艾伦人工智能研究所(AI2)推出Olmo 3:基于Dolma 3和Dolci栈的开源7B和32B语言模型家族
艾伦人工智能研究所(AI2)正在推出Olmo 3作为一个完全开放的模型系列,该系列揭示了整个“模型流程”,从原始数据和代码到中间检查点和部署准备变体。
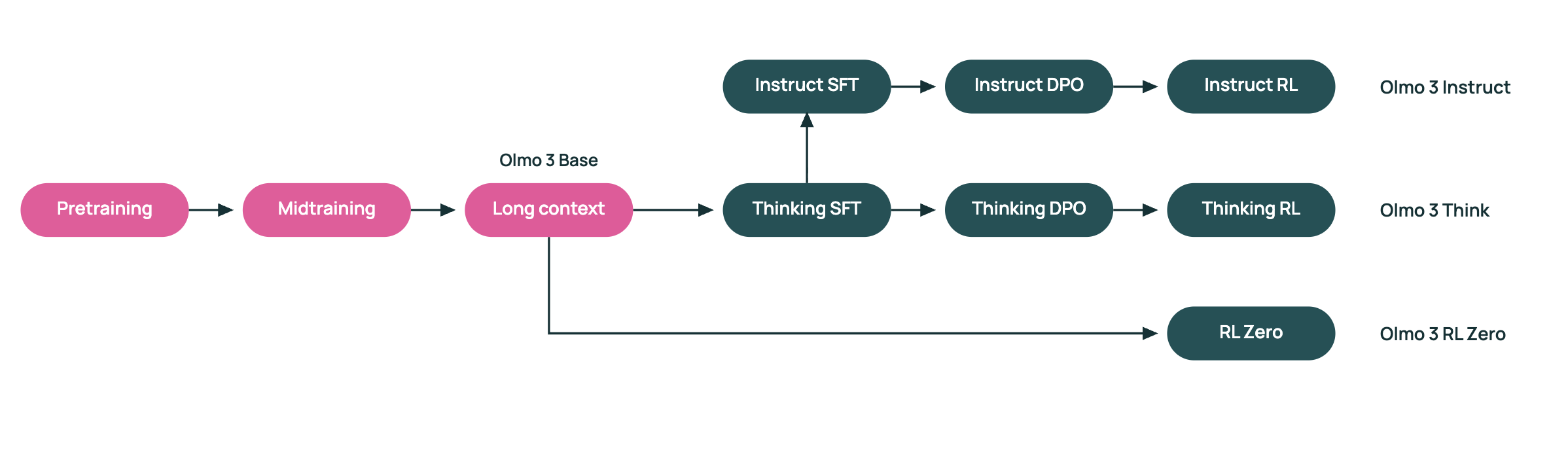
Olmo 3是一个包含7B和32B参数模型的密集型transformer套件。该系列包括Olmo 3-Base、Olmo 3-Think、Olmo 3-Instruct和Olmo 3-RL Zero。7B和32B版本都具有65,536个标记的上下文长度且使用相同的分阶段训练食谱。
https://allenai.org/blog/olmo3
Dolma 3数据套件
训练流程的核心中是Dolma 3,它是为Olmo 3设计的一种新的数据收集。Dolma 3由Dolma 3 Mix、Dolma 3 Dolmino Mix和Dolma 3 Longmino Mix组成。Dolma 3 Mix是一个包含5.9T个标记的预训练数据集,主要包括网络文本、科学PDF文档、代码存储库和其他自然数据。Dolmino和Longmino子集是从此池中筛选出更高品质的切片构建而成。
Dolma 3 Mix支持Olmo 3-Base的主要预训练阶段。AI2研究团队随后应用Dolma 3 Dolmino Mix,这是一个100B个标记的中训练集,强调数学、代码、指令遵循、阅读理解和以思考为导向的任务。最后,Dolma 3 Longmino Mix增加了50B个标记用于7B模型,以及100B个标记用于32B模型,重点是使用olmOCR流程处理的长文档和科学PDF文档。这种分阶段课程推动了上下文限制至65,536个标记,同时保持了稳定性和质量。
在H100集群上的大规模训练
Olmo 3-Base 7B使用1,024个H100设备在Dolma 3 Mix上训练,每个设备每秒达到约7,700个标记。后来的阶段使用128个H100进行Dolmino中训练,使用256个H100进行Longmino长上下文扩展。
基准测试中的基础模型性能与开放家族的对比
在标准能力基准测试中,Olmo 3-Base 32B被定位为领先的全开放基础模型。AI2研究团队报告称,它在与Qwen 2.5和Gemma 3等著名开放权重家族在相似规模的情况下竞争力相当。在广泛的任务集上进行对比,Olmo 3-Base 32B在排名上接近或高于这些模型,同时保持全部数据和处理配置公开以供检查和重用。
专注于推理的Olmo 3 Think
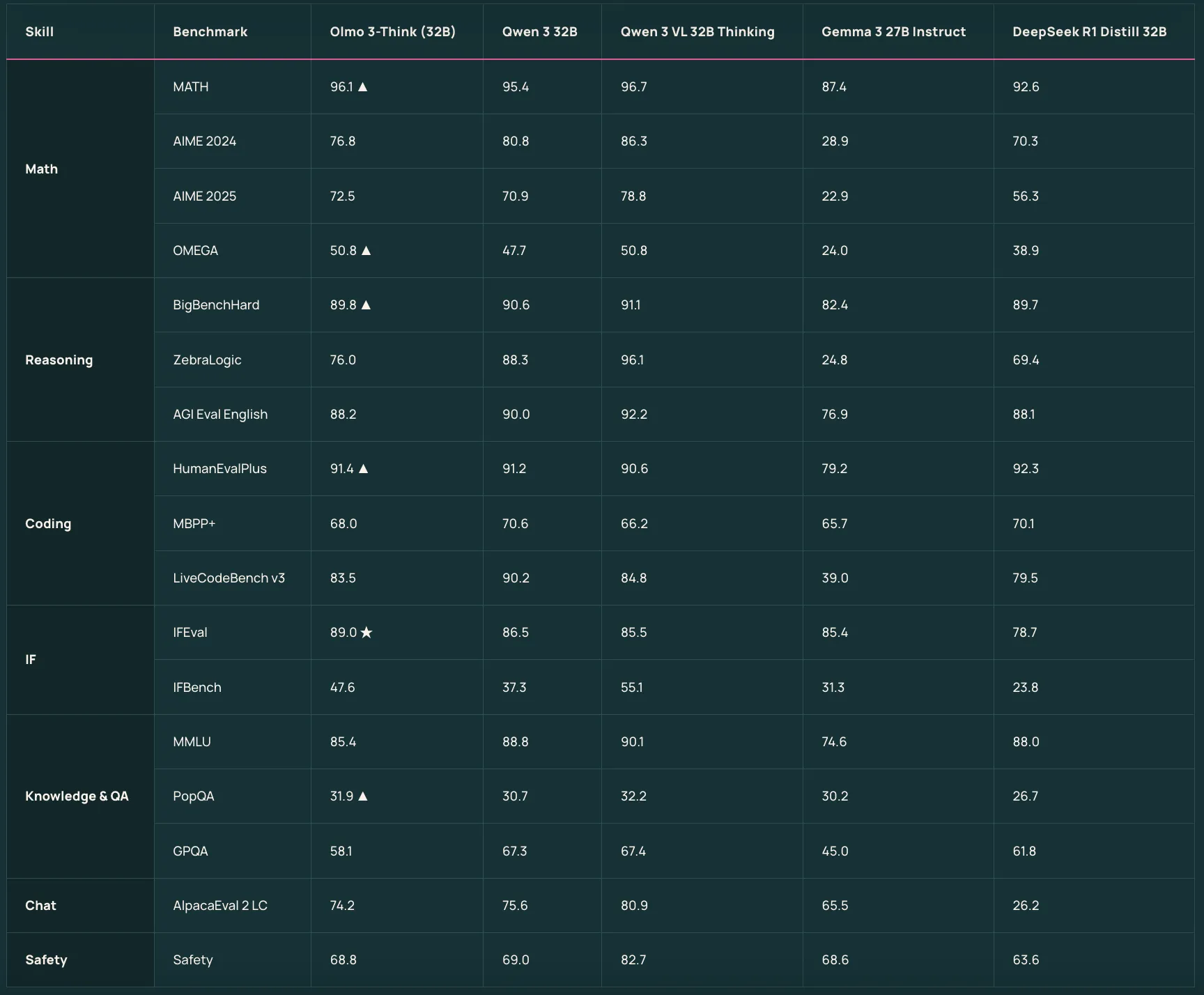
Olmo 3-Think 7B和Olmo 3-Think 32B是建立在基础模型之上的推理 focused版本。它们使用一个三阶段的后训练食谱,包括在OlmoRL框架内的监督微调、直接偏好优化和可验证奖励下的强化学习。Olmo 3-Think 32B被描述为最强全开放推理模型,在培训标记量约为六倍少的情况下缩小了与Qwen 3 32B推理模型之间的差距。
