DSGym提供了一种可重复使用的容器化基础层,用于构建和基准测试数据科学代理。
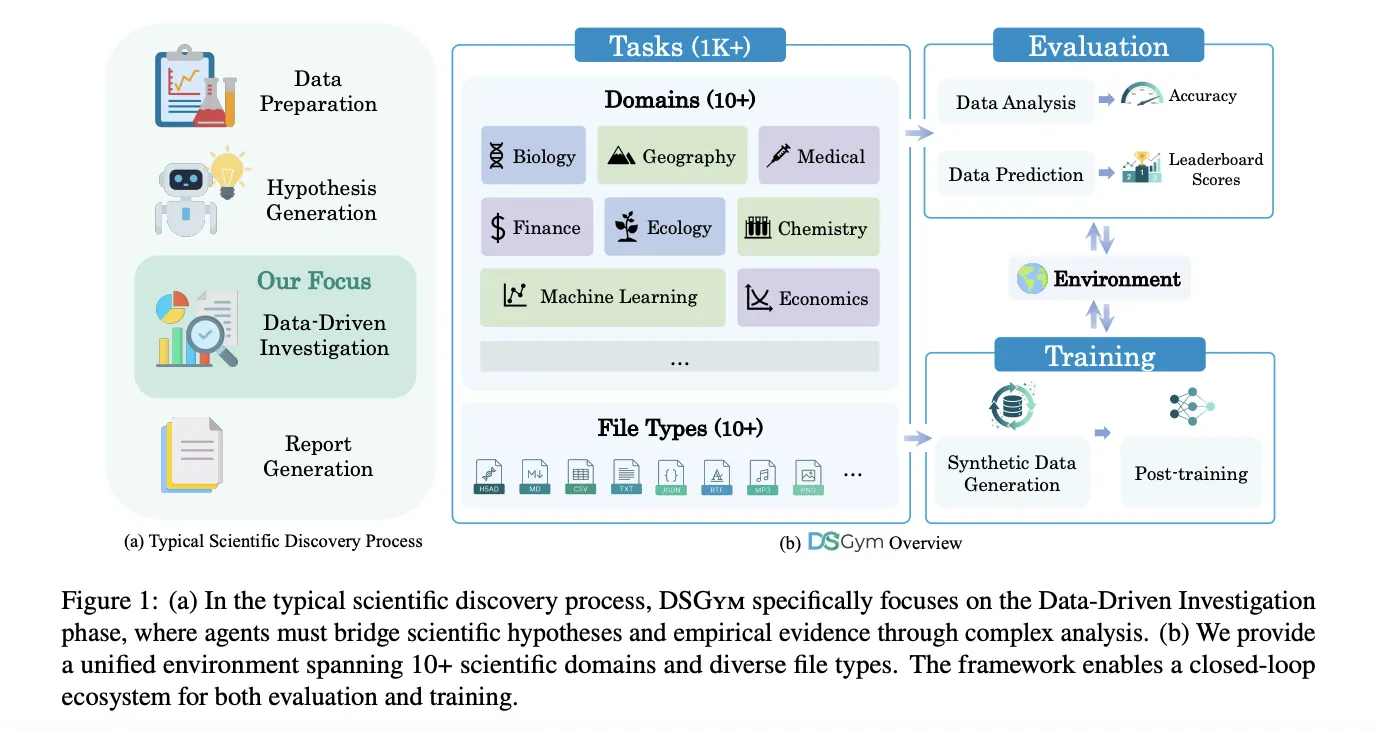
科学数据代理应该检查数据集、设计工作流程、运行代码并返回可验证的答案,而不仅仅是自动完成Pandas代码。由斯坦福大学、Together AI、杜克大学和哈佛大学的研究者共同推出的DSGym是一个框架,该框架通过具有专家精心编辑的地面真值和一致的培训后管道,在超过1000个数据科学挑战中评估和训练这样的代理。
https://arxiv.org/pdf/2601.16344
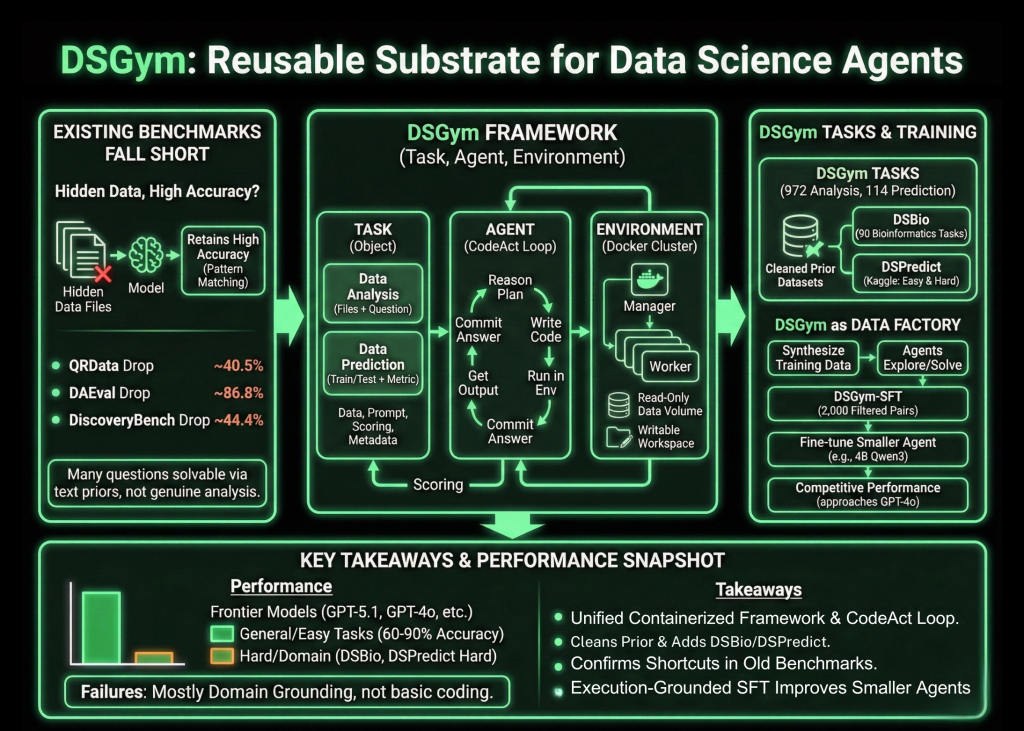
为什么现有的基准测试不够用?
研究团队首先调查了现有的基准测试,这些基准测试声称要测试数据感知代理。当数据文件被隐藏时,模型仍然保持了很高的准确性。在QRData上平均下降了40.5%,在DAEval上是86.8%,在DiscoveryBench上是44.4%。许多问题可以通过对文本进行先验和模式匹配来解决,而不必进行真正的数据分析,他们也发现了注释错误和不一致的数值容忍度。
任务、代理和环境
DSGym将评估标准化为三个对象:任务、代理和环境。任务要么是数据分析,要么是数据预测。数据分析任务提供一个或多个文件,以及一个必须通过代码回答的自然语言问题。数据预测任务提供训练和测试分割以及一个明确的度量,并要求代理构建建模管道并输出预测。
每个任务都打包到一个任务对象中,该对象包含数据文件、查询提示、评分函数和元数据。代理通过CodeAct风格的循环进行交互。在每个回合,代理写入一个描述其计划的推理块,一个在环境中运行的代码块,以及准备好提交时的问题块。环境作为Docker容器的管理器和工人集群实现,其中每个工人将数据作为只读卷挂载,提供一个可写入的工作空间,并附带特定领域的Python库。
DSGym任务、DSBio和DSPredict
