工作流程是将设计资产、产品文档和现有代码混合在一个提示中。然后模型可以在保持与原始设计的视觉约束一致的情况下重构或扩展代码库。

https://www.kimi.com/blog/kimi-k2-5.html?
Agent Swarm 和并行代理强化学习
Kimi K2.5 的一个关键特性是 Agent Swarm。这是一个使用并行代理强化学习(PARL)训练的多代理系统。在这个设置中,指挥代理将复杂目标分解成许多子任务,然后启动特定领域的子代理并行工作。
Kimi 团队报告称,K2.5 可管理一个任务中的多达 100 个子代理。它在一个运行中支持多达 1,500 个协调步骤或工具调用。这种并行性使得在广泛的搜索任务上与单个代理管道相比,完成速度快约 4.5 倍。
PARL 引入了一个名为关键步骤的指标。系统奖励那些减少解决任务所需的串行步骤数量的策略。这阻止了原始顺序规划,并推动代理将工作分成并行分支,同时仍然保持一致性。
Kimi 团队的一个示例是一个研究工作流程,其中系统需要发现许多利基创作者。指挥代理使用 Agent Swarm 启动大量研究人员代理。每个代理探索网络的不同区域,然后将结果合并成一个结构化表格。
https://www.kimi.com/blog/kimi-k2-5.html?
基准性能
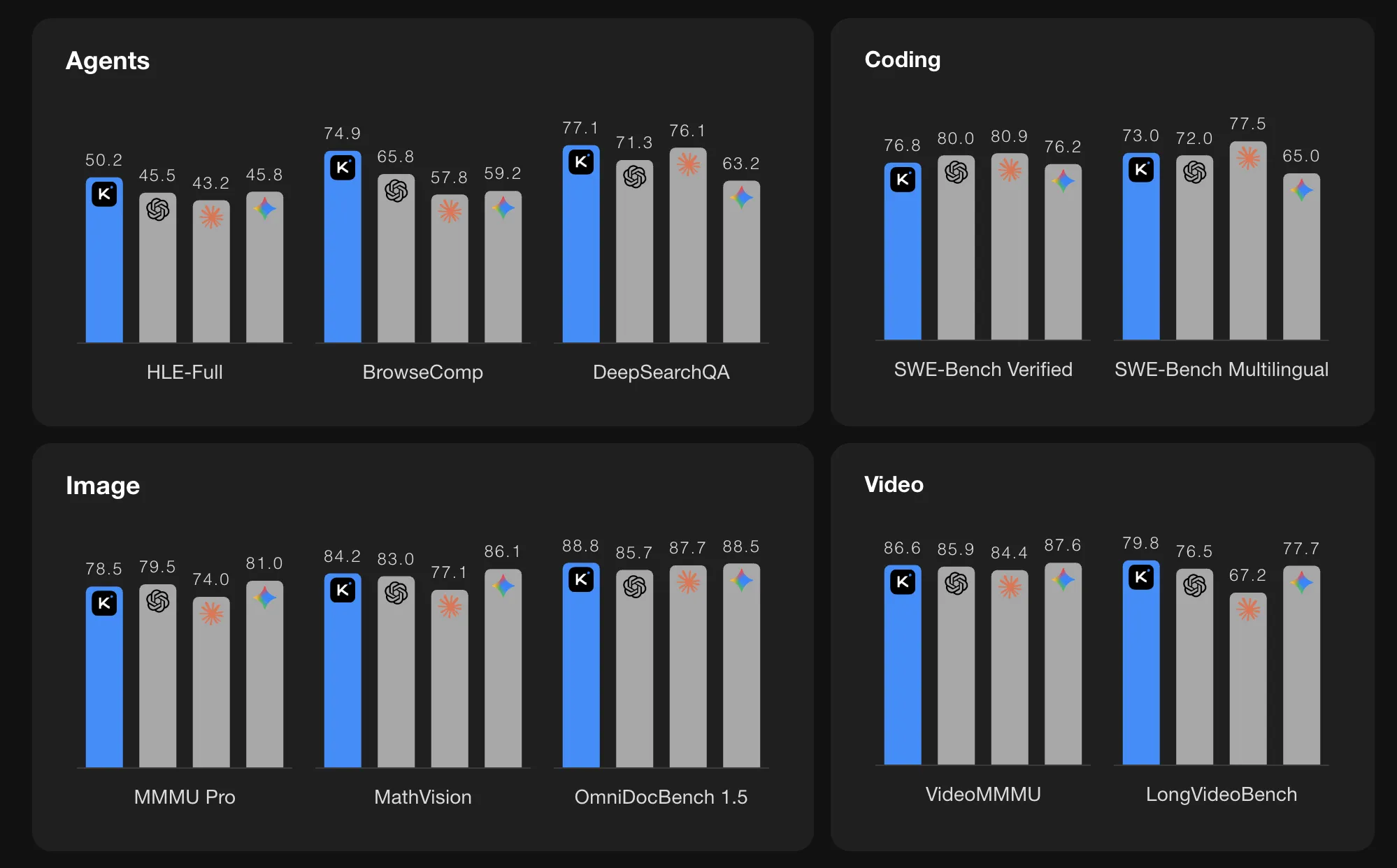
在智能基准测试中,Kimi K2.5 报告了强大的数字。在带有工具的 HLE Full 上的分数为 50.2。在带有上下文管理的 BrowseComp 上的分数为 74.9。在代理 Swarm 模式下,BrowseComp 分数进一步增加到 78.4,广泛的搜索指标也得到改善。Kimi 团队将这些值与 GPT 5.2、Claude 4.5、Gemini 3 Pro 和 DeepSeek V3 进行比较,K2.5 在这些特定的智能套件中列出的模型中显示出最高的分数。
在视觉和视频基准测试中,K2.5 也报告了高分。MMMU Pro 为 78.5,VideoMMMU 为 86.6。该模型在 OmniDocBench、OCRBench、WorldVQA 和其他文档和场景理解任务上表现良好。这些结果表明 MoonViT 编码器和长上下文训练对现实世界多模态问题(如阅读复杂文档和视频推理)是有效的。