https://allenai.org/blog/olmo3
Olmo 3 Instruct用于聊天和工具使用
Olmo 3-Instruct 7B针对快速指令遵循、多轮聊天和工具使用进行了调整。它从Olmo 3-Base 7B开始,并应用了一个单独的Dolci Instruct数据集和训练流程,涵盖监督微调、DPO和对话和功能调用工作的RLVR。
AI2研究团队报告称,Olmo 3-Instruct与Qwen 2.5、Gemma 3和Llama 3.1等开放权重竞争对手相当,在相似的指令和推理基准上与Qwen 3家族竞争力。
RL Zero用于清洁RL研究
Olmo 3-RL Zero 7B是专为那些关心在语言模型上进化和学习强化学习但需要预处理数据和RL数据之间有清晰分离的研究人员设计的。它在Olmo 3-Base之上构建为一个完全开放的RL路径,并使用了Dolci RL Zero数据集,这些集已经被Dolma 3净化。
比较表格
| 模型变体 | 训练或后训练数据 | 主要用例 | 报告的与其他开放模型的相对位置 |
|---|---|---|---|
| Olmo 3 Base 7B | Dolma 3 Mix预训练、Dolma 3 Dolmino Mix中训练、Dolma 3 Longmino Mix长上下文 | 通用基础模型、长上下文推理、代码、数学 | 强全开放7B基础,为Think、Instruct、RL Zero设计,作为基础,对其他领先的7B规模基础进行评估 |
| Olmo 3 Base 32B | 与7B相同的Dolma 3分阶段管道,100B Longmino标记用于长上下文 | 高端基础模型,研究、长上下文工作负荷、RL设置 | 被描述为最佳的完全开放32B基础,与Qwen 2.5 32B和Gemma 3 27B相当,并优于Marin、Apertus、LLM360 |
| Olmo 3 Think 7B | Olmo 3 Base 7B, plus Dolci Think SFT、Dolci Think DPO、Dolci Think RL在OlmoRL框架内 | 专注于推理的7B模型,有内部思维痕迹 | 全开放推理模型在高效规模上,使思维链研究成为可能,在中等硬件上能够进行强化学习实验 |
| Olmo 3 Think 32B | Olmo 3 Base 32B, plus Dolci Think SFT、DPO、RL管道 | 标志性的推理模型,有长思维痕迹 | 被称为最强的完全开放推理模型,与Qwen 3 32B推理模型相当,而使用大约六倍少的训练标记量 |
| Olmo 3 Instruct 7B | Olmo 3 Base 7B, plus Dolci Instruct SFT、Dolci Instruct DPO、Dolci Instruct RL 7B | 指令遵循、聊天、功能调用、工具使用 | 报告称,在相似的指令和推理基准上,与Qwen 2.5、Gemma 3、Llama 3相比,与Qwen 3家族相当 |
