DeepSeek AI发布DeepSeek-OCR 2,配备因果视觉流程编码器,用于布局感知的文档理解。
DeepSeek AI发布了DeepSeek-OCR 2,这是一个开源的文档OCR和理解系统,其视觉编码器结构被重构为按照接近人类查看复杂文档的方式的因果顺序读取页面。其关键组件是DeepEncoder V2,这是一种类似于语言模型的Transformer,它将2D页面转换为1D的视觉令牌序列,在文本解码开始前,这些令牌序列已经遵循了学习到的阅读流程。
https://github.com/deepseek-ai/DeepSeek-OCR-2
从光栅顺序到因果视觉流
大多数多模态模型仍然将图像平坦化为从左上角到底右角的固定光栅序列,并应用具有静态位置编码的Transformer。这对拥有多列布局、嵌套表格和混合语言区域的文档来说是不匹配的。相反,人类读者遵循一种语义顺序,在不同区域之间跳跃。
DeepSeek-OCR 2保留了DeepSeek-OCR的编码器和解码器结构,但用DeepEncoder V2取代了原始的基于CLIP ViT的视觉编码器。解码器仍然是DeepSeek-3B-A500M,这是一个具有约30亿总参数和每个令牌约5亿活跃参数的MoE语言模型。目标是让编码器在对视觉令牌进行因果推理,并将序列传递给解码器,该序列已经与可能的阅读顺序对齐。
视觉分词器和令牌预算
视觉分词器是从DeepSeek-OCR继承而来的。它使用80M参数的SAM基骨干网络,接着是2个卷积层。这一阶段将图像下采样,使视觉令牌计数减少16倍,并将特性压缩到896维的嵌入维度。
DeepSeek-OCR 2使用全局和局部多裁剪策略来覆盖密集页面,同时不让令牌计数爆炸。在1024×1024分辨率的整体视图中产生256个令牌。最高可达6个768×768分辨率的局部裁剪,每个裁剪增加144个令牌。因此,每页的视觉令牌计数在256到1120之间。这个上限略低于原始DeepSeek-OCR的Gundam模式中使用的1156令牌预算,并且与OmniDocBench上Gemini-3 Pro使用的预算相当。
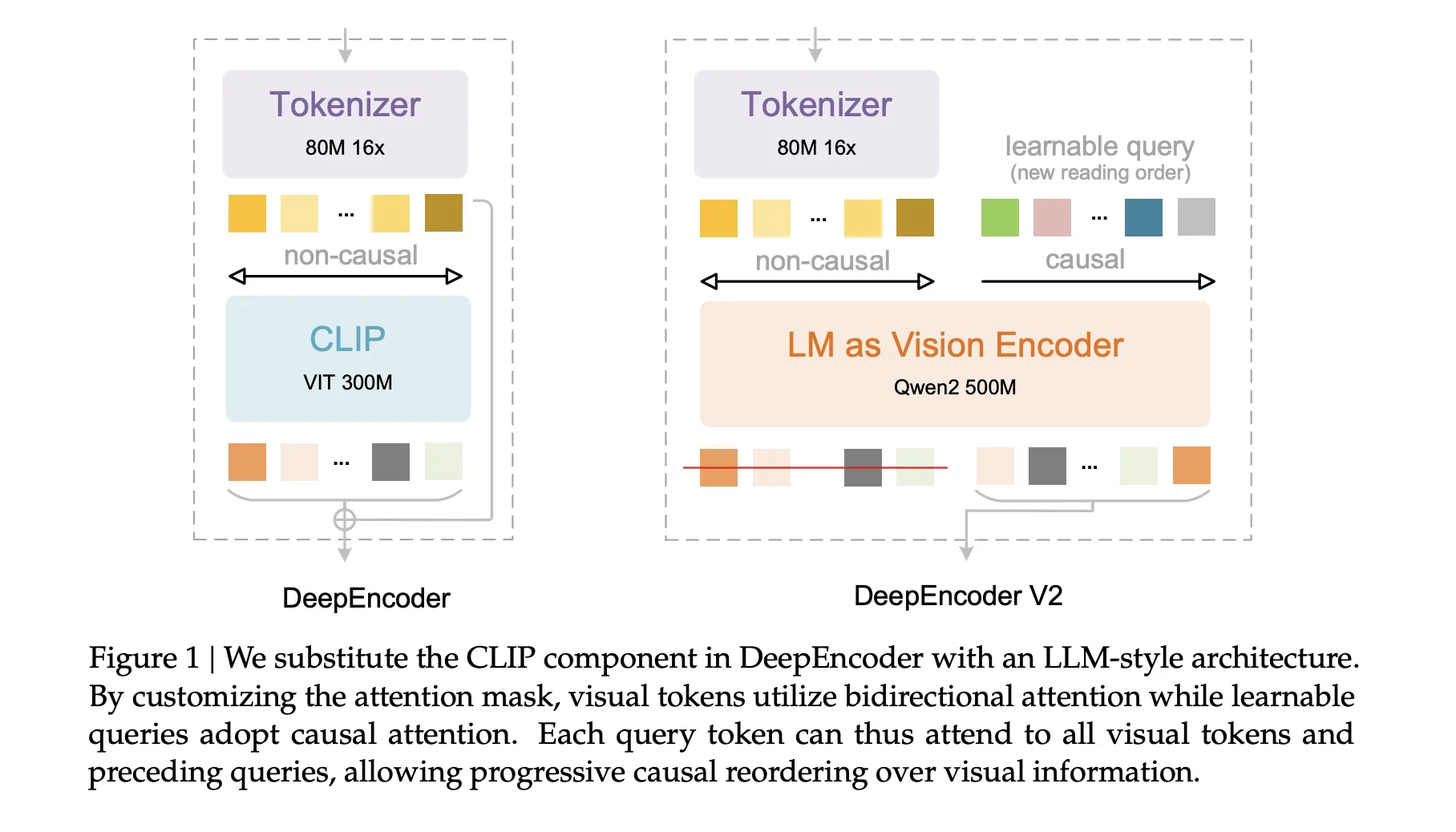
DeepEncoder-V2,语言模型作为视觉编码器
DeepEncoder-V2通过实例化一个Qwen2-0.5B风格的Transformer作为视觉编码器来构建。输入序列如下构建。首先,分词器中的所有视觉令牌形成前缀。然后附加一组可学习的查询令牌,称为因果流令牌,作为后缀。因果流令牌的数量等于视觉令牌的数量。