在此运行时之上,DSGym任务聚集和精炼现有的数据集,并添加新的数据集。研究团队通过对QRData、DAEval、DABStep、MLEBench Lite等进行清洁,删除不可计分的项,并应用一个快捷过滤,该过滤移除了没有数据访问就容易被多个模型解决的问题。
为了涵盖科学发现,他们引入了DSBio,这是一个由同行评议论文和开源数据集派生出的90个生物信息学任务集合。任务涵盖了单细胞分析、空间和多组学、以及人类遗传学,并通过专家参考笔记支持确定性数值或分类答案。
DSPredict针对对真实Kaggle比赛中的建模。一个网络爬虫收集接受CSV提交并满足大小和清晰规则的最近比赛。预处理后,该套件分为DSPredict Easy,其中包括38个游乐场风格和入门级比赛,以及DSPredict Hard,其中包括54个高复杂性挑战。总共,DSGym任务包括972个数据分析任务和114个预测任务。
当前代理能做什么和不能做什么
评估涵盖了闭源模型,如GPT-5.1、GPT-5和GPT-4o,以及开源模型,如Qwen3-Coder-480B、Qwen3-235B-Instruct和GPT-OSS-120B,还有较小的模型,如Qwen2.5-7B-Instruct和Qwen3-4B-Instruct。所有这些都是在相同的CodeAct代理、温度0和无工具的情况下运行的。
在清洁的一般分析基准测试上,如QRData Verified、DAEval Verified和DABStep的更容易分割,顶级模型达到60%至90%的精确匹配准确率。在DABStep Hard上,每个模型的准确率都有所下降,这表明在财务表上的多步骤定量推理仍然很脆弱。
DSBio暴露了更加严重的弱点。Kimi-K2-Instruct实现了最佳的总体准确率,为43.33%。对于所有模型,85%至96%的DSBio失败检查是领域定位错误,包括滥用专用库和不当的生物解释,而不是基本的编码错误。
