MBZUAI发布K2 Think V2:一个用于数学、代码和科学的完全自主的70B推理模型
K2 Think V2,是一款完全独立的推理模型,旨在评估开放和完全文档化的流程将数学、代码和科学领域长期推理推得有多远。当整个堆栈都是开放和可复制的时,K2 Think V2从70亿参数的K2 V2 Instruct基础模型出发,采用了精心设计的强化学习方法,将其转变为一个精确的推理模型,其在权重和数据上均保持完全开放。

https://arxiv.org/pdf/2512.06201
从K2 V2基础模型到推理专家
K2 V2是一个只有80层、隐藏大小为8192、包含64个注意力头且具有分组查询注意力和旋转位置嵌入的密集解码器变压器。它是在大约1200亿个从TxT360语料库和相关精心制作的数据集中抽取的标记上训练的,这些数据集包括网络文本、数学、代码、多语言数据和科学文献。
训练分为三个阶段。预训练在自然数据上以8192个标记的上下文长度进行,以建立稳健的一般知识。中期训练接着使用TxT360 Midas将上下文扩展到512k个标记,其中混合了长文档、合成思维轨迹和多样的推理行为,同时在每个阶段仔细保持至少30%的短上下文数据。最后,通过称为TxT360 3efforts的监督微调,注入指令遵循和结构化推理信号。
重要的是K2 V2不是一个通用的基础模型。它明确地优化了长期上下文的连续性和在中期训练中对推理行为的暴露。这使得它成为专注于推理质量的后训练阶段的自然基础,这正是K2 Think V2所做的。
在GURU数据集上完全独立的RLVR
K2 Think V2在K2 V2 Instruct之上使用一种GRPO风格的RLVR配方进行训练。团队使用了版本1.5的Guru数据集,该数据集专注于数学、代码和STEM问题。Guru源于许可来源,扩大了STEM范围,并在使用前对抗关键评估基准进行去毒。这对于主权声明很重要,因为基础模型数据和RL数据都由同一研究所精心制作和记录。
GRPO设置去除了常见的KL和熵辅助损失,并使用策略比率的非对称剪裁,高剪裁设置为0.28。训练以全策略进行,温度为1.2,以增加滚出的多样性,全局批量大小为256,没有微批量。这避免了引入不稳定性的离策略更正,这在GRPO类似训练中是已知的。
RLVR本身运行在两个阶段。在第一阶段,响应长度限制在32k个标记,模型训练约200步。在第二阶段,最大响应长度增加到64k个标记,以相同的超参数继续训练约50步。该时间表特别利用了从K2 V2继承的长期上下文能力,以便模型可以练习完整的思考轨迹,而不是短解决方案。
https://mbzuai.ac.ae/news/k2-think-v2-a-fully-sovereign-reasoning-model/