注意力模式是非对称的。视觉令牌使用双向注意力,可以看到所有其他视觉令牌。因果流令牌使用因果注意力,可以看到所有视觉令牌和只看到之前的因果流令牌。只有因果流位置的输出传递给解码器。实际上,编码器学习将2D视觉令牌网格映射到1D因果序列流令牌的映射,该序列流令牌编码了提议的阅读顺序和局部上下文。
这种设计将问题分解为2个阶段。DeepEncoder-V2对视觉结构和阅读顺序进行因果推理。然后DeepSeek-3B-A500M对重新排序的视觉输入进行因果编码。

https://github.com/deepseek-ai/DeepSeek-OCR-2
训练流水线
训练数据流水线遵循DeepSeek-OCR,并侧重于OCR密集型内容。OCR数据占混合物的80%。研究团队使用3:1:1的比例重新平衡跨文本、公式和表的抽样,以便模型看到足够的结构繁重的示例。
训练分为3个阶段:
在第1阶段,编码器预训练将DeepEncoder-V2与一个小型的解码器配对,并使用标准语言建模目标进行训练。模型在768×768和1024×1024分辨率下进行训练,采用多尺度采样。视觉分词器从原始DeepEncoder初始化。LLM风格的编码器从Qwen2-0.5B基初始化。优化器是AdamW,在40k个迭代中从1e-4衰减到1e-6。训练使用大约160个A100 GPU,序列长度为8k,并使用大量文档图像文本样本。
在第2阶段,查询增强将DeepEncoder-V2连接到DeepSeek-3B-A500M,并引入多裁剪视图。分词器被冻结。编码器和解码器使用4阶段流水线并行性和40个数据并行副本联合训练。全局批量大小为1280,计划运行15k次迭代,学习率从5e-5衰减到1e-6。
在第3阶段,冻结所有编码器参数。仅训练DeepSeek解码器以更好地适应重新排序的视觉令牌。这个阶段使用相同的批量大小,但计划较短,学习率从1e-6衰减到5e-8,在20k次迭代中。在此阶段,冻结编码器将训练吞吐量加倍以上。
OmniDocBench上的基准结果
主要的评估使用OmniDocBench-v1.5。该基准包含中英文9个文档类别中的1355页,包括书籍、学术论文、表格、演示文稿和报纸。每个页面都注解了布局元素,如文本跨度、方程、表格和图形。
DeepSeek-OCR 2在最大视觉令牌为1120的情况下实现总体OmniDocBench得分为91.09。原始DeepSeek-OCR基线得分87.36,最大令牌为1156。因此,DeepSeek-OCR 2提高了3.73分,同时使用略微较小的令牌预算。
阅读顺序(R-order)编辑距离,衡量预测和地面真实阅读序列之间的差异,从0.085下降到0.057。文本编辑距离从0.073下降到0.048。公式和表格编辑距离也下降,这表明对数学和结构区域的解析更好。
