AI2发布SERA,仅使用监督训练构建的软验证编码代理,用于实际的仓库级自动化工作流程。
艾伦人工智能研究所(AI2)研究人员介绍了SERA(软验证高效存储库代理),这是一个以仅使用监督培训和合成轨迹匹配更大封闭系统的代码代理家族。
什么是SERA?
SERA是AI2开放编码代理系列的首个发布。旗舰模型SERA-32B基于Qwen 3 32B架构,作为存储库级别的代码代理进行训练。
在32K上下文的SWE bench 验证中,SERA-32B达到49.5%的解决率。在64K的情况下,达到54.2%。这些数字使其与24B参数的Devstral-Small-2和110B参数的GLM-4.5 Air等开放权重系统处于同一性能级别,而SERA在代码、数据和权重方面保持完全开放。
该系列目前包括四个模型,SERA-8B、SERA-8B GA、SERA-32B和SERA-32B GA。所有这些模型都在Hugging Face上以Apache 2.0许可证发布。
软验证生成
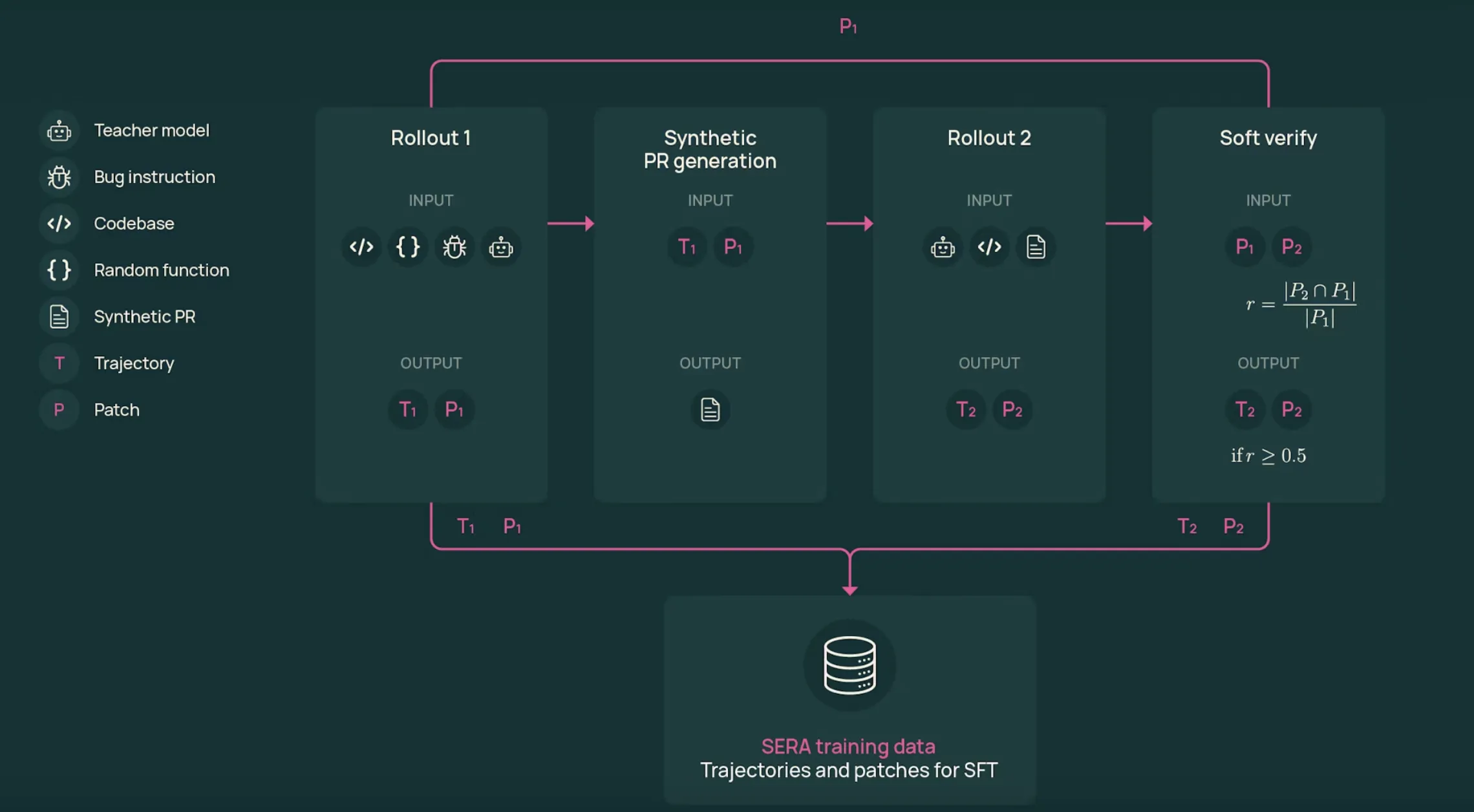
训练流程依赖于软验证生成(SVG)。SVG产生看起来像现实开发者工作流程的代理轨迹,然后使用两个卷动之间的补丁一致性作为正确性的软信号。
过程如下:
- 首次卷动:从真实存储库中采样一个函数。在SERA-32B设置中,教师模型GLM-4.6接收一个错误风格或更改描述,并使用工具查看文件、编辑代码和运行命令。它生成轨迹T1和补丁P1。
- 合成的请求:系统将轨迹转换为类似实际拉取请求的描述。这段文本总结了意图和关键编辑,格式类似于真实的拉取请求。
- 第二次卷动:教师再次从原始存储库开始,但现在它只看到拉取请求描述和工具。它生成一个新的轨迹T2和补丁P2,试图实现所描述的更改。
- 软验证:比较补丁P1和P2的每一行。计算召回率r,作为P1中修改行出现在P2中的比例。当r等于1时,轨迹是硬验证。对于中间值,样本是软验证。
消融实验的关键结果是,不需要严格的验证。当模型在不同的r阈值上对T2轨迹进行训练时,即使在r等于0的情况下,SWE bench 验证时的性能在固定的样本数下也相似。这表明,即使是带噪声的现实多步骤轨迹,对代码代理来说也是宝贵的监督。
{kind=link}
https://allenai.org/blog/open-coding-agents
数据规模、培训和成本
SVG应用于从SWE-smith语料库派生的121个Python存储库。在GLM-4.5 Air和GLM-4.6教师运行中,完整的SERA数据集包含来自两个卷动的超过20万个轨迹,使其成为最大的开放编码代理数据集之一。
SERA-32B通过在Qwen-3 -32B上的3个epoch、学习率1e-5、权重衰减0.01和最大序列长度32,768个令牌上进行标准的监督微调,在Sera-4.6-Lite T2数据集的25,000个T2轨迹子集上进行了训练。