在MLEBench Lite和DSPredict Easy上,大多数前沿模型实现了接近完美的有效提交率,超过80%。在DSPredict Hard上,有效提交很少超过70%,Kaggle排行榜上的奖牌率近0%。这种模式支持研究团队的观察,即代理在基本解决方案后停止,而不是探索更具有竞争力的模型和超参数,这表明存在一种简单偏见。
DSGym作为数据工厂和训练场
相同的环境还可以合成训练数据。从QRData和DABStep的一个子集开始,研究团队要求代理探索数据集,提出问题,用代码解决问题,并记录轨迹,这产生了3700个合成的查询。法官模型过滤这些,得到了2000个高质量的查询加轨迹对,称为DSGym-SFT,即通过在DSGym-SFT上微调一个4B Qwen3模型,产生了一个代理,该代理在标准分析基准测试中达到与GPT-4o具有竞争力的性能,尽管它的参数要少得多。
来源:marktechpost.com
主要结论
- DSGym提供了一套统一的任务、代理和环境框架,具有容器化执行和CodeAct风格的循环,用于评估基于真实代码工作流的科学数据代理,而不是静态提示。
- 基准测试套件DSGym-Tasks整合和清除了以前的数据集,并添加了DSBio和DSPredict,涵盖了金融、生物信息学、地球科学等领域的972个数据分析任务和114个预测任务。
- 现有基准测试的快速分析法表明,在许多情况下,仅删除数据访问只能适度降低准确率,这证实了以前的评估通常衡量的是文本上的模式匹配,而不是真正的数据分析。
- 前沿模型在清洁的一般分析任务和较简单的预测任务上表现出色,但在DSBio和DSPredict-Hard上表现较差,其中大多数错误来自领域定位问题和保守的、欠调的建模管道。
- 由2000个过滤后的合成轨迹构建的DSGym-SFT数据集,使基于4B Qwen3的代理在某些分析基准测试上接近GPT-4o级别的准确率,这表明在结构化任务上的执行级别的监督是一种有效提高数据科学代理的方法。
相关文章