作为一个文档解析器,DeepSeek-OCR-2在元素级别编辑距离方面达到总体0.100。原始DeepSeek-OCR在类似的视觉令牌预算下达到0.129,Gemini-3 Pro达到0.115。这表明因果视觉流编码器在没有扩大令牌预算的情况下改善了结构保真度。
在类别方面,DeepSeek-OCR 2提高了大多数文档类型的文本编辑距离,例如学术论文和书籍。在非常密集的报纸上性能较弱,其中文本编辑距离仍然高于0.13。研究团队将这归因于报纸有限的训练数据和极端文本密度时的严重压缩。然而,所有类别的阅读顺序指标都有所改善。

https://github.com/deepseek-ai/DeepSeek-OCR-2
关键要点
- DeepSeek-OCR 2用基于Qwen2-0.5B的语言模型编码器DeepEncoder-V2取代了CLIP ViT风格的编码器,该编码器将2D文档页面转换为1D的因果流令牌序列,这些序列与学习到的阅读顺序对齐。
- 视觉分词器使用80M参数的SAM基骨干网络与卷积,多裁剪全局和局部视图,每页的视觉令牌预算保持在256到1120个令牌之间,略低于原始DeepSeek-OCR的Gundam模式,同时与Gemini 3 Pro相当。
- 训练遵循3个阶段,即编码器预训练、与DeepSeek-3B-A500M的联合查询增强以及冻结编码器的情况下仅对解码器进行微调,使用OCR密集型数据组合,其中包含80%的OCR数据,以及文本、公式和表格的3:1:1抽样比例。
- 在包含1355页和9个文档类别的OmniDocBench v1.5上,DeepSeek-OCR 2实现总体得分为91.09,而DeepSeek-OCR的得分为87.36,将阅读顺序编辑距离从0.085降低到0.057,并在类似的视觉令牌预算下,与DeepSeek-OCR的0.129和Gemini-3 Pro的0.115相比,实现了元素级别编辑距离0.100。
查看[论文](https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek%5FOCR2%5Fpaper.pdf)、[代码库](https://github.com/deepseek-ai/DeepSeek-OCR-2)和模型权重。您也可以关注我们的Twitter,并加入我们的100k+ ML SubReddit。别忘了订阅我们的Newsletter。等一下!你在telegram上吗?现在您也可以加入我们。
文章DeepSeek AI发布DeepSeek-OCR 2,具有因果视觉流编码器的布局感知文档理解首先出现在MarkTechPost。
相关文章