基准配置文件
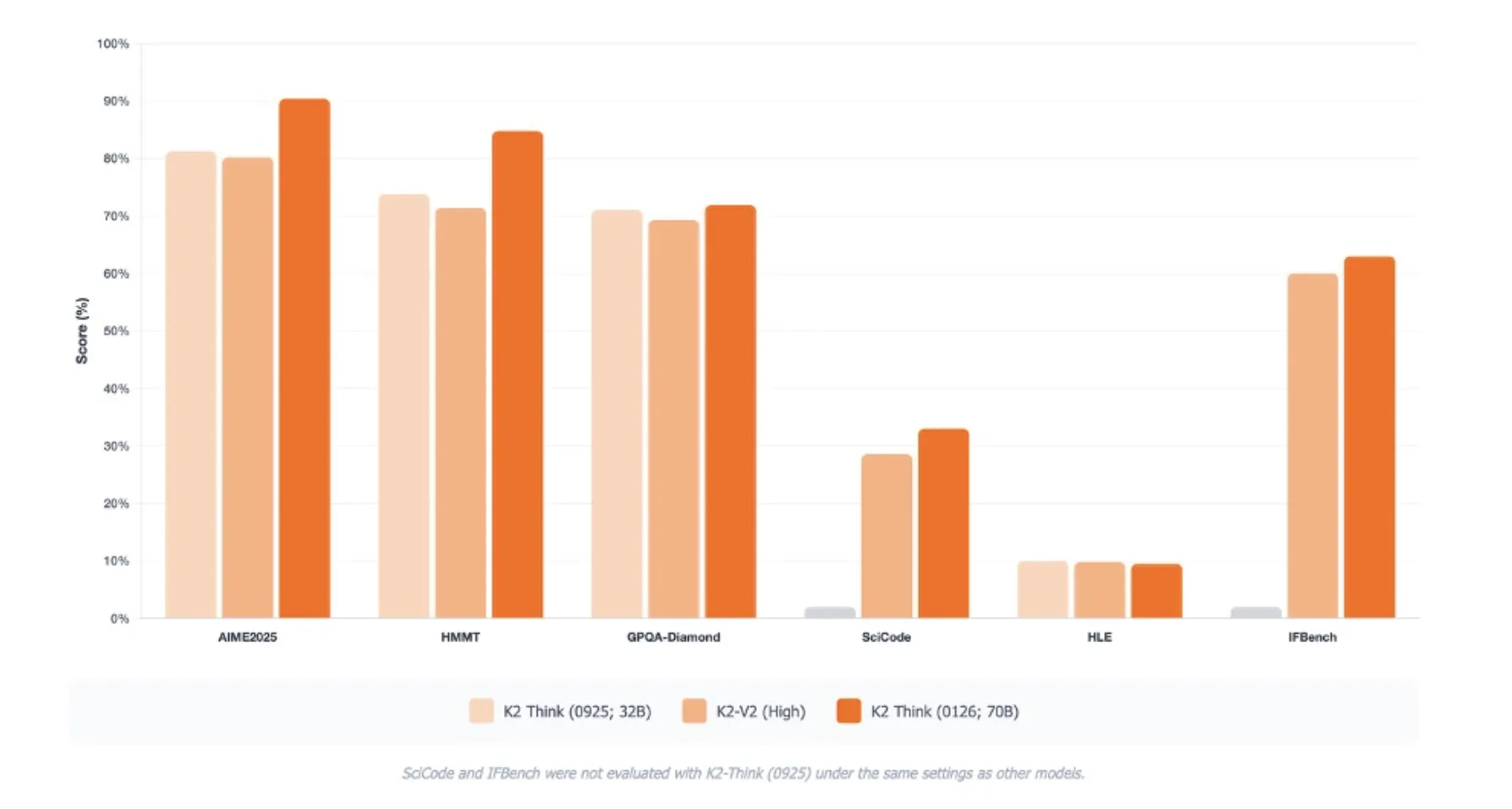
K2 Think V2针对推理基准,而不是纯粹的知识基准。在AIME 2025上达到1的通过率为90.42。在HMMT 2025上得分为84.79。在GPQA Diamond上达到72.98(一个困难的硕士水平科学基准)。在SciCode上记录了33.00,在Humanity's Last Exam的基准设置下达到9.5。
这些分数是在16次运行中的平均值,仅在相同的评估协议下直接可比较。MBZUAI团队还强调了与上一个K2 Think版本相比,在IFBench和人工分析评估套件上的改进,尤其在幻觉率和长期推理方面。
安全和开放
研究小组报告了一种类似Safety 4的分析,它汇总了四个安全面。内容和公共安全、真实性と信赖性以及社会契合度均达到宏观平均风险水平的较低范围。数据和基础设施风险仍然较高,并被标记为关键,这反映了对于敏感个人信息处理的担忧,而不是仅仅关于模型行为。团队表示,尽管采取了这些缓解措施,K2 Think V2仍然拥有大型语言模型的普遍局限性。在人工分析的开放指数上,K2 Think V2与K2 V2和Olmo-3一起位于前沿。
关键要点
- K2 Think V2是一个完全独立的70B推理模型:基于K2 V2 Instruct构建,具有开放权重、开放数据食谱、详细的训练日志以及通过Reasoning360发布的完整RL流程。
- 基础模型在RL之前针对长期上下文和推理进行优化:K2 V2是一个处理约1200亿个标记的密集解码器变压器,中期训练将上下文长度扩展到512K,通过监督“3efforts”SFT针对结构化推理。
- 使用基于Guru数据集的GRPO RLVR进行推理对齐:训练使用在Guru v1.5上的两阶段全策略GRPO设置,采用非对称剪裁、温度1.2,响应限制在32K然后64K标记,以学习长链思考解决方案。
- 在困难的推理基准上取得有竞争力的成绩:K2 Think V2报告了诸如AIME 2025上1的90.42以及HMMT 2025上的84.79等强有力的通过率,将其定位为数学、代码和科学领域的精确开源推理模型。
查看论文、模型权重、代码库和技术细节。你也可以在Twitter上关注我们,并别忘了加入我们的10k+机器学习SubReddit,并订阅我们的时事通讯。等等!你还在telegram上吗?现在你也可以加入我们的telegram。
由MarkTechPost发布的帖子MBZUAI发布K2 Think V2:一款面向数学、代码和科学的完全独立的70B推理模型首先出现。
相关文章