许多轨迹的长度超过了上下文限制。研究团队定义了一个截断比例,即适应到32K令牌的步骤比例。然后,他们优先选择已适合的轨迹,对于剩余的轨迹,他们选择高截断比的片段。这种有序截断策略在比较SWE bench 验证分数时明显优于随机截断。
报告的SERA-32B计算预算,包括数据生成和培训,约为40个GPU天。利用数据集大小和性能的缩放定律,研究团队估计SVG方法比基于强化学习(例如SkyRL-Agent)的系统便宜约26倍,比早期合成数据管道(例如SWE-smith)便宜约57倍,以达到类似的SWE-bench分数。
{kind=link}
https://allenai.org/blog/open-coding-agents
存储库专业化
一个主要用例是将代理调整为特定存储库。研究团队在三个主要的SWE-bench 验证项目Django、SymPy和Sphinx上研究了这一点。
对于每个存储库,SVG产生大约46,000到54,000个轨迹。由于计算限制,专业化实验在每个存储库上训练8,000个轨迹,将3,000个软验证的T2轨迹与5,000个筛选的T1轨迹混合。
在32K上下文中,这些专业学生与GLM-4.5-Air教师相匹配或略有超出,并在那些存储库子集上很好地与Devstral-Small-2相比。对于Django,一个专业学生达到52.23%的解决率,而GLM-4.5-Air为51.20%。对于SymPy,专业模型达到51.11%,而GLM-4.5-Air为48.89%。
关键要点
- SERA将编码代理转化为一个监督学习问题:SERA-32B使用标准监督微调从GLM-4.6的合成轨迹进行训练,没有强化学习循环,不依赖于存储库测试套件。
- 软验证生成消除了测试的需求:SVG使用两个卷动和P1和P2之间的补丁重叠来计算软验证得分,研究团队表明,即使未经证明或弱验证的轨迹也可以训练有效的编码代理。
- 来自真实存储库的大型真实代理数据集:该管道将SVG应用于从SWE(程序)smih语料库派生的121个Python项目,产生了200,000多个轨迹,为编码代理创建了一个最大的开放数据集。
- 高效的培训具有明确的成本和缩放分析:SERA-32B在25,000个T2轨迹上进行了训练,缩放研究表明,在类似的SWE bench 验证性能下,SVG比SkyRL-Agent便宜26倍,比SWE-smith便宜57倍。
查看论文, Repo和模型权重。此外,欢迎您Twitter上关注我们,并别忘了加入我们的100k+ ML SubReddit和订阅我们的Newsletter。等等!你在Telegram上吗?现在你可以加入我们的Telegram群组。
文章AI2 发布 SERA,仅用监督训练构建的软验证编码代理,用于实际存储库级别的自动化工作流首次发布在MarkTechPost。
相关文章