| Olmo 3 RL Zero 7B | Olmo 3 Base 7B, plus Dolci RLZero Math、Code、IF、Mix数据集,被Dolma 3净化 | RLVR研究,数学、代码、指令遵循、混合任务 | 作为基于基础模型的完全开放RLVR路径引入,其预处理数据已被净化 |
主要发现
- 端到端透明流程:Olmo 3展示了从Dolma 3数据构建、分阶段预训练和后训练,到发布的检查点、评估工具等的整个“模型流程”,这使全文语言模型研究成为可能,并允许进行细微的调试。
- 密集的7B和32B模型与65K上下文:该系列包括7B和32B密集型transformer模型,所有模型都具有65,536个标识符的上下文窗口,通过三阶段的Dolma 3课程培训,Dolma 3 Mix主要用于主要预训练,Dolma 3 Dolmino用于中训练,Dolma 3 Longmino用于长上下文扩展。
- 强开放的基模型和推理模型:Olmo 3 Base 32B在中规模上被定位为最佳的全开放基础模型,与Qwen 2.5和Gemma 3相当,而Olmo 3 Think 32B被认为是 strongest 的完全开放推理模型,在训练标记量约为六倍少的情况下缩小了与Qwen 3 32B推理模型之间的差距。
- 针对任务调整的Instruct和RL Zero版本:Olmo 3 Instruct 7B针对指令遵循、多轮聊天和工具使用,使用Dolci Instruct SFT、DPO和RLVR工作负载中的RLVR数据,并报告称在相似的规模基准上匹配或超过了Qwen 2.5、Gemma 3和Llama 3.1。Olmo 3 RL Zero 7B提供了一条完全开放的RLVR路径,其Dolci RLZero数据集已被Dolma 3净化。
编辑评论
Olmo 3是一个不同寻常的发布,因为它在完整堆栈上实现了全开放性,包括Dolma 3数据配方、分阶段预训练、Dolci后训练、OlmoRL中的RLVR,以及与OLMES和OlmoBaseEval的评估。这降低了数据质量、长上下文训练和以推理为导向的RL之间的歧义,并为在控制实验中扩展Olmo 3 Base、Olmo 3 Think、Olmo 3 Instruct和Olmo 3 RL Zero提供了一个具体的基线。总体而言,Olmo 3为透明和高质量的LLM流程设置了严谨的参考点。
查看技术细节。请随意查看我们的教程、代码和笔记本的GitHub页面。也可以在我们Twitter上关注我们,别忘了加入我们的100k+ 机器学习SubReddit并订阅我们的时事通讯。等!你在电报上吗?现在你可以在Telegram上加入我们了。
文章艾伦人工智能研究所(AI2)介绍Olmo 3:基于Dolma 3和Dolci堆栈的7B和32B开源LLM家族首次出现在MarkTechPost。
相关文章