https://www.kimi.com/blog/kimi-k2-5.html?
在编码基准测试中,它列出了 SWE Bench Verified 为 76.8,SWE Bench Pro 为 50.7,SWE Bench Multilingual 为 73.0,Terminal Bench 2.0 为 50.8,LiveCodeBench v6 为 85.0。这些数字将 K2.5 排入目前在这些任务上报告的最强大的开源编码模型之列。
在长上下文语言基准测试中,K2.5 在标准评估设置下达到 61.0 在 LongBench V2,以及 70.0 在 AA LCR。对于推理基准,当在思考模式中使用时,它实现了在 AIME 2025、HMMT 2025 二月、GPQA Diamond 和 MMLU Pro 上取得高分。
主要结论
- 万亿规模的混合专家:Kimi K2.5 使用一个混合专家架构,总参数为 1T,每个标记约 32B 激活参数,61 层,384 个专家,256K 的上下文长度,针对长多模态和工具密集型工作流程进行优化。
- MoonViT 的原生多模态训练:该模型集成了一个参数约为 400M 的 MoonViT 视觉编码器,并在 Kimi K2 Base 上关于 15T 混合视觉和文本标记进行持续预训练,因此图像、文档和语言在单个统一的骨干中得到处理。
- 使用 PARL 的并行代理 Swarm:Agent Swarm,使用并行代理强化学习(PARL)训练,可以协调每个任务中的多达 100 个子代理和约 1,500 个工具调用,与单个代理相比,在广泛的调查任务上提供约 4.5 倍的执行速度。
- 在编码、视觉和代理方面有强大的基准结果:K2.5 报告了 SWE Bench Verified 的 76.8、MMMU Pro 的 78.5、VideoMMMU 的 86.6、带有工具的 HLE Full 的 50.2 和 BrowseComp 的 74.9,在几个智能和多模态套件中匹配或超过了列出的封闭模型。
相关文章







